원문: https://arxiv.org/pdf/2502.14499
이 논문에서는 MLGym와 MLGym-Bench라는 새로운 프레임워크를 소개하며 인공지능 에이전트의 성능을 평가하고 발전시키기 위한 기준을 제공합니다.
MLGym-bench는 컴퓨터 비전, 자연어 처리, 강화 학습, 게임 이론 등 다양한 분야에서 13개의 다채롭고 개방형인 AI 연구 과제로 구성됩니다. 이러한 과제들을 해결하기 위해서는 새로운 아이디어와 가설의 생성, 데이터 생성 및 처리, ML 기법 구현, 모델 학습, 실험 수행, 결과 분석, 그리고 반복적인 개선과정 등 실제 AI 연구에서 요구되는 다양한 역량이 필요합니다.
논문에서는 Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4o, o1-preview, Gemini-1.5 Pro 등 여러 최첨단 대규모 언어 모델(LLM)을 대상으로 벤치마크에서 성능을 평가했습니다. 실험 결과, 현재 최첨단 모델들은 일반적으로 더 나은 하이퍼파라미터를 찾음으로써 기존 성능 기준을 어느 정도 향상할 수 있지만, 새로운 가설이나 알고리즘, 아키텍처, 혹은 실질적인 성능 개선을 이끌어내지는 못하는 것으로 나타났습니다. 연구팀은 LLM 에이전트의 AI 연구 역량을 발전시키기 위한 후속 연구를 장려하고자, 본 프레임워크와 벤치마크를 오픈소스로 공개한다고 합니다.
1. MLGym: AI 연구 에이전트를 위한 새로운 프레임워크와 벤치마크
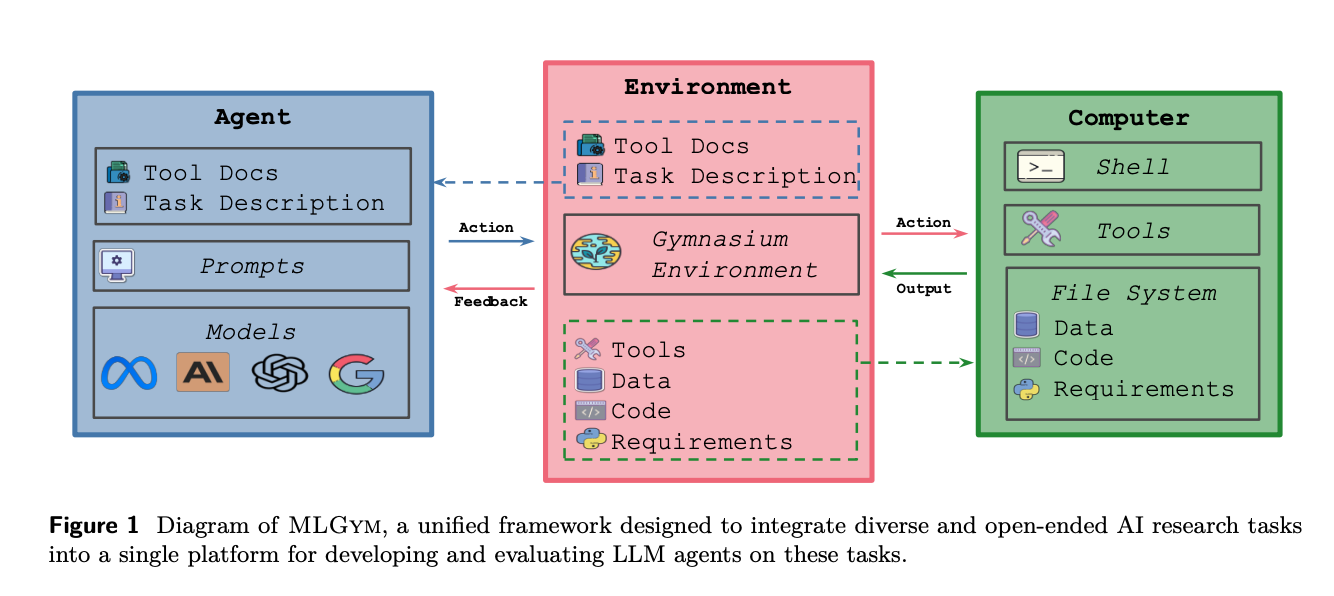
- MLGym은 AI 연구 에이전트를 평가하고 개발하기 위한 최초의 Gym 환경으로, 다양한 개방형 AI 연구 작업을 단일 플랫폼에 통합하도록 설계되었다.
- MLGym-Bench는 컴퓨터 비전, 자연어 처리, 강화 학습, 게임 이론 등 13개의 다양한 개방형 연구 과제를 포함하는 벤치마크 세트이다.
