원문: https://arxiv.org/pdf/2502.11089
<한 장 정리>
Introduction - 긴 문맥 모델링의 중요성
최근 연구에서는 긴 문맥(long-context) 처리 능력이 차세대 대형 언어 모델(LLM)에서 매우 중요한 요소로 떠오르고 있음
• 복잡한 문제 해결과 심층 추론 (예: DeepSeek-AI, 2025)
• 긴 코드베이스를 한 번에 처리하는 코드 생성 (예: Zhang et al., 2023)
• 수많은 대화를 주고받는 AI 에이전트 시스템 (예: Park et al., 2023)
최근 등장한 OpenAI o-series, DeepSeek-R1, Gemini 1.5 Pro 같은 모델들은
✅ 긴 문서나 코드베이스를 한 번에 처리하고
✅ 수천 개의 단어가 포함된 대화를 이해하며
✅ 문맥을 유지하면서 복잡한 추론을 수행할 수 있음
하지만, 기존 어텐션(attention) 방식은 연산량이 너무 많아 속도가 크게 느려지는 문제가 있음
특히 64K 토큰 길이의 문장을 디코딩할 때, 연산 지연(latency)의 70~80%가 어텐션에서 발생함.
즉, 기존 방식으로는 긴 문맥을 효율적으로 처리하는 것이 어려운 상황
Introduction - 기존 Sparse Attention의 한계점
긴 문맥을 보다 효율적으로 처리하기 위해 희소 어텐션(sparse attention) 방식이 연구되고 있음
이 방법은 모든 토큰을 다 계산하지 않고, 중요한 부분만 선택하여 연산량을 줄이는 방식
최근 연구들은 희소 어텐션을 구현하는 다양한 방법을 제안함
• 필요 없는 정보 제거(KV 캐시 삭제) (Li et al., 2024)
• 중요한 블록만 선택하는 방법 (Gao et al., 2024)
• 샘플링, 클러스터링, 해싱을 이용한 선택 방법 (Chen et al., 2024)
하지만, 이론적으로 계산량이 줄어들어도 실제 속도 향상은 크지 않은 경우가 많다. 또한, 대부분의 방법이 학습 과정에서는 희소성을 효과적으로 활용하지 못해 성능 개선이 제한적이다.
이 문제를 해결하려면 두 가지가 중요
1️⃣ 실제 하드웨어에서 속도를 향상시킬 수 있도록 알고리즘을 최적화해야 함
2️⃣ 학습 과정에서 희소성을 활용하여 연산량을 줄이면서도 성능을 유지해야 함
기존 방법들은 이 두 가지를 제대로 해결하지 못했다.
희소 어텐션(sparse attention)은 연산량을 줄이는 데 성공했지만, 실제로 속도(추론 시간)를 줄이는 데는 실패하는 경우가 많다. 그 이유는 크게 두 가지!
1️⃣ 일부 단계에서만 희소성을 적용 (Phase-Restricted Sparsity)
많은 희소 어텐션 방법들이 모든 과정에서 연산을 줄이는 게 아니라, 특정 단계에서만 적용함
• H2O (Zhang et al., 2023b): 디코딩할 때만 연산을 줄이지만, 그 전에 어텐션 맵 계산, 인덱스 빌드 같은 사전 작업(prefilling)이 너무 무거움.
• MInference (Jiang et al., 2024): 사전 작업(prefilling) 단계에서 연산을 줄이지만, 그 이후 디코딩할 때는 기존 Full Attention과 연산량이 비슷함.
즉,
✅ 책 요약 같은 사전 작업이 긴 작업에서는 → 사전 작업이 무거우면 속도 향상이 크지 않음.
✅ CoT 추론 같은 디코딩 중심 작업에서는 → 디코딩이 빠르지 않으면 효과가 제한됨.
결국, 모든 단계에서 연산을 줄이지 않으면 실제 속도 향상은 어렵다.
2️⃣ 최신 어텐션 방식과 호환되지 않음 (Incompatibility with Advanced Attention Architecture)
최신 트랜스포머 모델들은 메모리 접근 속도를 줄이기 위해 여러 개의 쿼리(Query)를 공유하는 방식을 사용함
• Multiple-Query Attention (MQA) (Shazeer, 2019)
• Grouped-Query Attention (GQA) (Ainslie et al., 2023)
이 방법들은 여러 개의 쿼리들이 같은 키-값(KV) 캐시를 공유해서, 메모리 접근 병목(memory bottleneck)을 해결하고, 디코딩 속도를 높이는 방식
하지만, 일부 스파스 어텐션 방법(예: Quest (Tang et al., 2024))은 각각의 어텐션 헤드가 자신만의 KV 캐시를 선택하는 방식을 사용함
• 기존 Multi-Head Attention(MHA)에서는 잘 작동하지만,
• MQA, GQA 같은 최신 방식에서는 각 헤드가 따로따로 메모리에 접근해야 해서 속도가 느려질 수 있다.
결국,
✅ 연산량은 줄였지만, 메모리 접근이 최적화되지 않아 속도가 크게 향상되지 않는 문제가 발생한다.
Introduction - NSA: 더 효과적인 Sparse Attention 방식
이 문제를 해결하기 위해, 이 논문에서는 NSA(Natively Trainable Sparse Attention, 네이티브 학습 가능 희소 어텐션)를 제안한다. NSA는 필요한 정보만 남기면서도 중요한 내용을 잃지 않도록 설계됨
✅ 어떻게 연산량을 줄일까? NSA는 토큰을 세 가지 방식으로 나눠서 처리
1. 압축된(coarse-grained) 토큰을 활용하여 빠르게 전체적인 문맥을 파악
2. 중요한(fine-grained) 토큰만 선택적으로 유지하여 세부 정보를 보존
3. 슬라이딩 윈도우(sliding window)를 이용해 주변 문맥을 유지 이를 통해 연산량을 줄이면서도 모델이 중요한 정보를 놓치지 않도록 함
✅ 실제 속도도 빨라질까? NSA는 하드웨어 친화적 설계를 통해 실제 속도를 대폭 향상시켰다.
1️⃣ 블록 단위로 어텐션을 처리하여 GPU 연산을 최적화
2️⃣ 메모리 접근을 최소화하여 불필요한 연산을 줄임
3️⃣ 학습 과정에서 희소성을 효과적으로 활용할 수 있도록 설계하여 성능을 유지하면서 연산량을 줄임
Introduction - NSA: 학습까지 가능!
왜 학습 가능한 sparse attention이 필요해? → 기존의 추론 전용 희소 어텐션(inference-only sparse attention) 방식에서 두 가지 큰 문제를 발견했기 때문!
