원문: https://arxiv.org/pdf/2503.05840
이 논문에서는 Transformer 모델의 Slim attention이라는 새로운 attention 메커니즘을 제안한다. Slim attention은 Multi-Head Attention (MHA)에서 context memory 크기를 절반으로 줄여 inference 속도를 향상시킨다. 핵심 아이디어는 value (V) projection을 key (K) projection으로부터 계산하여 KV-cache 크기를 줄이는 것이다. 이 방법은 수학적으로 동일하므로 모델 정확도를 손상시키지 않으며, 특히 긴 context를 처리하는 데 효율적이다. 또한, Slim attention은 encoder-decoder 구조에서 context memory를 더욱 줄일 수 있으며, RoPE와 같은 positional encoding 방식과도 호환된다. Slim attention은 다양한 Transformer 모델에 적용 가능하며, 메모리 효율성을 높여 모델 성능을 개선할 수 있습니다.
Slim Attention: MHA의 Context Memory 절감 기술
- Slim attention은 Transformer 모델의 Multi-Head Attention (MHA) 에서 context memory 크기를 절반으로 줄여 긴 context 처리 시 추론 속도를 최대 2배까지 향상시킬 수 있는 기술이다.
- 이 기술은 value (V) projection을 key (K) projection으로부터 계산하여 KV-cache 크기를 절반으로 줄이는 것이 핵심이다.
- Slim attention은 수학적으로 기존 attention 메커니즘과 동일하므로 모델의 정확도를 손상시키지 않는다.
- Encoder-decoder Transformer에서는 context memory를 더욱 줄일 수 있어, 예를 들어 Whisper 모델의 경우 context memory를 8배까지 줄일 수 있다.
- 이 기술은 CodeLlama, Aya, SmolLM2, LLaVA, Qwen2-Audio, Whisper, T5 등 다양한 MHA 기반 Transformer 모델에 적용 가능하다.
Slim Attention의 작동 원리와 구현 방식

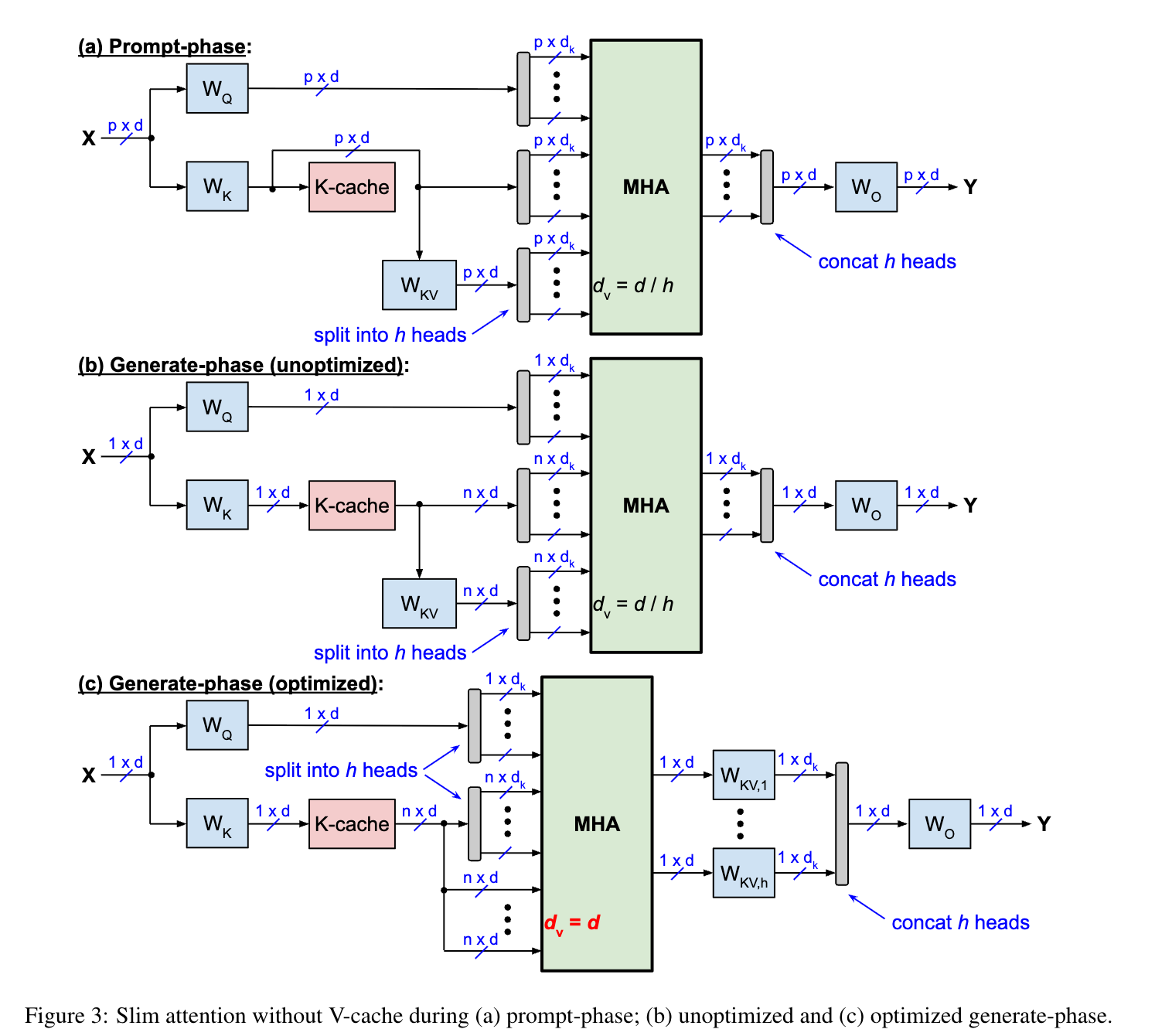
- Slim Attention은 Value(V) projection을 Key(K) projection으로부터 계산하여 KV-cache 크기를 절반으로 줄인다.