- 이 프레임워크는 강화 학습, 커리큘럼 학습, 개방형 학습 등 AI 연구 에이전트를 위한 다양한 훈련 알고리즘 연구를 가능하게 한다.
- MLGym은 모델 가중치, 강화 학습 알고리즘, 게임 이론 전략을 나타내는 코드 등 다양한 연구 결과물을 유연하게 평가할 수 있는 기능을 제공한다.
- 이 연구에서는 MLGym-Bench의 과제들에 대해 5개의 최신 대규모 언어 모델(LLM)을 일관된 실험 설정 하에 비교 평가하였다.
1.1. MLGym: AI 연구 에이전트 발전을 위한 새로운 프레임워크
- MLGym은 AI 연구 에이전트의 성능을 평가하고 발전시키기 위한 새로운 프레임워크와 벤치마크다.
- 이 프레임워크는 다양한 분야의 AI 연구 작업을 포함하여 모델 성능 비교와 평가를 가능하게 한다.
- MLGym 연구는 여러 대학과 Meta의 연구팀이 협력하여 수행한 것으로 추정된다.
- 이 연구는 AI가 과학적 발견을 가속화할 수 있는 잠재력을 보여주는 것을 목표로 한다.
1.2. MLGym과 MLGym-Bench: AI 연구 에이전트 평가 프레임워크
- MLGym과 MLGym-Bench는 AI 연구 작업에 대한 LLM 에이전트의 성능을 평가하고 개발하기 위한 새로운 프레임워크와 벤치마크다.
- 컴퓨터 비전, 자연어 처리, 강화 학습, 게임 이론 등 다양한 분야에서 13개의 개방형 AI 연구 과제로 구성되어 있다.
- 이 과제들은 새로운 아이디어 생성, 데이터 처리, ML 방법 구현, 모델 훈련, 실험 수행 등 실제 AI 연구 능력을 요구한다.
- Claude-3.5-Sonnet, Llama-3.1 405B, GPT-4, Gemini-1.5 Pro 등 최신 대규모 언어 모델들의 성능을 이 벤치마크로 평가했다.
- 현재 최신 모델들은 주로 하이퍼파라미터 최적화를 통해 기준선을 개선할 수 있지만, 새로운 가설이나 알고리즘, 아키텍처를 생성하지는 못한다.
1.3. AI 연구 에이전트의 장기적 비전과 평가 프레임워크의 필요성
- AI는 과학적 발견을 가속화할 잠재력이 있으며, 향후 AI 연구 에이전트는 문헌 검색부터 논문 작성까지 연구 과정 전반을 독립적으로 수행할 것으로 예상된다.
- AI 에이전트는 방대한 데이터셋 처리와 복잡한 패턴 인식 능력을 통해 약물 발견, 재료 과학 등 다양한 분야에서 과학적 돌파구를 가속화할 수 있다.
- 머신러닝 연구는 경험적 검증과 체계적인 실험을 강조하여 AI의 과학 연구 발전 가능성을 탐구하는 이상적인 테스트베드를 제공한다.
- 현재 개방형 AI 연구 과제에 대한 AI 에이전트의 능력을 평가하기 위한 포괄적인 프레임워크와 벤치마크가 부족한 상황이다.
- 기존의 벤치마크들은 개방형 연구 과제를 포함하지 않거나 제한된 연구 영역만을 다루고 있어, 다양한 도메인에서의 AI 연구 에이전트 평가에 한계가 있다.
1.4. MLGym: AI 연구 에이전트를 위한 혁신적 프레임워크

- MLGym은 AI 연구 에이전트를 위한 최초의 Gym 환경으로, 다양하고 개방형 AI 연구 작업을 단일 플랫폼에 통합한다.
- 이 프레임워크는 강화 학습, 커리큘럼 학습, 개방형 학습 등 다양한 훈련 알고리즘 연구를 가능하게 한다.
- MLGym-Bench는 13개의 개방형 연구 과제를 포함하며, 컴퓨터 비전, 자연어 처리, 강화 학습, 게임 이론 등 광범위한 분야를 다룬다.
- 현실적이고 다면적인 워크플로우에서 에이전트의 성능을 평가할 수 있도록 신중하게 설계되었다.
- 기존 LLM 에이전트 프레임워크와 벤치마크의 범위를 확장하여, 다양한 문제에 대한 유연한 성능 평가가 가능하다.
1.5. MLGym과 MLGym-Bench의 주요 특징 및 기여
- MLGym은 AI 연구 에이전트를 평가하고 개발하기 위한 최초의 Gym 환경으로, 다양한 오픈엔드 AI 연구 작업을 포함한 MLGym-Bench를 제공한다.
- 성능 측정은 모델 가중치, 강화학습 훈련 알고리즘, 게임 이론 전략을 나타내는 코드 등 다양한 산출물을 기반으로 이루어진다.