1️⃣ 성능 저하 (Performance Degradation)
• 스파스 어텐션을 pretraining 후에 추가하면, 모델이 원래 최적화된 방향에서 벗어날 수 있음
• 예를 들어, Chen et al. (2024b) 연구에 따르면, “중요한 20%의 어텐션만 남긴다 해도, 전체 어텐션 점수의 70%만 유지된다.” • 즉, 모델이 중요한 정보를 찾는 구조(예: 검색 어텐션 retrieval heads)가 잘려나가면서 성능이 떨어질 위험이 있음
2️⃣ 학습 효율성 문제 (Training Efficiency Issues)
• 최신 대형 언어 모델(LLM)들은 긴 문맥(long-context)을 학습하는 과정이 매우 중요
• 긴 문서를 활용한 pretraining → 모델의 문맥 이해 능력 강화
• 긴 문맥을 활용한 파인튜닝(fine-tuning) 및 강화학습(RLHF) → 모델의 적응력 향상
• 그러나 기존의 스파스 어텐션 방법들은 추론 속도를 높이는 데만 집중했고, 긴 문맥을 학습하는 과정에서 발생하는 연산 비용 문제는 해결하지 못했음
• 이 문제를 해결하지 않으면, 더 강력한 긴 문맥 모델을 효율적으로 학습하기 어려움
기존 스파스 어텐션을 학습하면 왜 안돼?
1️⃣ 학습할 수 없는 연산 요소 (Non-Trainable Components)
• 일부 스파스 어텐션 방식은 학습 과정에서 희소 패턴을 최적화하기 어렵다.
• 예를 들어 • ClusterKV (Liu et al., 2024) → K-평균(K-means) 클러스터링 기반 토큰 선택
• MagicPIG (Chen et al., 2024b) → SimHash 기반 토큰 선택
이런 방식들은 연산 과정이 불연속적(discrete)이라 역전파 원활하지 않아 학습이 어려움.
2️⃣ 비효율적인 역전파 (Inefficient Backpropagation)
• 이론적으로는 학습이 가능한 희소 어텐션도 실제 학습할 때는 속도가 느려지는 경우가 많다.
• 예를 들어, HashAttention (Desai et al., 2024)은 개별 토큰 단위로 선택하는 전략을 사용
• 이 때문에 어텐션 연산을 할 때 KV 캐시에서 많은 토큰을 불규칙하게 로드해야 함.
• 하지만, 최신 고속 어텐션 기법(예: FlashAttention)은 연속적인 메모리 접근과 블록 단위(blockwise) 연산을 활용해야 속도가 빠름
• 메모리 접근이 불규칙하면, FlashAttention 같은 고속 기법을 활용할 수 없고 학습 속도가 느려진다.
Introduction - NSA의 등장
앞서 설명한 추론 속도 문제와 학습 과정의 비효율성은, 스파스 어텐션 기법을 근본적으로 다시 설계해야 하는 필요성을 보여줌
이를 해결하기 위해, NSA(Natively Sparse Attention)를 제안
NSA는 처음부터 희소성을 고려하여 설계된(natively sparse) 어텐션 프레임워크로,
✅ 연산 효율성(computational efficiency)과
✅ 학습 과정의 요구(training requirements)를 모두 충족하도록 설계되었다!
Introduction - NSA 결과 미리보기
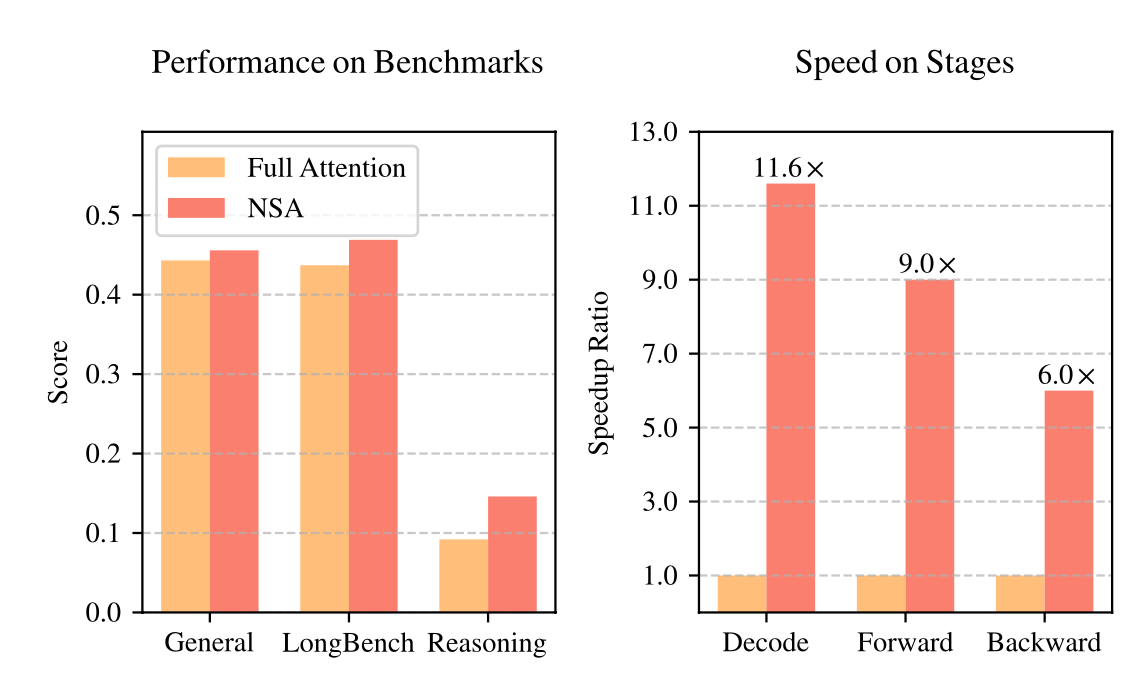
NSA의 실험 결과: 성능은 유지하면서 속도는 대폭 향상
실험 결과
✅ NSA는 기존 Full Attention 모델과 비슷하거나 더 좋은 성능을 보임
✅ 기존의 다른 스파스 어텐션 방법보다 더 높은 성능을 기록
✅ 디코딩, 순전파, 역전파 과정에서 Full Attention보다 훨씬 빠르게 처리
✅ 시퀀스 길이가 길어질수록 속도 차이가 더 크게 벌어짐
→ 즉, NSA는 긴 문맥을 처리할 때 성능과 연산 효율성을 모두 잡은 새로운 희소 어텐션 방식임이 입증되었다.
Methodology - 배경
어텐션(Attention) 메커니즘은 언어 모델이 문장을 이해하는 핵심 기술
각 쿼리 토큰 q_t 이 이전의 모든 키 k_{1:t} 와 비교하여 관련성 점수(relevance scores)를 계산한 후,
해당 점수를 가중치로 사용해 값(value)들의 가중합(weighted sum)을 생성하는 방식
이를 수식으로 표현하면, 입력 시퀀스 길이가 t 일 때 어텐션 연산은 다음과 같이 정의됨

여기서 어텐션 함수(Attn) 는 다음과 같다.