- Slim Attention의 계산은 두 가지 방식으로 가능하다.
1) 비최적화 방식(K에 W_KV,i를 곱한 후 softmax와 곱함), 2) 최적화 방식(softmax와 K를 먼저 곱한 후 W_KV,i와 곱함).
- 최적화된 방식(Option 2)은 연산 복잡도가 더 낮아 생성 단계에서 더 효율적이다.
- Slim Attention은 프롬프트 단계에서는 기존 방식과 동일한 계산 복잡도를 가지지만, 생성 단계에서는 컨텍스트 메모리 읽기를 절반으로 줄여 처리 속도를 최대 2배까지 향상시킬 수 있다.
- Slim Attention은 Flash Attention과 호환되며, 모든 헤드를 병렬로 처리할 수 있어 많은 기기에서 더 효율적이고 빠르게 작동한다.
Transformer 모델의 편향 제거와 비정방행렬 지원
- Transformer 모델에서 편향(bias) 제거가 일반화되고 있으며, 특히 V 및 K 프로젝션의 편향을 수학적으로 동등한 방식으로 제거할 수 있다.
- 일부 Transformer 모델은 K와 V 프로젝션에 비정방행렬을 사용하며, 이를 지원하기 위해 두 가지 옵션이 제시된다.
1) 역행렬 계산을 통한 방법, 2) X-cache를 사용하는 방법.
- X-cache 방식은 계산 복잡도가 높지만 메모리 사용량을 크게 줄일 수 있으며, RoPE를 제외한 다른 위치 인코딩 방식과 호환된다.
- 인코더-디코더 Transformer에서도 K를 V로부터 계산하는 방식을 적용할 수 있으며, 이를 통해 크로스 어텐션의 KV-cache를 최적화하거나 제거할 수 있다.
- 이러한 최적화 기법들은 첫 토큰 생성 시간(TTFT)을 단축시키고, 특정 조건에서 전체 계산 복잡도를 줄일 수 있다.
트랜스포머 모델의 편향 제거 기법
- Transformer 모델에서 projection layer의 bias 제거가 일반화되고 있으나, 일부 모델(ex. Whisper)은 여전히 bias를 사용한다.
- V projection의 bias는 출력 projection layer의 bias와 수학적으로 동등한 방식으로 결합하여 제거할 수 있다.
- K projection의 bias는 softmax 함수의 상수 불변성 때문에 상쇄되어 제거 가능하다.
- Query vector에 대한 bias는 여전히 필요하지만, key vector의 bias는 완전히 제거할 수 있다.
- 이러한 bias 제거 기법은 RoPE(Rotary Positional Encoding)가 projection과 dot-product 계산 사이에 적용되지 않는 경우에 유효하다.