- 연구진은 최첨단 LLM 5개를 일관된 실험 설정 하에 MLGym-Bench 작업에서 비교하여 각 모델의 강점과 한계를 분석했다.
- 최적화 및 AutoML 문헌에서 채택한 새로운 평가 지표를 제안하여 서로 다른 성능 지표를 가진 작업에서 LLM 에이전트의 상대적 성능을 더 공정하게 평가할 수 있게 했다.
- MLGym은 연구자와 개발자가 새로운 작업, 에이전트 또는 모델을 쉽게 통합하고 평가할 수 있도록 설계되었다.
1.6. AI 연구 에이전트의 능력 수준 분류
- AI 연구를 가속화하기 위한 LLM 에이전트의 능력을 6단계로 분류하는 계층적 프레임워크를 제안한다.
- Level 0(재현)은 기존 연구 논문을 원본 코드 없이 재현할 수 있는 능력을 나타낸다.
- Level 1(기준선 개선)은 최첨단이 아닌 기준 코드를 바탕으로 벤치마크 성능을 향상시킬 수 있는 능력을 의미한다.
- Level 2(SOTA 달성)는 SOTA 논문이나 코드 없이 과제 설명과 기존 문헌만으로 SOTA 성능을 달성하는 능력을 나타낸다.
- Level 3(새로운 과학적 기여)부터 Level 5(장기 연구 의제)까지는 점진적으로 높은 수준의 과학적 기여와 연구 능력을 요구한다.
1.7. MLGym과 다른 AI 연구 프레임워크 비교
- MLGym은 Gym 인터페이스를 제공하는 최초의 AI 연구 에이전트 프레임워크로, 강화학습 알고리즘을 쉽게 통합하고 훈련할 수 있다.
- MLGym-Bench는 강화학습, 게임 이론, SAT 등 다양한 분야의 알고리즘 연구를 요구하는 작업을 포함하는 최초의 벤치마크다.
- MLGym-Bench는 지도학습, 언어 모델링, 강화학습, 게임 이론, SAT 등 광범위한 개방형 AI 연구 작업을 포함하고 있다.
- MLGym은 유연한 평가 아티팩트를 허용하여, 모델 체크포인트나 RL 알고리즘 등 현재 솔루션의 품질을 검사할 수 있는 파이썬 코드를 제공하는 것으로 충분하다.
- MLGym은 기본 에이전트 하네스를 제공하여 모델과 에이전트 모두를 쉽게 평가할 수 있게 한다.
2. MLGym: AI 연구를 위한 통합 프레임워크
- MLGym은 셸 환경과 상호작용하여 ML 연구/개발을 수행하는 프레임워크로, LLM 에이전트가 연구 목표를 달성하기 위해 적절한 명령을 생성한다.
- 이 프레임워크는 에이전트, 환경, 데이터셋, 작업의 4가지 핵심 구성 요소를 가지며, 연구자들이 쉽게 확장하고 활용할 수 있도록 설계되었다.
- MLGym은 다양한 기본 모델을 통합할 수 있는 Agent 클래스를 제공하며, 에이전트와 환경을 분리하여 외부 에이전트의 쉬운 통합과 공정한 비교를 가능하게 한다.
- 환경 구성 요소는 도커 컨테이너를 사용하여 안전하고 유연한 셸 환경을 초기화하고, 작업별 종속성 설치 및 필요한 데이터와 코드를 관리한다.
- MLGym은 데이터셋 정의를 작업 정의와 분리하여 유연성을 제공하며, 다양한 ML 연구 작업을 쉽게 정의할 수 있는 추상화를 제공한다.
2.1. MLGym: 쉘 환경을 통한 ML 연구 프레임워크
- MLGym은 쉘 환경과 상호작용하여 일련의 명령을 통해 ML 연구/개발을 수행하는 새로운 프레임워크이다.
- LLM은 주어진 작업 설명, 시작 코드, 행동 및 관찰 기록을 바탕으로 연구 목표를 달성하기 위한 적절한 쉘 명령을 생성한다.
- 에이전트는 작업 설명과 이전 명령의 실행 피드백을 기반으로 반복적으로 행동을 취하며, 이를 통해 맥락 내에서 솔루션을 개발하고 자체 개선할 수 있다.
- MLGym은 강화학습 분야에서 영감을 받아 로컬 도커 머신 쉘에서 명령을 실행할 수 있는 Gym 환경을 구축했다.
- 프레임워크는 에이전트, 환경, 데이터셋, 작업이라는 4가지 핵심 구성 요소를 제공하며, 연구자들이 쉽게 라이브러리를 활용하고 확장할 수 있도록 설계되었다.
