반응형
원문: https://arxiv.org/pdf/2408.14717
1. 자연어 질의 처리의 한계와 새로운 접근 필요성
- 기존의 Text2SQL과 RAG 방법은 사용자의 복잡한 자연어 질문을 처리하는 데 한계가 있다.
- 실제 사용자들은 도메인 지식, 세계 지식, 정확한 계산, 의미적 추론이 결합된 복잡한 질문을 하는 경향이 있다.
- 언어 모델(LM)은 텍스트 데이터에 대한 의미적 추론 능력을 제공하여 감성 분석이나 트렌드 요약과 같은 복잡한 작업을 수행할 수 있다.
- LM은 모델 학습 중 획득한 암묵적 세계 지식을 활용하여 데이터베이스 스키마에 명시적으로 포함되지 않은 정보를 보완할 수 있다.
- 데이터베이스와 LM의 장점을 효과적으로 결합한 새로운 시스템이 필요하며, 이는 사용자가 데이터를 이해하는 방식을 혁신할 잠재력이 있다.
2.TAG 모델의 3단계 프로세스
- TAG 모델은 쿼리 합성, 쿼리 실행, 답변 생성의 세 가지 핵심 단계로 구성된다.

- 쿼리 합성(syn) 단계에서는 사용자의 자연어 요청을 실행 가능한 데이터베이스 쿼리로 변환한다.
- 쿼리 실행(exec) 단계에서는 데이터베이스 시스템에서 쿼리를 효율적으로 실행하여 관련 데이터를 계산한다.
- 답변 생성(gen) 단계에서는 언어 모델을 활용하여 사용자의 요청과 계산된 데이터를 기반으로 최종 자연어 답변을 생성한다.
- TAG 모델은 Text2SQL과 RAG를 포함한 기존 방법들을 통합하며, 더 넓은 범위의 사용자 질문을 처리할 수 있다.
3. TAG 모델의 설계 공간과 연구 기회
- TAG 모델은 다양한 유형의 자연어 질의를 처리할 수 있으며, 데이터 집계 수준과 필요한 지식/능력에 따라 질의를 분류할 수 있다.
- 기본 데이터 모델은 관계형 데이터베이스부터 비정형 데이터(텍스트, 이미지, 비디오, 오디오)까지 다양한 형태를 취할 수 있다.
- 데이터베이스 실행 엔진과 API는 SQL 기반 쿼리 엔진, 벡터 임베딩 기반 검색 시스템, 의미 연산자를 활용한 시스템 등 다양한 옵션이 있다.
- LM 생성 패턴은 단일 LM 호출부터 반복적 또는 재귀적 생성 패턴까지 다양한 구현 결정을 통해 최종 자연어 답변을 생성할 수 있다.
- 테이블 인코딩, 프롬프트 압축, 프롬프트 튜닝 등의 하위 문제들이 연구되고 있으며, 추론 기반 변환을 포함한 질의 처리에 대한 연구도 진행 중이다.
4. TAG 모델의 평가 및 성능
- TAG 모델은 세계 지식이나 의미론적 추론이 필요한 복잡한 쿼리에서 기존 방법들보다 우수한 성능을 보인다.
- 평가를 위해 BIRD 벤치마크의 쿼리를 수정하여 80개의 새로운 쿼리로 구성된 TAG 벤치마크를 만들었다.
- 평가 지표로는 정확한 일치(exact match) 비율과 실행 시간을 사용했다.
- 실험 결과, 수작업으로 작성된 TAG 모델이 다른 기준 모델들에 비해 20-65% 더 높은 정확도를 보였다.
- TAG 모델은 정확도 향상뿐만 아니라 최대 3.1배 빠른 실행 시간을 달성하여 효율성도 입증했다.
4.1. TAG 벤치마크 소개 및 평가 방법론
- TAG 벤치마크는 의미적 추론이나 세계 지식을 요구하는 쿼리에 대한 기존 테이블 질의응답 방법의 성능을 평가한다.
- BIRD 벤치마크를 기반으로 하여, 데이터 소스에 직접 포함되지 않은 지식이나 의미적 추론이 필요한 쿼리로 수정했다.
- 벤치마크는 5개 도메인에서 80개의 수정된 쿼리로 구성되며, 40개는 매개변수적 지식을, 40개는 추론을 요구한다.
- 평가 지표로는 정확한 일치 비율을 사용하며, 집계 쿼리에 대해서는 정성적 분석을 수행한다.
- 실험에는 70B 파라미터의 Llama-3.1 모델과 SQLite3 데이터베이스 API를 사용한다.
4.2. TAG 평가를 위한 기준 방법론들
- Text2SQL 방식에서는 LM이 SQL 코드를 생성하고, 이를 실행하여 답변을 얻는다.
- RAG(Retrieval Augmented Generation) 방식은 행 단위 임베딩을 사용하여 관련 데이터를 검색하고, 이를 모델에 입력으로 제공한다.
- Retrieval+LM Rank 방식은 RAG를 확장하여 LM을 사용해 검색된 행들의 순위를 매긴다.
- Text2SQL+LM 방식은 먼저 SQL을 생성하여 관련 행을 검색한 후, 이를 모델에 제공하여 답변을 생성한다.
- Hand-written TAG 방식은 전문가의 스키마 지식을 활용하여 LOTUS API를 통해 선언적으로 쿼리 파이프라인을 구현한다.