즉, 쿼리 q_t 가 어떤 값들을 중요하게 여길지를 결정하는 과정이 바로 어텐션
긴 문장(Long-Context)에서의 문제점
문장의 길이( t )가 길어질수록,
✅ 어텐션이 계산해야 하는 양이 기하급수적으로 증가
✅ 전체 연산량에서 어텐션이 차지하는 비중이 매우 커짐
이 때문에, 긴 문장을 처리할 때 속도가 느려지는 문제가 발생함
이를 해결하기 위해서는 연산 강도(Arithmetic Intensity)를 최적화해야 한다.
연산 강도는 연산량(계산해야 하는 작업량)과 메모리 접근량(불러와야 하는 데이터의 양)의 비율을 의미
연산 강도에 따라 두 가지 경우가 있다.
1️⃣ 연산이 많고, 메모리 접근이 적은 경우 (Compute-bound)
• GPU의 연산 능력(FLOPS)이 제한 요소
• 연산을 최적화하면 속도가 빨라진다.
2️⃣ 메모리 접근이 많고, 연산이 적은 경우 (Memory-bound)
• 메모리 대역폭이 제한 요소
• 메모리 접근을 줄이는 것이 핵심이다.
어텐션 연산은 단계별로 연산 강도가 다름
1️⃣ 학습(training) 및 사전 채우기(prefilling) 단계
• 행렬 곱셈(matrix multiplication)과 어텐션 연산이 많음
• 연산 강도가 높아 GPU의 연산 성능(FLOPS)에 의해 속도가 결정됨(Compute-bound).
• 👉 연산량을 줄이는 것이 속도를 높이는 핵심 방법!
2️⃣ 자동회귀 디코딩(auto-regressive decoding) 단계
• 한 번에 한 개의 토큰만 생성하지만,
• 이전 모든 키-값(KV) 캐시를 불러와야 함
• 메모리 접근이 많아, 메모리 대역폭이 속도를 결정함(Memory-bound).
• 👉 메모리 접근을 최적화하는 것이 속도를 높이는 핵심 방법!
결론: NSA의 최적화 목표
어텐션 연산의 특성을 고려할 때, NSA의 최적화 방향은 두 가지다.
✔ 학습 및 사전 채우기 단계 → 연산량을 줄여 GPU 계산 비용을 낮추는 것이 중요!
✔ 디코딩 단계 → 메모리 접근을 최적화해 속도를 높이는 것이 중요!
희소한(sparse) 패턴을 활용하는 어텐션 구조를 만들기 위해, 기존의 키-값 쌍을 그대로 사용하는 대신,
더 압축되고 정보 밀도가 높은(compact & information-dense) 새로운 키-값 쌍 으로 대체하는 방식을 제안.
이렇게 최적화된 어텐션 연산은 다음과 같이 정의된다.
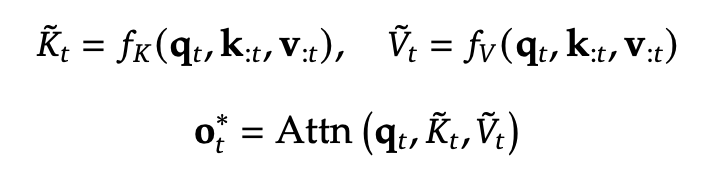
즉,
✅ 기존의 모든 키-값을 사용하는 대신,
✅ 현재 쿼리 q_t 에 맞게 최적화된(subset) 키-값 쌍 \tilde{K}_t, \tilde{V}_t 를 동적으로 구성
Methodology - 알고리즘 설계
NSA의 3가지 매핑 전략 (Mapping Strategies in NSA) NSA는 어떤 키-값 정보를 선택할지 결정하기 위해 3가지 전략을 사용한다. 이를 C = {cmp, slc, win} 으로 정의하며, 각각 다음을 의미한다.
1️⃣ 압축(Compression, cmp)
• 모든 키-값을 압축하여 정보 밀도가 높은 대표 키-값으로 변환
• 전체적인 흐름을 유지하는 역할
2️⃣ 선택(Selection, slc) • 가장 중요한 키-값만 골라서 저장
• 정보 손실을 최소화하면서도 연산량을 줄이는 역할
3️⃣ 슬라이딩 윈도우(Sliding Window, win) • 현재 시점에서 가까운(최근) 키-값만 유지
• 지역 문맥(local context)을 보존하는 역할
최종적인 어텐션 출력은 세 가지 전략의 조합으로 계산된다.

g는 각 전략에 대한 중요도를 나타내는 게이트 스코어.
MLP + 시그모이드 를 이용해서 계산
Methodology - 알고리즘 설계 1) 토큰 압축
어텐션 연산에서는 모든 키(Key)와 값(Value)를 하나하나 비교해야 하기 때문에 계산량이 너무 많아진다.
이를 해결하기 위해, NSA는 연속된 키-값들을 블록으로 묶어서 “압축된 대표 값”으로 변환하는 방식을 사용
이를 수식으로 표현하면, 압축된 키(Compressed Key) 표현은 다음과 같이 정의됨
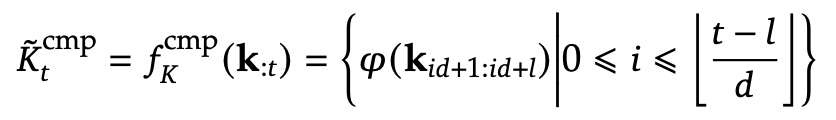
여기서,
• l : 블록 길이(Block Length) - 한 번에 묶어서 압축할 토큰 개수
• d : 슬라이딩 간격(Sliding Stride) - 다음 블록을 시작할 때 이전 블록에서 겹치는 정도
• \phi : 블록 내부 위치 정보를 포함한 학습 가능한 MLP - 블록 내의 키들을 하나의 압축된 키로 변환하는 함수
1️⃣ 여러 개의 키(Key)나 값(Value)를 하나의 블록으로 묶는다.
• 예를 들어, 10개의 키가 있으면, 이를 2-3개씩 그룹으로 묶는 것.
2️⃣ 각 블록의 정보를 유지하면서 하나의 대표 값으로 변환한다.
• 이때 MLP(다층 퍼셉트론, Multi-Layer Perceptron)라는 작은 신경망을 사용하여 블록을 하나의 벡터로 변환한다.
• 변환할 때, 블록 내 위치 정보도 고려해서 중요한 특징을 유지한다.
3️⃣ 이제 압축된 키와 값만 사용해 어텐션을 수행한다.
• 원래 100개 키가 있었다면, 압축 후 20-30개만 남아 계산량이 확 줄어든다.
왜 이렇게 하면 좋은 걸까?
✅ 연산량 감소 → 어텐션 속도 향상
• 원래는 모든 키와 값을 비교해야 했지만, 이제는 압축된 대표 키-값만 비교하면 되므로 계산량이 훨씬 줄어든다.