2.2. MLGym의 Agent와 Environment 구성요소
- MLGym의 Agent 클래스는 기본 LLM을 래핑하고 다양한 기본 모델, 히스토리 프로세서, 비용 관리 기능을 통합하는 역할을 한다.
- Agent와 Environment를 분리하여 외부 에이전트의 쉬운 통합과 동일한 에이전트 하네스에서 다른 기본 모델의 공정한 비교가 가능하다.
- Agent는 이전 관찰과 행동의 기록을 입력으로 받아 다음 행동을 결정하며, Environment는 이를 실행하고 결과를 반환한다.
- Environment는 Gymnasium(gym) 환경으로 설계되어 도커 도구, 작업별 종속성 설치, 데이터 및 코드 복사, 에이전트와 시스템 간 상호작용을 관리한다.
- 보안을 위해 비루트 사용자 "agent"를 생성하고 작업 디렉토리에 적절한 권한을 설정하며, 도구와 ACI를 분리하여 다른 에이전트 아키텍처의 쉬운 구현을 가능하게 한다.
2.3. MLGym의 데이터셋과 작업 구성
- MLGym은 구성 파일을 통해 데이터셋을 정의하며, 로컬 저장소와 Hugging Face 데이터셋을 모두 지원한다.
- 데이터셋과 작업 정의를 분리하여 하나의 데이터셋을 여러 작업에서 사용할 수 있고, 하나의 작업에 여러 데이터셋을 적용할 수 있다.
- 로컬 데이터셋 파일은 읽기 전용 권한으로 에이전트 작업 공간에 자동 복사되어 재현성과 부정 방지를 보장한다.
- 작업은 구성 파일을 통해 정의되며, 여러 데이터셋, 맞춤형 평가 스크립트, 작업별 conda 환경, 선택적 시작 코드 등을 포함할 수 있다.
- 평가는 작업별로 다양한 프로토콜을 사용하며, 읽기 전용 평가 스크립트와 제출물 지침을 통해 개방형 작업에 대한 확장성을 보장한다.
2.4. ️ MLGym의 도구와 에이전트-컴퓨터 인터페이스(ACI)
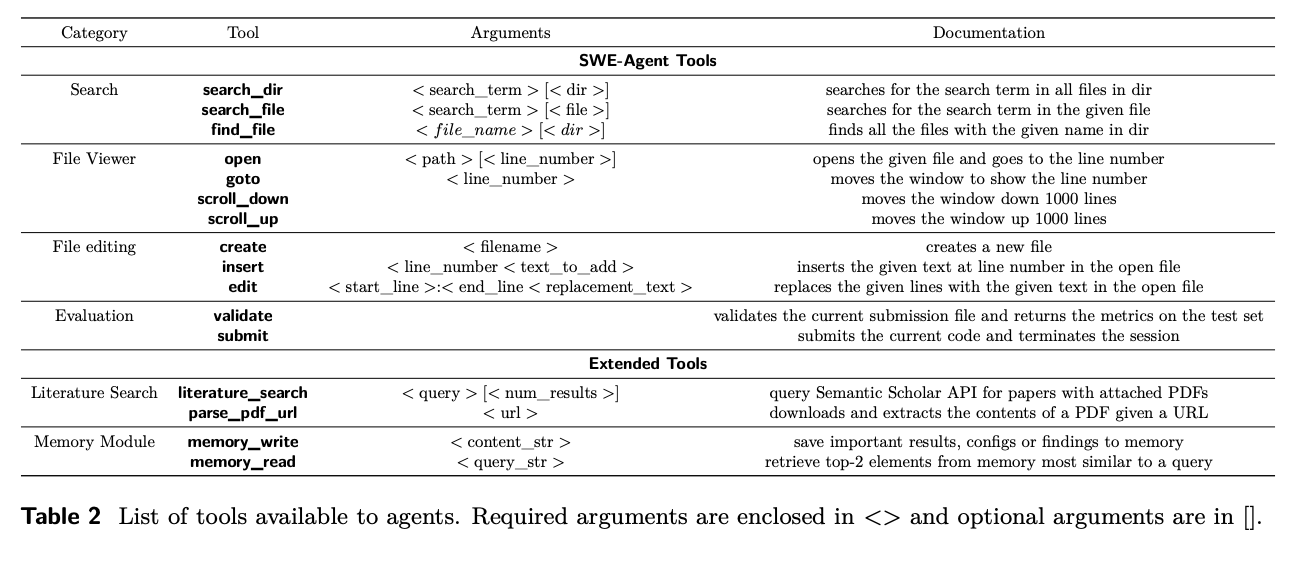
- MLGym은 외부 도구 사용 능력을 갖춘 LLM 에이전트를 통해 지식 집약적 작업의 진전을 도모한다.
- SWE-Agent에서 소개된 ACI를 확장하여 검색, 탐색, 파일 뷰어, 파일 편집, 컨텍스트 관리 기능을 개선하고, 문헌 검색과 메모리 모듈을 새롭게 추가했다.