4.3. 평가 결과: TAG의 우수한 성

- TAG 방식은 모든 쿼리 유형에서 40% 이상의 정확도를 보여주며, 다른 방법들이 20% 이하의 정확도를 나타내는 것과 대조적이다.
- Text2SQL 방식은 전반적으로 낮은 성능을 보이며, 특히 순위 쿼리에서 10%의 낮은 정확도를 나타낸다.
- RAG 방식은 모든 쿼리 유형에서 단 하나의 쿼리도 정확히 답변하지 못했으며, LM 재순위화를 추가해도 성능 향상이 미미했다.
- 수작업으로 작성된 TAG 기준선은 전체적으로 55%의 정확도를 보이며, 특히 비교 쿼리에서 65%의 높은 정확도를 달성했다.
- TAG 방식은 기존 방법들에 비해 20%에서 65%까지의 정확도 향상을 보여주어, 복잡한 자연어 쿼리 처리에 더 효과적임을 입증했다.
4.4. 기존 방법들의 한계와 TAG의 우수성
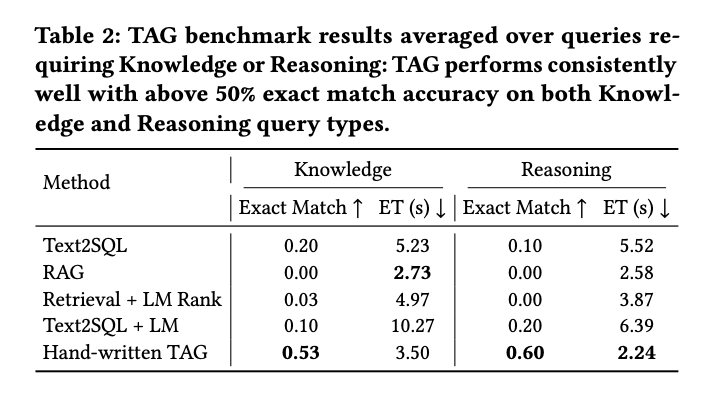
- Text2SQL은 LM 추론이 필요한 쿼리에서 10%의 정확도로 특히 취약한 성능을 보인다.
- RAG와 Retrieval + LM Rank 방식은 모든 쿼리 유형에서 어려움을 겪으며, 데이터에 대한 정확한 계산을 LM에 의존하기 때문에 단 하나의 쿼리만 정확히 답변했다.
- 반면 수작업으로 작성된 TAG 방식은 지식과 추론이 필요한 쿼리 모두에서 50% 이상의 정확도를 달성하여 TAG 모델의 다양성을 강조한다.
- TAG 방식은 높은 정확도뿐만 아니라 다른 방법들보다 최대 3.1배 빠른 실행 시간을 제공하며, 평균 2.94초의 실행 시간을 보인다.
- 집계 쿼리에 대한 정성적 분석 결과, TAG 시스템은 대량의 데이터를 성공적으로 집계하여 정보력 있는 답변을 제공할 잠재력을 보여준다.
4.5. TAG의 성능 및 비교 분석 결과
- TAG는 다른 방법들에 비해 정확도와 실행 시간 면에서 우수한 성능을 보여주며, 전체 쿼리에 대해 55%의 정확도와 2.94초의 실행 시간을 달성했다.
- 지식과 추론이 필요한 쿼리 유형에서도 TAG는 50% 이상의 정확도를 일관되게 유지했다.
- 비교, 순위 지정, 집계와 같은 복잡한 쿼리 유형에서도 TAG는 40-65%의 정확도를 보여주며 다른 방법들을 크게 앞섰다.
- TAG는 데이터베이스 작업과 언어 모델의 능력을 결합하여 구조화된 데이터와 비구조화된 정보를 모두 활용할 수 있는 장점이 있다.
- 향후 연구에서는 TAG를 에이전트 기반 데이터 어시스턴트로 확장하는 방향을 고려할 수 있다.
5. 연구 방법론 및 결과
- Table-Augmented Generation(TAG)는 데이터베이스에 대한 자연어 질문을 처리하기 위한 새로운 통합 모델로 제안되었다.
- 세계 지식과 의미론적 추론 능력이 필요한 두 가지 중요한 유형의 쿼리를 연구하기 위한 벤치마크가 개발되었다.
- 기준 방법들은 이러한 작업에서 의미 있는 진전을 이루지 못했지만, 수작업으로 작성된 TAG 파이프라인은 최대 65% 더 높은 정확도를 달성할 수 있음을 체계적인 평가를 통해 확인했다.
5.1. 테이블 증강 생성(TAG)의 소개와 의의
- 테이블 증강 생성(TAG)은 데이터베이스에 대한 자연어 질문에 답변하기 위한 통합 모델로 제안되었다.
- TAG는 데이터베이스 질의에 대한 기존 접근 방식의 한계를 극복하고자 개발되었다.
- 연구팀은 TAG의 성능을 평가하기 위해 중요한 두 가지 유형의 벤치마크를 개발했다.
- 이 접근 방식은 자연어 처리와 데이터베이스 기술을 결합하여 더 효과적인 질의 응답 시스템을 구축하는 것을 목표로 한다.
5.2. 쿼리 유형 및 기준 방법의 한계
- 쿼리는 세계 지식이 필요한 것과 의미론적 추론 능력이 필요한 것으로 구분된다.
- 체계적인 평가를 통해 기준 방법들의 한계가 확인되었다.
- 기존 방법들은 의미 있는 결과를 도출하는 데 어려움을 겪는 것으로 나타났다.
- 이러한 평가 결과는 현재 접근 방식의 개선 필요성을 시사한다.
5.3. 참고 문헌
- 참고 문헌 목록에는 AI와 데이터베이스 분야의 다양한 연구 논문과 기술 문서들이 포함되어 있다.
- 참고 문헌은 자연어 처리, 데이터베이스 쿼리, 대규모 언어 모델 등 다양한 주제를 다루고 있어 연구의 학제간 성격을 보여준다.
반응형




댓글