✅ 문맥 정보 유지 → 중요한 내용은 그대로 반영
• 단순히 키-값을 버리는 게 아니라, 블록 단위로 압축해서 중요한 정보는 유지한다.
• 즉, 큰 그림을 이해하는 능력(Coarse-grained information)이 더 좋아진다!
✅ 중복 정보 제거 → 효율적인 학습 가능
• 긴 문장에서 비슷한 정보가 여러 번 반복될 경우, 이를 하나로 압축해서 더 효율적으로 표현할 수 있다.
Methodology - 알고리즘 설계 2) 토큰 선택
토큰 압축(Token Compression)만 사용하면, 세부적인 정보(fine-grained information)를 잃을 위험이 있음
이를 해결하기 위해, NSA는 중요한 개별 토큰을 선택적으로 보존하는 토큰 선택(Token Selection) 기법을 사용
→ 블록 단위 선택(Blockwise Selection) 방식을 적용
블록 단위 선택 (Blockwise Selection) - 왜 필요한가?
✅ 1) GPU에서 빠르게 동작하도록 최적화
• 최신 GPU는 연속된(blockwise) 메모리 접근이 빠름 → 랜덤한 위치에서 데이터를 가져오는 방식보다 훨씬 효율적
• 블록 단위 연산을 사용하면, Tensor Core 같은 고속 연산 장치를 최적으로 활용할 수 있음.
• 실제로 FlashAttention도 이 방식으로 최적화됨.
✅ 2) 어텐션 점수 분포 특성을 활용
• 연구에 따르면, 어텐션 점수는 공간적으로 연속된 패턴을 가짐(Spatial Continuity).
• 즉, 서로 가까운 토큰들은 비슷한 중요도를 가지는 경향이 있음.
• 따라서, 개별 토큰을 따로 선택하는 것보다 블록 단위로 선택하는 것이 더 효과적임!
블록 중요도 점수 계산 (Importance Score Computation)
어떤 블록이 더 중요한지 판단하려면, 각 블록의 중요도를 평가하는 점수(Importance Score)가 필요
이를 계산하는 방법은?
1️⃣ 압축된 키(Compressed Key)와 현재 쿼리(Query) 간의 어텐션 점수 계산
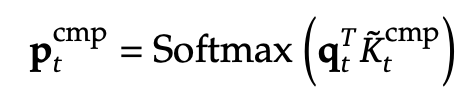
- 즉, 쿼리 q_t 가 압축된 키 \tilde{K}_{\text{cmp}, t} 와 얼마나 관련이 있는지 계산함.
- 이 값이 크면, 해당 블록이 더 중요하다는 의미.
2️⃣ 블록 크기(Selection Block Size)를 고려하여, 선택 블록의 중요도 점수를 계산
• 압축 블록과 선택 블록이 동일한 크기를 가지면, 선택블록의 중요도 점수 = 1번에서 구한 어텐션 스코어
• 크기가 다르면, 공간적 연관성을 고려하여 새롭게 변환.

l' = 선택 블록 크기
l = 압축 블록 크기
d = 슬라이딩 간격
3️⃣ 여러 개의 어텐션 헤드(Query Heads)를 사용하는 경우(GQA, MQA), 각 헤드의 중요도 점수를 공유해야 함.
• 공유된 중요도 점수를 계산하여 KV 캐시 로딩 비용을 최소화함
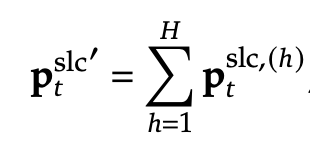
최종적으로 가장 중요한 블록을 선택 (Top-n Block Selection)
1️⃣ 블록 중요도 점수를 기반으로 가장 중요한 블록들을 찾음
• 블록을 중요도 점수 순서대로 정렬하고, 상위 n 개의 블록을 선택 .즉, 점수가 가장 높은 블록들만 남긴다!
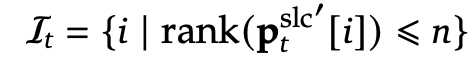
2️⃣ 선택된 블록들에서 키-값을 추출하고, 어텐션 연산에 사용
• 여기서 “Cat” 은 선택된 블록들을 하나로 합치는(concatenation) 연산을 의미함.

3️⃣ 선택된 K,V 를 어텐션 연산에 사용
• 최종적으로 중요한 정보만 남겨서 연산량을 줄이면서도 성능을 유지하는 효과를 얻을 수 있음!
쉽게 정리하면,
1️⃣ GPU에서 빠르게 동작하도록 “블록 단위”로 토큰을 선택하는 전략 사용
2️⃣ 어텐션 점수를 계산해, 가장 중요한 블록을 찾아 선택
3️⃣ 선택된 블록의 키-값만 사용하여 어텐션 수행 → 연산량 절감 + 중요한 정보 유지!
Methodology - 알고리즘 설계 3) 슬라이딩 윈도우
어텐션 메커니즘에서는 최근(local) 패턴이 빠르게 학습되는 경향이 있다.
하지만, 이전 패턴이 너무 강하게 반영되면 압축(Compression) 및 선택(Selection) 토큰 학습이 방해될 수 있음.
즉, 모델이 최근 정보에만 의존하게 되어, 긴 문맥(Long-context)을 제대로 학습하지 못하는 문제가 발생할 수 있다.
→ 이를 해결하기 위해, NSA는 독립적인 슬라이딩 윈도우(Sliding Window) 어텐션 경로를 추가함
이 경로는 지역 문맥(Local Context)만 따로 처리하도록 설계되어,
✅ 압축(Compression)과 선택(Selection) 어텐션 경로가 자신의 역할을 더 잘 수행하도록 지원한다.
슬라이딩 윈도우 방식 (How Sliding Window Works)
NSA에서는 최근 w 개의 토큰만 따로 유지하면서 지역 문맥을 다룬다. 이를 수식으로 표현하면,
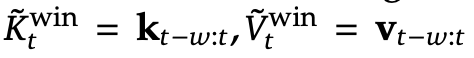
• 최근 w 개의 키와 값을 유지
• 압축된 키-값, 선택된 키-값, 슬라이딩 윈도우 키-값을 분리하여 처리
• 각 경로에서 나온 정보를 학습된 게이트 메커니즘(Gating Mechanism)으로 합침
즉,
✅ 가까운 단어들(Local Context)은 슬라이딩 윈도우에서만 처리!
✅ 나머지 경로(압축, 선택)는 긴 문맥을 학습하는 데 집중!