- 도구들은 bash나 python 스크립트로 정의되며, 환경 내에서 bash 명령어로 사용 가능하다.
- 검증(validate) 및 제출(submit) 명령어를 통해 에이전트는 현재 성능을 테스트 세트에서 평가할 수 있으며, 지속적인 개선이 가능하다.
- 문헌 검색과 PDF 파서 도구를 통해 에이전트는 외부 소스에서 지식을 찾고 추출할 수 있으며, 이를 장기 작업을 위해 메모리 모듈에 저장할 수 있다.
2.5. 메모리 모듈: 장기 AI 연구 작업 성능 향상
- MLGym의 메모리 모듈은 장기 AI 연구 작업에서 에이전트의 성능을 향상시키는 중요한 도구다.
- 메모리 모듈은 구조화된 메모리 시스템을 사용하여 중요한 발견과 성공적인 훈련 구성을 지속적으로 저장할 수 있게 한다.
- `memory_write` 함수는 텍스트 데이터, 임베딩, 태그를 JSON 형식으로 저장하고, `memory_read` 함수는 주어진 쿼리와의 코사인 유사도를 기반으로 가장 관련성 높은 항목을 검색한다.
- 메모리 모듈을 사용하는 에이전트는 장기 작업에서 지속적인 진전을 보이며, 최적의 구성을 재사용하여 고정된 컨텍스트 윈도우로 제한된 에이전트보다 우수한 결과를 달성한다.
- 향후 개선 방향으로는 계층적 또는 관계형 모델과 같은 더 구조화된 메모리 형식 도입, 모델 훈련 과정에 메모리 작업 직접 통합, 메모리를 자동으로 관리하는 하위 에이전트 사용 등이 있다.
3. MLGym-Bench: 다양한 머신러닝 작업을 위한 벤치마크
- MLGym-Bench는 데이터 과학, 게임 이론, 컴퓨터 비전, 자연어 처리, 강화학습 등 다양한 머신러닝 분야의 과제를 포함하는 종합적인 벤치마크다.
- 각 과제는 실제 세계의 도전 과제를 대표하며, 모델의 일반화 능력과 다양한 시나리오에서의 효과적인 수행 능력을 테스트한다.
- 벤치마크의 모든 과제에는 표준화된 평가 스크립트와 기준 구현이 제공되어 성능 평가와 비교를 위한 명확한 기준점을 제공한다.
- 데이터 과학 분야에서는 Kaggle 주택 가격 데이터셋을 사용한 주택 가격 예측 과제가 포함되어 있으며, RMSE와 R2를 성능 지표로 사용한다.
- 게임 이론 분야에서는 반복 죄수의 딜레마, 성별 전투, 블로토 대령 게임 등이 포함되어 있으며, 각 게임에서 상대방의 전략에 대한 최적의 대응 전략을 개발하는 것이 목표다.
3.1. MLGym-Bench의 목표와 구조
- MLGym-Bench는 다양한 머신러닝 분야에서 모델의 능력을 평가하기 위해 설계된 새로운 벤치마크다.
- 데이터 과학, 게임 이론, 컴퓨터 비전, 자연어 처리, 강화 학습 등의 과제를 포함하여 포괄적인 에이전트 평가 테스트베드를 제공한다.
- 실제 세계의 도전 과제를 대표하는 과제들로 구성되어 있어, 모델의 일반화 능력과 다양한 시나리오에서의 효과적인 수행 능력을 테스트한다.
- 각 과제에는 표준화된 평가 스크립트와 기준 구현이 제공되어 성능 평가와 비교를 위한 명확한 참조점을 제공한다.
- 벤치마크 스위트는 데이터 과학, 게임 이론, 컴퓨터 비전, 자연어 처리의 4가지 주요 카테고리로 구성되어 있다.