비정방 가중치 행렬을 사용하는 Transformer 모델의 KV-cache 최적화
- 비정방 가중치 행렬을 사용하는 Transformer 모델들이 있으며, 이들은 d ≠ d_kh 조건을 만족하지 않는다.
- KV-cache를 2배 이상 줄이기 위한 두 가지 옵션이 있으며, 각각 계산 복잡성과 메모리 사용량 간의 trade-off를 가진다.
- 옵션 1은 V 대신 K를 저장하고 V를 K로부터 계산하는 방식으로, 더 큰 행렬을 저장해야 하는 단점이 있다.
- 옵션 2는 projection 이전의 작은 d-element 벡터 X를 저장하고 V와 K를 실시간으로 계산하는 방식으로, 캐시 크기를 크게 줄일 수 있지만 계산 비용이 더 높다.
- 두 옵션 모두 기존 방식보다 계산 복잡성이 높지만, 특히 T5-11B 모델의 경우 옵션 2를 사용하면 캐시 크기를 32배까지 줄일 수 있다.
X-cache를 활용한 Slim Attention 구현
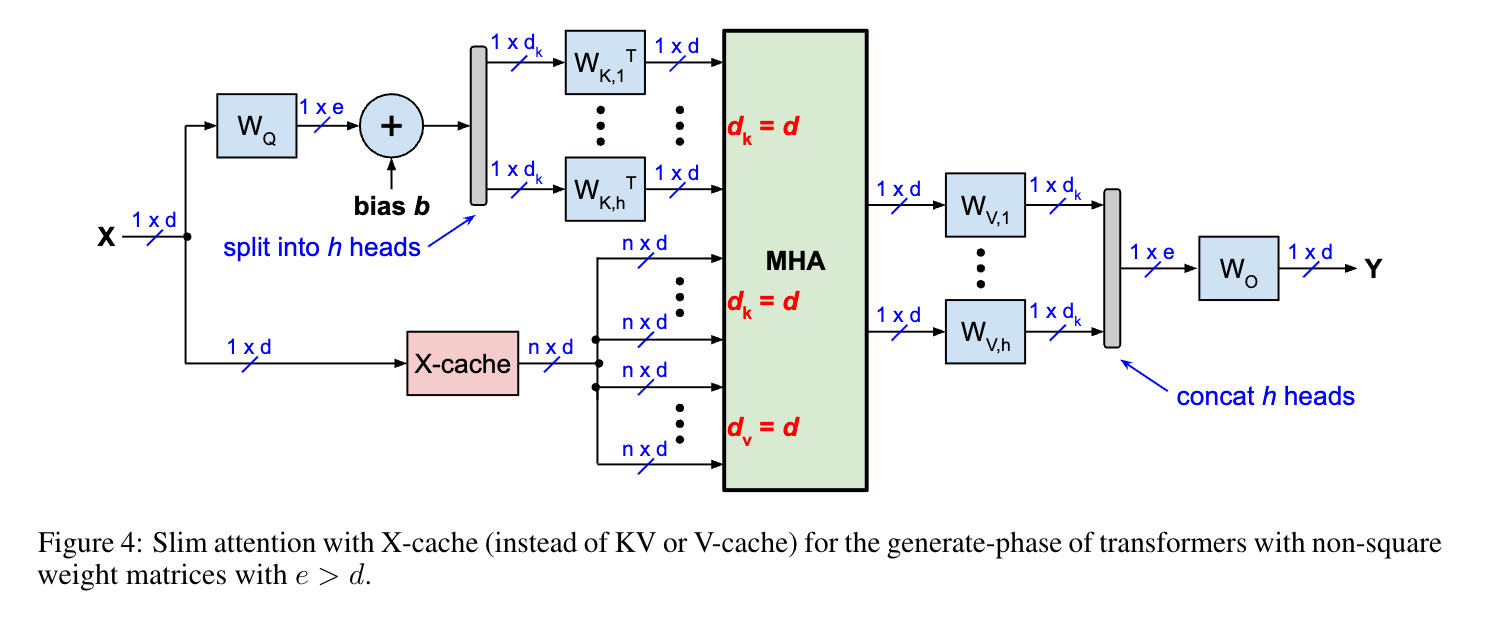
- X-cache는 KV 또는 K-cache 대신 입력 활성화를 포함하는 X-matrix를 저장하여 메모리 효율성을 높인다.