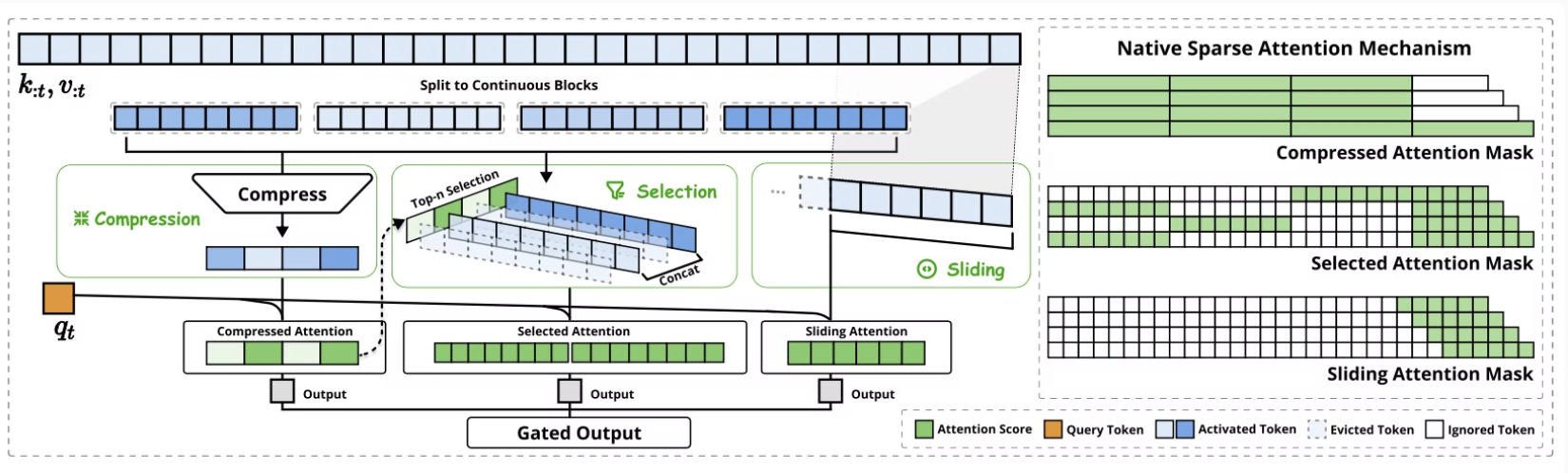
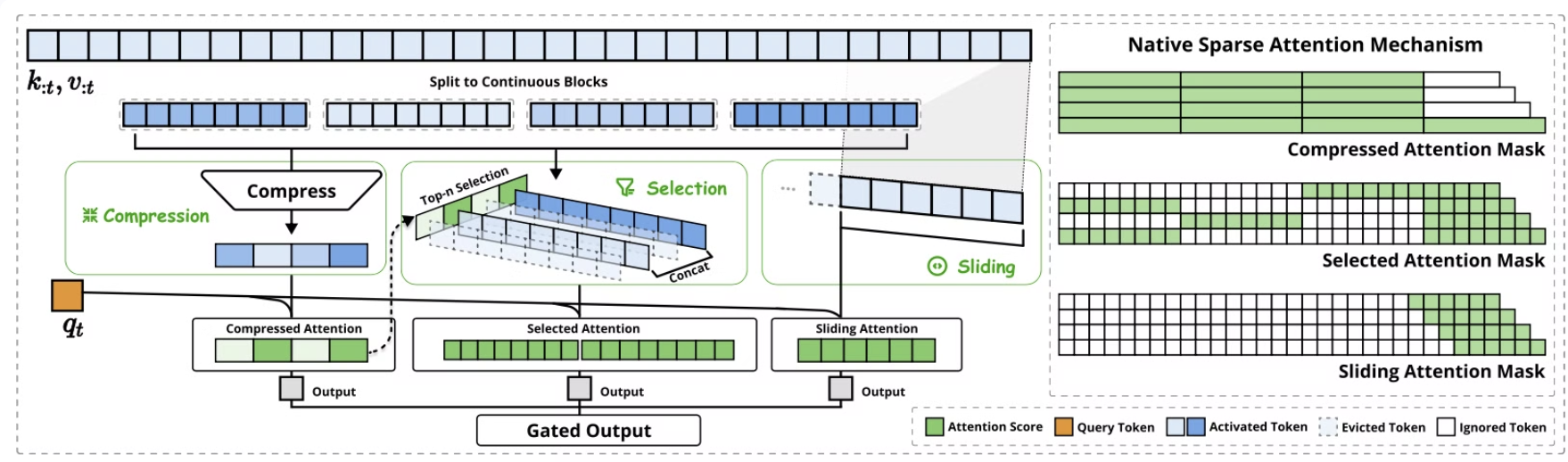
NSA 아키텍처 개요
왼쪽: NSA는 입력 시퀀스를 세 개의 병렬 어텐션(branch) 경로를 통해 처리한다.
특정 쿼리(query)에 대해, 이전의 키(key)와 값(value)은 다음 세 가지 방식으로 어텐션을 수행한다.
- 압축 어텐션(compressed attention): 전체적인 패턴을 파악하는 대략적인 어텐션
- 선택적 어텐션(selected attention): 중요한 토큰 블록을 대상으로 수행하는 어텐션
- 슬라이딩 어텐션(sliding attention): 지역 문맥(local context)을 유지하는 어텐션
오른쪽: 각 어텐션 경로에서 생성된 다양한 어텐션 패턴을 시각화한 그림.
• 초록색 영역(green areas): 어텐션 점수를 계산해야 하는 부분
• 흰색 영역(white areas): 연산을 생략할 수 있는 부분 (즉, 희소성 적용)
Methodology - 커널 설계
학습 및 프리필링 단계에서 FlashAttention 수준의 속도 향상을 달성하기 위해,
Triton 기반의 하드웨어 최적화된 스파스 어텐션 커널을 구현.
왜냐면, 토큰 압축이나 슬라이딩 윈도우 어텐션은 기존 FlashAttention-2와 쉽게 호환되지만 희소 선택 어텐션은 특별한 처리가 필요해 새로운 커널을 설계해야 했다.
사용한 아키텍처
- 기존의 MHA(Multi-Head Attention)는 디코딩(텍스트 생성) 과정에서 메모리를 많이 사용하고 비효율적
- 그래서 최신 LLM들처럼 GQA나 MQA 같은 공유 KV 캐시 방식을 채택 - 여러 어텐션 헤드가 키와 값을 공유하여 메모리를 절약
발생한 문제점
- FlashAttention은 시간적으로 연속된 쿼리 블록을 SRAM에 로드
- 하지만 NSA에서는 같은 블록 안의 쿼리들이 서로 다른 KV 블록을 필요로 할 수 있어 비효율적인 메모리 접근이 발생
해결책
- 새로운 그룹화 방식을 도입: 쿼리 시퀀스의 각 위치에서, 같은 GQA 그룹 내 모든 쿼리 헤드(이들은 동일한 희소 KV 블록 집합을 사용)를 함께 SRAM에 로드 → 이렇게 하면 메모리 접근이 더 효율적임
Methodology - 커널 설계 1) Group-Centric Data Loading
그룹 중심 데이터 로딩
- 각 내부 루프에서, 위치 t에서 그룹 내 모든 헤드의 쿼리 Q ∈ R[h,dk] (h=헤드 수, dk=각 쿼리 벡터 차원)와 그들이 공유하는 희소 키/값 블록 인덱스 It를 로드.