3.2. 데이터 사이언스와 알고리즘 추론 과제
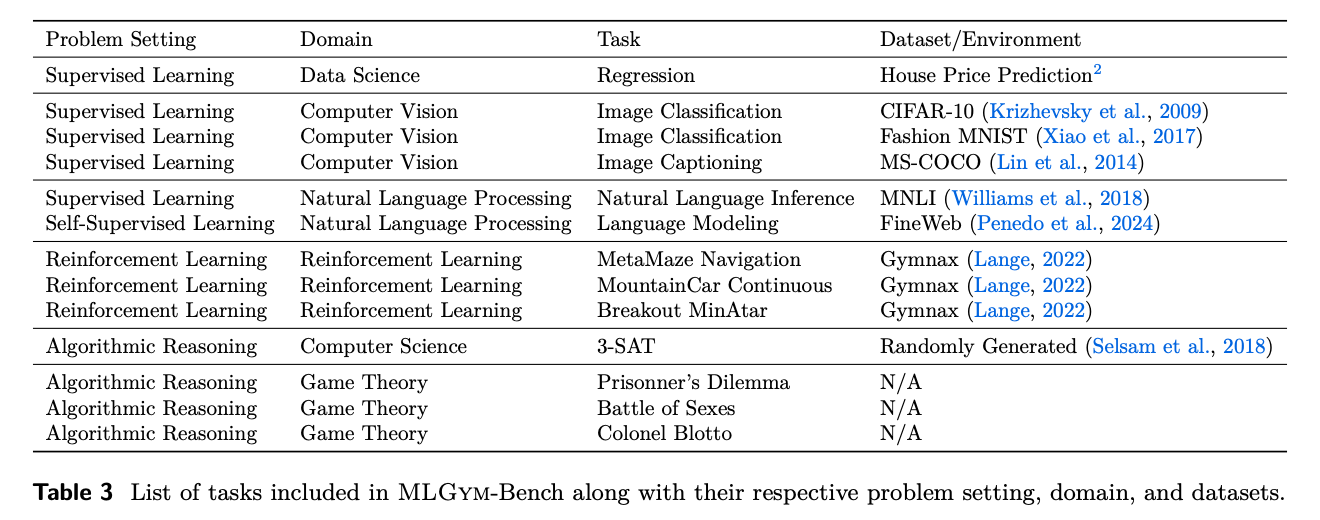
- House Price Prediction 과제는 Kaggle 주택 가격 데이터셋을 사용하여 주택 가격을 예측하는 것이 목표이며, RMSE와 R2를 성능 지표로 사용한다.
- 기준 모델로는 최소한의 특성 엔지니어링을 적용한 단순 Ridge Regression 모델이 사용된다.
- 3-SAT 과제에서는 LLM 에이전트가 DPLL 코드를 받아 변수 선택 휴리스틱을 최적화해야 하며, 코드는 읽기 전용 파일에 저장되어 있다.
- 3-SAT 과제의 성능은 100개의 생성된 3-SAT 인스턴스를 해결하는 데 걸리는 총 wall-clock 시간으로 측정된다.
- 기준 모델로는 단순 랜덤 선택 휴리스틱이 사용되며, 인스턴스는 Selsam et al. (2018)의 알고리즘을 사용하여 생성된다.
3.3. 반복 게임 이론과 전략적 의사결정
- 반복 게임에서는 플레이어들이 이전 라운드의 행동 기록을 바탕으로 다음 라운드의 전략을 결정한다.
- 죄수의 딜레마, 성별 전쟁, 블로토 대령 게임 등 다양한 유명 게임들이 반복 게임 형태로 구현되었다.
- 죄수의 딜레마에서는 상호 협력이 최선의 집단적 결과를 가져오지만, 개인의 이익은 배신을 유도하는 구조적 특성이 있다.
- 성별 전쟁 게임은 서로 다른 선호도를 가진 두 참가자 간의 조정 문제를 보여주는 간단한 게임이다.
- 블로토 대령 게임은 제한된 자원을 여러 전장에 전략적으로 배분하는 모델로, 다양화와 예측 불가능성의 중요성을 강조한다.
3.4. ️ 컴퓨터 비전과 자연어 처리 작업
- CIFAR-10 데이터셋을 사용한 이미지 분류 작업은 모델의 시각적 패턴 및 특징 학습 능력을 테스트하며, 기준 정확도는 49.71%이다.
- Fashion MNIST 데이터셋을 활용한 패션 아이템 분류 작업에서는 간단한 2층 CNN을 기준으로 제공하며, 에이전트는 모델 구조와 훈련 하이퍼파라미터를 최적화해야 한다.
- MS-COCO 데이터셋을 사용한 이미지 캡셔닝 작업에서는 에이전트가 모델링 코드를 작성하고 이미지-텍스트 쌍에 대한 적절한 아키텍처와 훈련 설정을 개발해야 하며, BLEU 점수로 성능을 평가한다.
- 자연어 처리 분야에서는 자연어 이해(NLU)와 자연어 생성(NLG) 능력을 테스트하며, MNLI 벤치마크에서 사전 훈련된 BERT 모델의 미세 조정 전략을 최적화하는 작업이 포함된다.
- 언어 모델링 작업에서는 FineWeb 데이터셋의 축소 버전을 사용하여 다음 토큰 예측을 위한 언어 모델을 훈련해야 하며, NanoGPT 코드베이스를 기준점으로 제공한다.
3.5. 강화학습 환경 및 작업 소개
- MetaMaze Navigation 작업은 에이전트가 지역 관찰을 사용하여 격자 세계 환경을 탐색하고 목표 위치에 도달해야 하는 시뮬레이션이다.