- 생성 단계에서는 쿼리에 대해 하나의 입력 벡터만 사용하고, 키와 값 투영에 대해서는 n개의 입력 벡터를 사용한다.
- 각 어텐션 헤드에 대해 x_nW^T_K,i 항을 한 번만 계산하면 되며, 이는 시퀀스 길이와 무관하게 d 차원으로 고정된다.
- 이 방식은 총 4de 연산을 필요로 하며, Whisper 모델과 같이 편향(bias)이 있는 투영 레이어에도 적용 가능하다.
- X-cache 방식은 T5 모델의 RPE, Alibi, Kerple, FIRE 등 상대적 위치 인코딩 기법과 호환되지만, RoPE와는 직접적으로 호환되지 않는다.
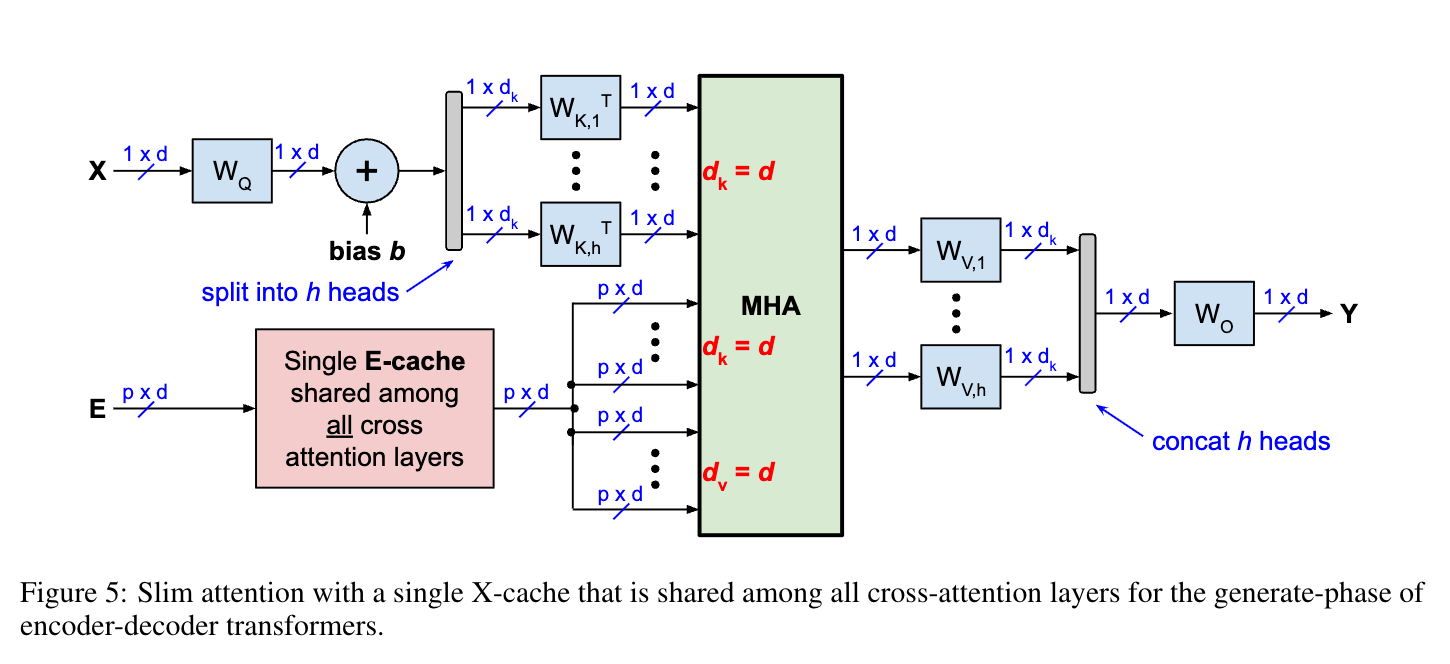
인코더-디코더 트랜스포머의 컨텍스트 메모리 최적화 옵션
- 인코더-디코더 트랜스포머(예: Whisper, T5, Chronos)에 대해 두 가지 컨텍스트 메모리 옵션을 제시한다.