- 즉, 계산을 효율적으로 처리하기 위해, 특정 위치에서 필요한 정보와 그 정보가 어디에 저장되어 있는지에 대한 목록을 함께 로드한다
<도서관 비유>
- 당신(쿼리 Q)은 특정 주제에 관한 정보를 찾고 있습니다.
- 도서관에는 여러 섹션(헤드)이 있고, 각 섹션마다 당신이 찾는 주제와 관련된 책(키/값)이 있습니다.
- 사서가 미리 준비한 목록(인덱스 It)에는 당신이 찾는 주제와 관련된 책들의 위치만 선별되어 있습니다(희소).
- 당신은 각 섹션을 돌아다니며(내부 루프) 목록에 있는 책들만 효율적으로 찾아볼 수 있습니다.
Methodology - 커널 설계 2) Shared KV Fetching
공유 KV 가져와서 활용
- 내부 루프에서, It로 인덱싱된 키/값 블록을 SRAM에 K ∈ R[Bk,dk], V ∈ R[Bk,dv]로 순차적으로 로드하여 메모리 로딩을 최소화
- 여기서 Bk는 Bk|l'을 만족하는 커널 블록 크기.(Bk는 한 번에 처리하는 블록의 크기. l'이 Bk로 나누어 떨어짐.)
- 즉, 필요한 데이터를 효율적으로 가져오기 위해, 인덱스가 가리키는 데이터를 적절한 크기로 나누어 빠른 메모리에 순차적으로 불러온다는 것!
<도서관 비유>
- 당신은 특정 주제(쿼리 위치 t)에 대해 찾아야 할 책들의 목록(인덱스 I_t)을 가지고 있습니다.
- 도서관의 모든 책은 메인 서가(메인 메모리)에 있지만, 실제 연구는 빠른 접근이 가능한 특별 작업대(SRAM)에서만 할 수 있습니다.
- 작업대는 크기가 제한되어 있어 한 번에 Bk개의 책만 올려놓을 수 있습니다.
- 효율성을 위해, 목록에 있는 책들을 정확히 Bk개씩 묶어서(블록 단위로) 작업대로 가져옵니다.
- 도서관의 분류 체계는 각 주제별 관련 책의 총 수(l')가 항상 Bk의 배수가 되도록 설계되어 있습니다(Bk|l').
- 같은 연구 그룹의 모든 연구자들(같은 GQA 그룹의 쿼리 헤드들)이 동일한 책 목록을 공유하므로, 한 번 가져온 책들을 모두가 활용할 수 있어 더욱 효율적입니다.
- 이 방식은 서가와 작업대 사이를 오가는 횟수를 최소화하고, 작업대를 항상 효율적으로 활용하게 해줍니다.
Methodology - 커널 설계 3) Outer Loop on Grid
그리드 상의 외부 루프
- 내부 루프 길이가 거의 동일하게 유지된다는 패턴을 찾음.
- 쿼리/출력 루프를 Triton의 그리드 스케줄러에 배치하여 커널을 단순화하고 최적화
<도서관 비유>
- 사서는 중요한 관찰을 했습니다: 주제가 다르더라도 각 연구자가 검토해야 할 책의 수가 거의 동일합니다(약 20권씩).
- 도서관에는 5개의 작업대가 있고,(GPU의 여러 처리 유닛) 각 작업대에 서로 다른 주제를 처음부터 할당합니다
- 연구자 A: 역사 20권, 연구자 B: 과학 20권, 연구자 C: 문학 20권...
Methodology - 커널 설계
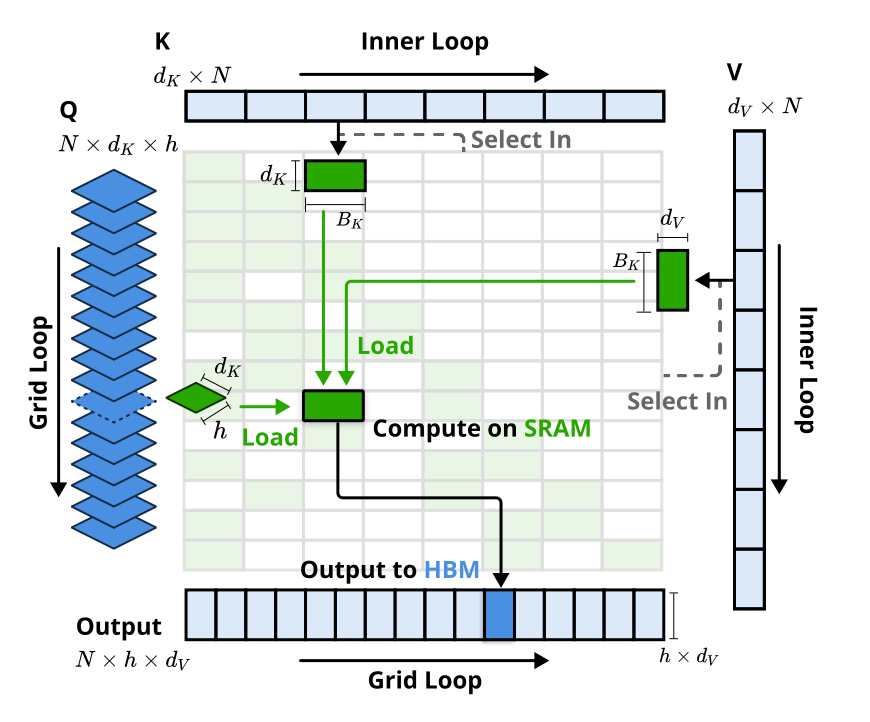
- 커널은 GQA 그룹별로 쿼리를 로드하고(그리드 루프),
- 해당하는 희소 KV 블록을 가져오며(내부 루프),