- Mountain Car Continuous 환경에서는 연속 제어 환경에서 가파른 언덕을 오르는 자동차를 운전하는 정책을 학습하는 것이 목표다.
- Breakout MinAtar 작업은 시뮬레이션 환경에서 아케이드 게임 Breakout을 플레이하는 것으로, 강화학습 알고리즘을 평가하는 데 널리 사용되는 벤치마크다.
- 이러한 다양한 환경들은 MLGym-Bench에 포함되어 있어 AI 연구 에이전트의 성능을 평가하고 비교하는 데 활용된다.
- 각 작업은 서로 다른 특성을 가지고 있어 에이전트의 다양한 능력을 테스트하는 데 적합하다.
4. 실험 설정 및 모델 비교
- SWE-Agent 기반 모델을 MLGYM 환경에 맞게 조정하여 실험을 진행했다. 이 에이전트는 ReAct 스타일의 루프를 따르며 ML 연구자로서 행동하도록 설계되었다.
- 실험에는 OpenAI O1-preview, Gemini 1.5 Pro, Claude-3.5-sonnet, Llama-3-405b-instruct, GPT-4o 등 5개의 최신 모델이 사용되었다.
- MLGYM 환경은 1000줄 크기의 창과 2줄 겹침, 5개의 최근 상호작용 유지, 특수 명령어 세트 등으로 구성되었다. 에이전트는 50단계로 제한되며 특정 시간 제한이 설정되었다.
- 성능 평가를 위해 성능 프로파일 곡선과 AUP 점수를 사용했다. 이는 다양한 작업에서 방법들의 상대적 성능 향상을 비교할 수 있게 해준다.
- 실험 결과, OpenAI O1-preview가 전반적으로 가장 우수한 성능을 보였으며, Gemini 1.5 Pro와 Claude-3.5-Sonnet이 그 뒤를 이었다.
4.1. 실험 설정 및 사용된 모델
- MLGym 환경에 맞춰 조정된 SWE-Agent 기반 모델을 사용하며, 이는 ReAct 스타일 루프를 따라 ML 연구원으로서 행동하도록 설계되었다.
- 실험에는 OpenAI O1-preview, Gemini 1.5 Pro, Claude-3.5-sonnet, Llama-3-405b-instruct, GPT-4o와 같은 5개의 최신 모델이 사용되었다.
- 대부분의 모델은 temperature=0.0, top-p=0.95 설정으로 사용되었으나, OpenAI O1-preview는 기본 temperature=1.0으로 설정되어 있고 디코딩 매개변수 변경을 지원하지 않는다.
- 강화학습(RL) 작업에는 Gymnax 라이브러리의 환경과 Gymnax-blines4의 PPO 알고리즘이 기준선 및 LLM 에이전트의 시작 코드로 사용되었다.
- SWE-Agent는 단일 명령어를 사용하며, Python REPL이나 vim과 같은 대화형 세션 명령어는 사용이 허용되지 않는다.
4.2. ️ MLGYM 환경 구성 및 상호작용 방식
- MLGYM 환경은 1000줄의 윈도우 크기와 2줄의 중첩을 사용하여 큰 파일의 탐색과 편집을 효과적으로 지원한다.
- 컨텍스트 관리를 위해 최근 5개의 상호작용(행동과 관찰)을 유지하는 롤링 윈도우 시스템을 사용한다.
- 환경은 파일 탐색, 편집, 검색, 평가 등을 위한 특수 명령어를 제공하며, 이는 표준 bash 작업을 넘어선다.
- 에이전트는 50단계로 제한되며, 마지막 코드베이스 상태는 자동 제출된다.
- 모델의 무분별한 매개변수 증가를 방지하기 위해 작업별 타임아웃이 설정되어 있다.
4.3. 성능 평가 방법론: 성능 프로파일과 AUP 점수

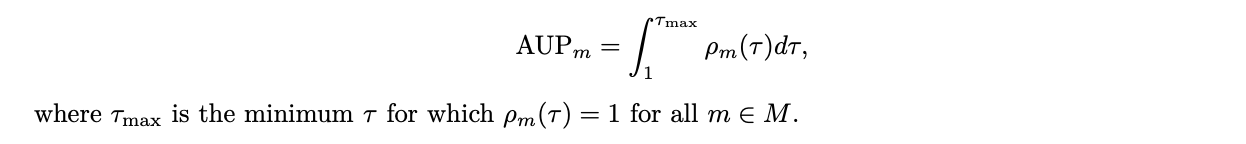
- 성능 프로파일 곡선은 다양한 작업과 방법론 간의 상대적 성능 향상을 비교하는 데 사용되며, 각 방법에 대해 더 높은 곡선이 더 나은 성능을 의미한다.