- 옵션 1은 셀프 어텐션와 크로스 어텐션 모두에서 V-캐시를 제거하여 총 캐시 크기를 2배 줄인다.
- 옵션 2는 교차 KV-캐시 전체와 자기 주의의 V-캐시를 제거하여 메모리 사용량을 더욱 감소시킨다.
- 기준 구현은 프롬프트 단계, 교차 단계, 생성 단계의 세 단계로 구성되며, 각 단계에서 인코더와 디코더가 다르게 작동한다.
- 옵션 1은 교차 주의에 대해 K에서 V를 계산하므로 생성 단계에서 교차 WKV 매개변수를 읽어야 하지만, RoPE(Rotary Position Embedding)를 지원한다.
Whisper 모델에 대한 Slim Attention 성능 비교
- Whisper 모델의 tiny, base, small 버전에 대해 파라미터 수, 레이어 수, 차원 등의 구조적 특성을 비교했다.
- Slim Attention 적용 시 캐시 크기가 기존 대비 크게 감소하며, 특히 Option 2에서 8.7배의 메모리 절감 효과를 보였다.
- 생성 단계에서의 파라미터 수는 모델 크기에 따라 28.2M에서 146.0M까지 다양하게 나타났다.
- 배치 크기 1과 64에 대해 토큰당 메모리 읽기 횟수를 비교한 결과, Slim Attention (Option 1, 2)이 기존 방식보다 1.07~5.8배 속도 향상을 보였다.
- MHA(Multi-Head Attention) 복잡도는 소프트맥스 연산, V와 K의 가중합 등으로 구성되며, 이는 생성 단계에서의 토큰당 MHA 복잡도를 나타낸다.
MHA 복잡도 분석 및 V-cache 활용 방안
- MHA(Multi-Head Attention)의 복잡도는 행렬 곱셈 연산을 기반으로 계산되며, 약 2mnp OPs로 근사된다.
- Slim Attention은 기존 MHA 대비 KV-cache 크기를 절반으로 줄여 메모리 효율성을 높인다
- V-cache만을 사용하는 대안적 방식이 제안되었으나, 이 방식은 RoPE(Rotary Position Embedding)와 호환되지 않는 한계가 있다
- GQA(Grouped Query Attention) 모델에서도 Slim Attention 적용이 가능하며, 압축 비율(c)에 따라 구현 방식이 달라진다.
- Gemma2-9B와 같은 모델에서는 압축 비율이 1과 2 사이일 때, 특별한 구현 방식을 통해 Slim Attention을 적용할 수 있다.
Slim Attention 관련 연구 및 참고 문헌
- Slim Attention 기술은 CodeLlama, CodeGemma, Aya23등 다양한 오픈 소스 코드 모델 프로젝트에서 활용되고 있다.
- SmolLM2와 SmolVLM은 Slim Attention을 적용한 소형 언어 모델과 비전-언어 모델의 예시이다.
- Slim Attention 기술은 분자 수준에서 유전체 규모까지의 시퀀스 모델링 및 설계에 적용되어 Evo모델에서 활용되었다.
- Phi-3와 같은 고성능 언어 모델은 Slim Attention을 통해 휴대폰에서 로컬로 실행 가능한 수준의 효율성을 달성했다.
- Slim Attention은 1비트 LLM 연구, DataComp-LM 프로젝트, OLMo 언어 모델 과학 가속화 연구 등 다양한 최신 LLM 연구에 적용되고 있다.
Slim Attention의 의의와 향후 연구 방향
- Slim Attention은 Transformer 모델의 새로운 attention 메커니즘으로, context memory 크기를 절반으로 줄여 inference 속도를 향상시킨다.
- 이 기법은 value (V) projection을 key (K) projection으로부터 계산하여 KV-cache 크기를 감소시키며, 모델 정확도를 유지하면서 긴 context 처리에 효율적이다.
- Slim Attention은 encoder-decoder 구조에서 context memory를 더욱 줄일 수 있고, RoPE와 같은 positional encoding 방식과도 호환된다.
- 다양한 Transformer 모델에 적용 가능하며, 메모리 효율성을 높여 모델 성능을 개선할 수 있는 잠재력을 가지고 있다.
- 향후 연구에서는 Slim Attention의 다양한 응용 분야와 더 큰 규모의 모델에 대한 적용 가능성을 탐구할 것으로 예상된다.




댓글