- SRAM에서 어텐션 계산을 수행
녹색 블록은 SRAM에 있는 데이터, 파란색은 HBM에 있는 데이터를 나타냄
Experiments - 프리트레인
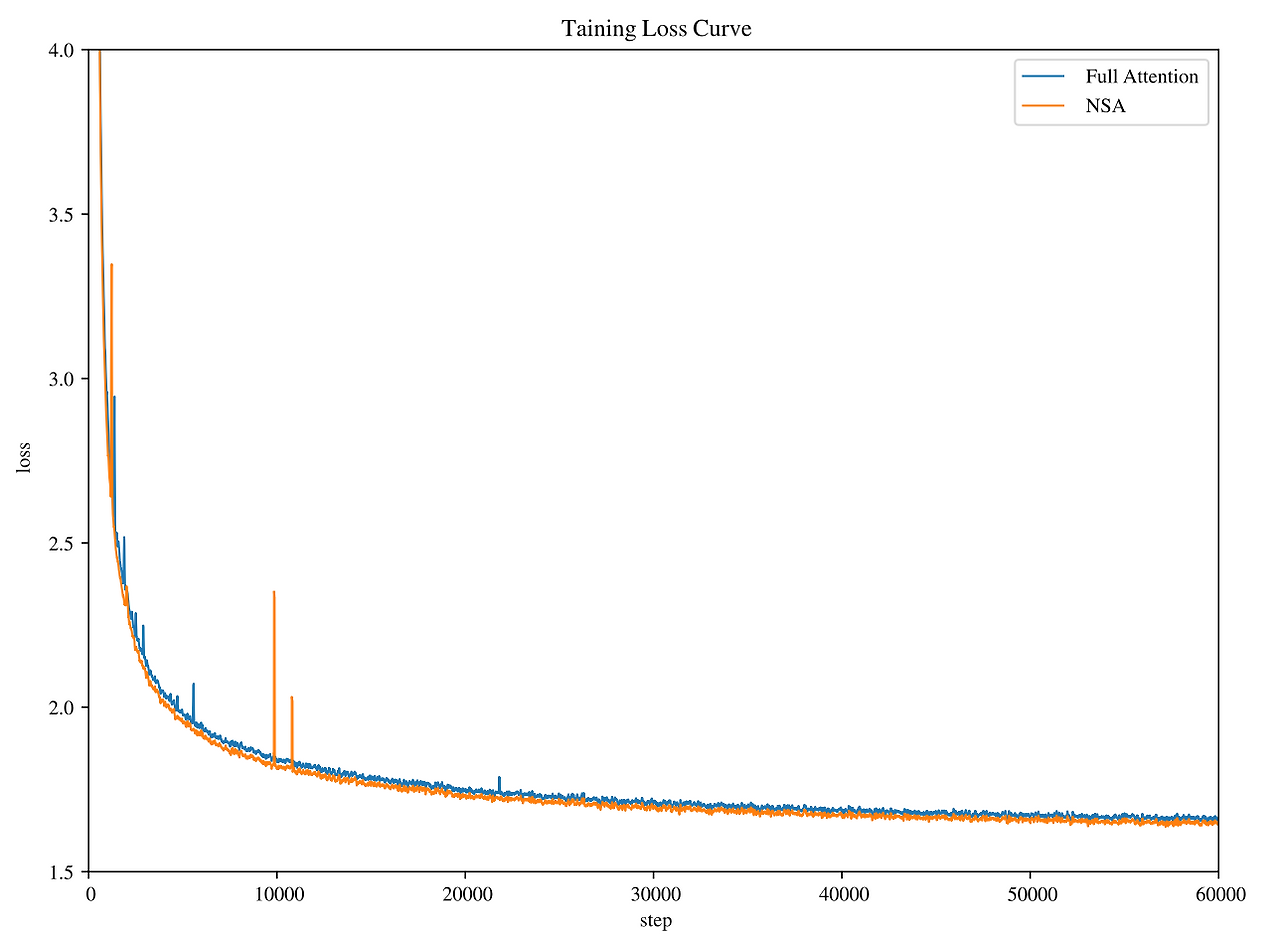
결과
훈련 중 손실값이 안정적으로 감소함
- NSA 모델이 풀 어텐션 모델보다 일관되게 더 낮은 손실값을 보임
- 즉, NSA가 더 효율적으로 학습하고 더 좋은 성능을 보였다는 의미
Experiments - 베이스라인 비교
- Full Attention: 전통적인 방식으로, 모든 단어 사이의 관계를 전부 계산
- 다른 스파스 어텐션 방법들:
NSA(Neural Sparse Attention)를 베이스라인들과 아래 방식으로 비교
(1) 일반 벤치마크 성능 - 짧은 텍스트에서는 모든 스파스 방법들이 풀 어텐션과 거의 동일한 결과를 보이므로, 여기서는 NSA와 풀 어텐션만 비교
(2) 긴 컨텍스트 벤치마크 성능 - 모든 방법들을 비교했고, 공정한 비교를 위해 모든 스파스 방법론들이 같은 비율로 정보를 압축하도록 설정
(3) CoT 리즈닝 성능 - 다른 스파스 어텐션 방법들은 훈련을 지원하지 않기 때문에, NSA와 풀 어텐션만 비교
Experiments - 일반 벤치마크

프리트레인된 NSA와 전체 어텐션 베이스라인을 지식, 추론, 코딩 능력을 포괄하는 종합적인 벤치마크 모음에서 평가
- NSA는 9개 중 7개 지표에서 풀 어텐션을 포함한 모든 베이스라인을 능가하며 전반적으로 우수한 성능을 달성함
- 특히, NSA는 추론 관련 벤치마크(DROP: +0.042, GSM8K: +0.034)에서 상당한 이득을 보여주었는데,
이는 프리트레인이 모델이 특화된 어텐션 메커니즘을 개발하는 데 도움이 된다는 것을 시사한다고 함.
Experiments - 긴 컨텍스트 벤치마크

NSA는 64k 컨텍스트 '건초더미 속 바늘 찾기'(needle-in-a-haystack, Kamradt, 2023) 테스트에서 모든 위치에서 완벽한 검색 정확도를 달성했다.
NSA가 왜 이 테스트에서 잘 했을까? NSA의 두 가지 전략을 결합한 희소 어텐션 셜계 때문!
1 넓게 훑어보기 (압축 토큰):
- 마치 책의 목차나 색인을 먼저 보는 것처럼, 전체 문서를 빠르게 스캔
- 긴 문서를 작은 요약(압축 토큰)으로 만들어 전체 내용을 효율적으로 파악
- 이렇게 하면 "바늘이 있을 만한 부분"을 대략적으로 찾을 수 있음
2 자세히 살펴보기 (선택 토큰):
- 넓게 훑어본 후, 중요해 보이는 부분에만 집중
- 이 선택된 부분들은 원래 그대로의 자세한 정보를 유지
- 이렇게 하면 정확한 "바늘"을 놓치지 않고 찾을 수 있음
Experiments - 긴 컨텍스트 벤치마크
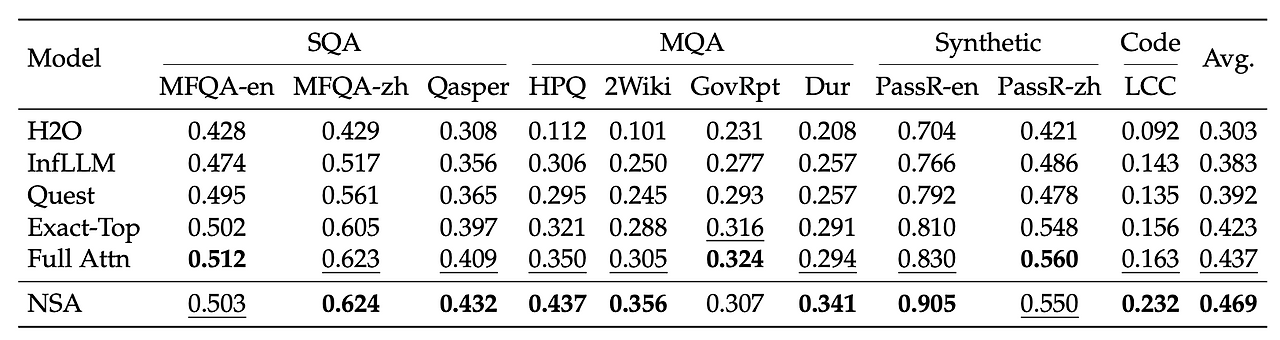
또한 NSA를 LongBench(Bai et al., 2023)에서 최신 스파스 어텐션 방법과 풀 어텐션 베이스라인과 비교하여 평가
결과
- NSA는 모든 방법 중 가장 높은 점수(0.469)를 받았다.
- 풀 어텐션보다 3.2% 높고, Exact-Top보다 4.6% 높은 점수.
NSA가 더 좋은 성능을 보인 이유
- 처음부터 스파스 어텐션으로 훈련됨: 다른 방법들은 보통 나중에 희소하게 만들지만, NSA는 처음부터 스파스 어텐션으로 훈련되어 모델 전체가 이에 맞게 적응했다.
- 지역과 전역 정보의 균형: 가까운 정보(지역)와 멀리 있는 정보(전역) 모두를 효과적으로 처리할 수 있다.
NSA가 특히 잘한 분야
- 복잡한 질의응답(HPQ, 2Wiki): 여러 단계의 추론이 필요한 질문에 답하는 능력이 다른 방법들보다 5-8% 더 뛰어났다. 멀티홉 QA 작업(HPQ 및 2Wiki)에서 전체 어텐션보다 +0.087 및 +0.051의 개선을 달성.
- 코드 이해(LCC): 프로그래밍 코드를 이해하고 분석하는 능력이 6.9% 더 높았다.
- 정보 검색(PassR-en): 긴 문서에서 특정 정보를 찾아내는 능력이 7.5% 더 우수했다.
Experiments - CoT 리즈닝 평가
- 작은 모델은 강화학습으로 가르치기 어려워서, 대신 더 똑똑한 모델(DeepSeek-R1)의 답변을 보고 배우게 했다(지식 증류).
- 학습 데이터: 100억 개의 수학 문제 풀이 예시(최대 32,000단어 길이)로 SFT
- 두 가지 모델 준비:
- 테스트: 두 모델 모두 어려운 수학 경시대회(AIME 24) 문제로 테스트
- 답변 생성 방식: 각 문제에 대해 16개의 다른 답변을 만들게 하고 평균 점수를 계산.(샘플링 온도 0.7과 상위-p 값 0.95)
- 두 가지 설정 비교:

결과:
- NSA 모델이 일반 모델보다 훨씬 더 높은 정확도를 보임:
Efficiency Analysis
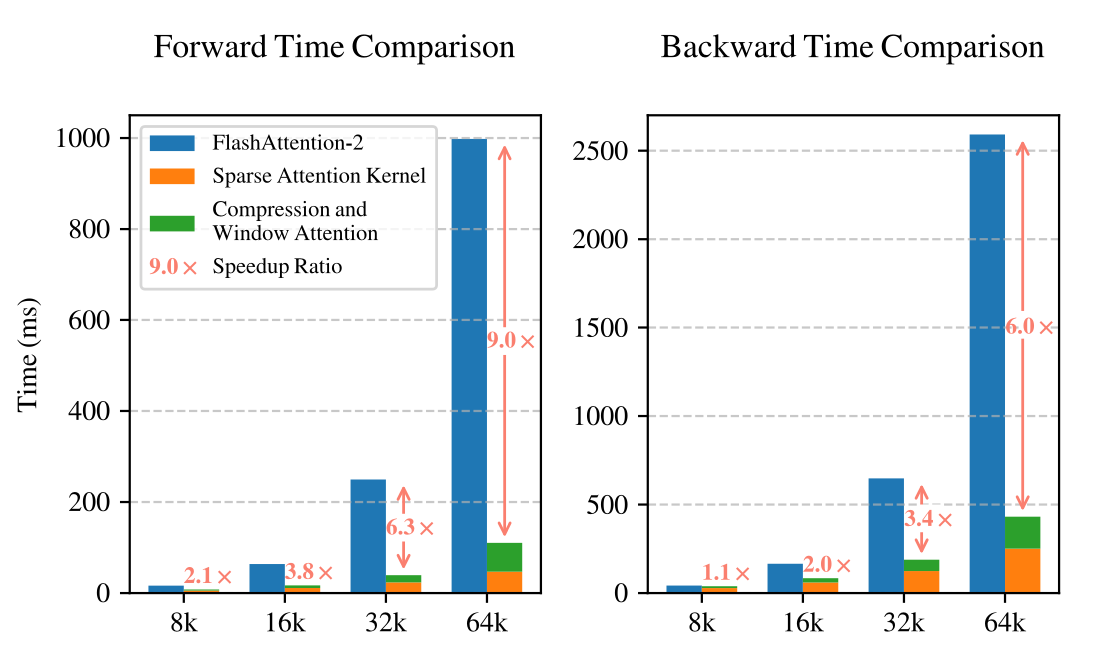
8-GPU A100 시스템에서 NSA와 전체 어텐션의 계산 효율성을 평가.
<학습 속도>
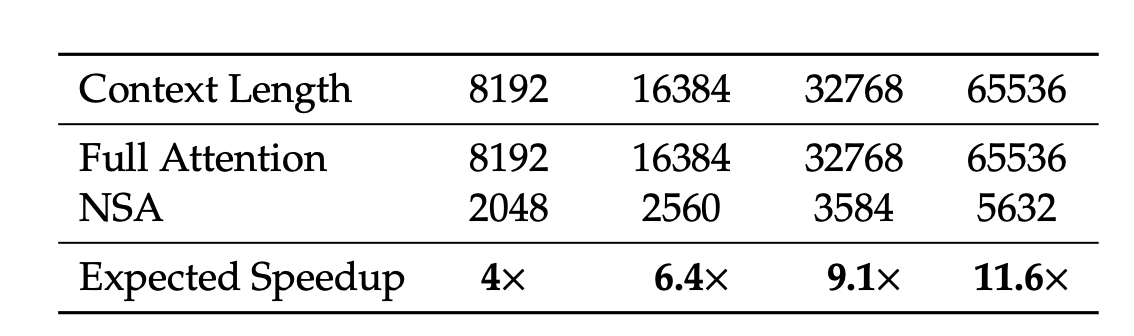
<디코딩 속도>
코드 실행 결과





댓글