- AUP(Area Under the Performance Profile) 점수는 성능 프로파일 곡선 아래의 면적을 계산하여 각 방법의 직접적인 순위를 매기는 데 사용된다.
- MLGym에서는 성능 프로파일과 AUP 점수를 다양한 엣지 케이스를 처리할 수 있도록 조정했으며, 이는 메트릭 방향 처리와 실행 불가능한 방법 처리를 포함한다.
- 각 모델에 대해 최종 제출 기준 성능 프로파일(ρbs)과 최고 시도 기준 성능 프로파일(ρba)을 별도로 계산하여 모델의 일관성과 탐색 능력을 평가한다.
- 이러한 평가 방법론은 다양한 작업에서 AI 연구 에이전트의 성능을 공정하고 포괄적으로 비교할 수 있게 해준다.
4.4. 실험 결과: 모델 성능 비교 및 분석
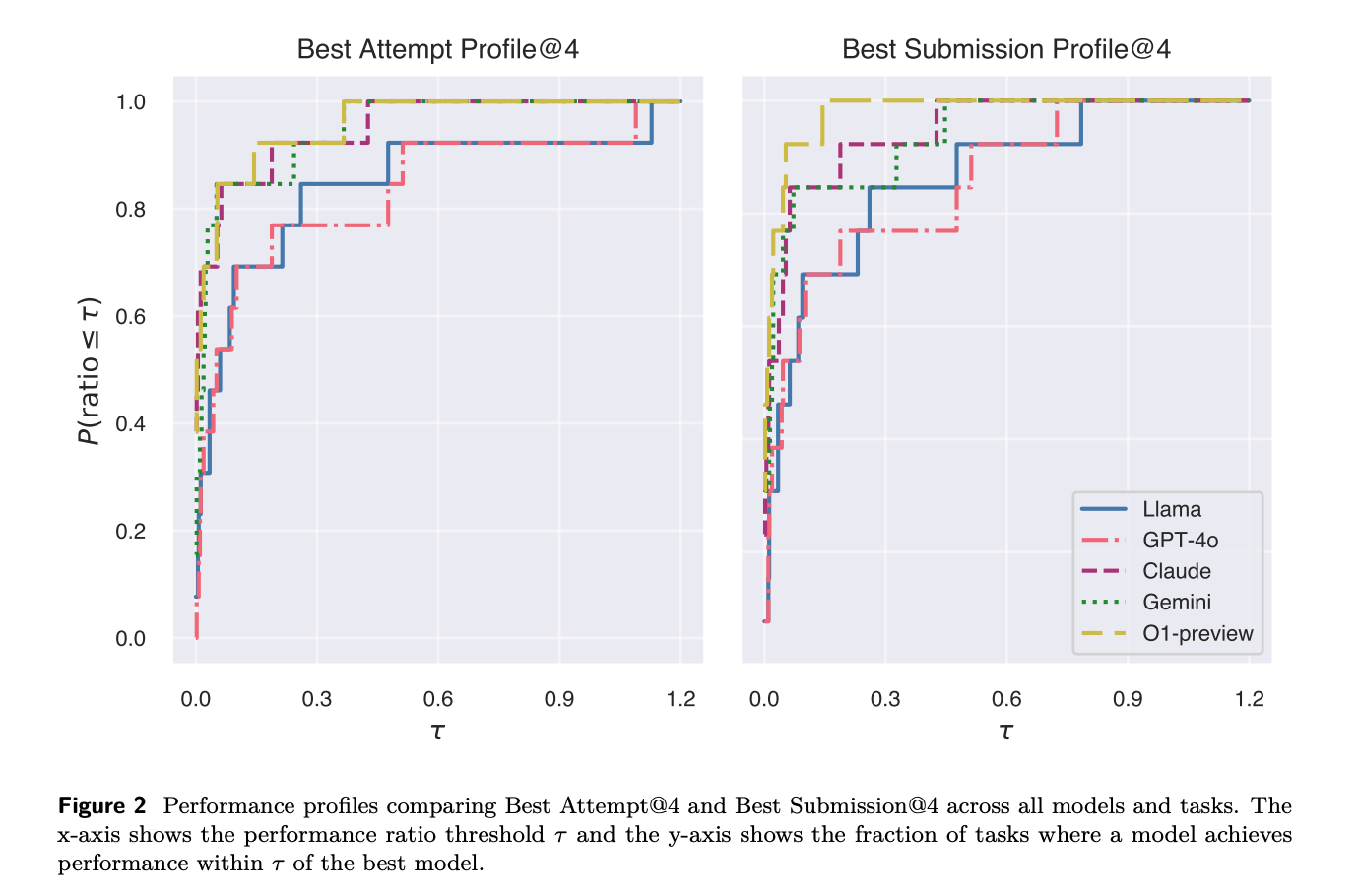
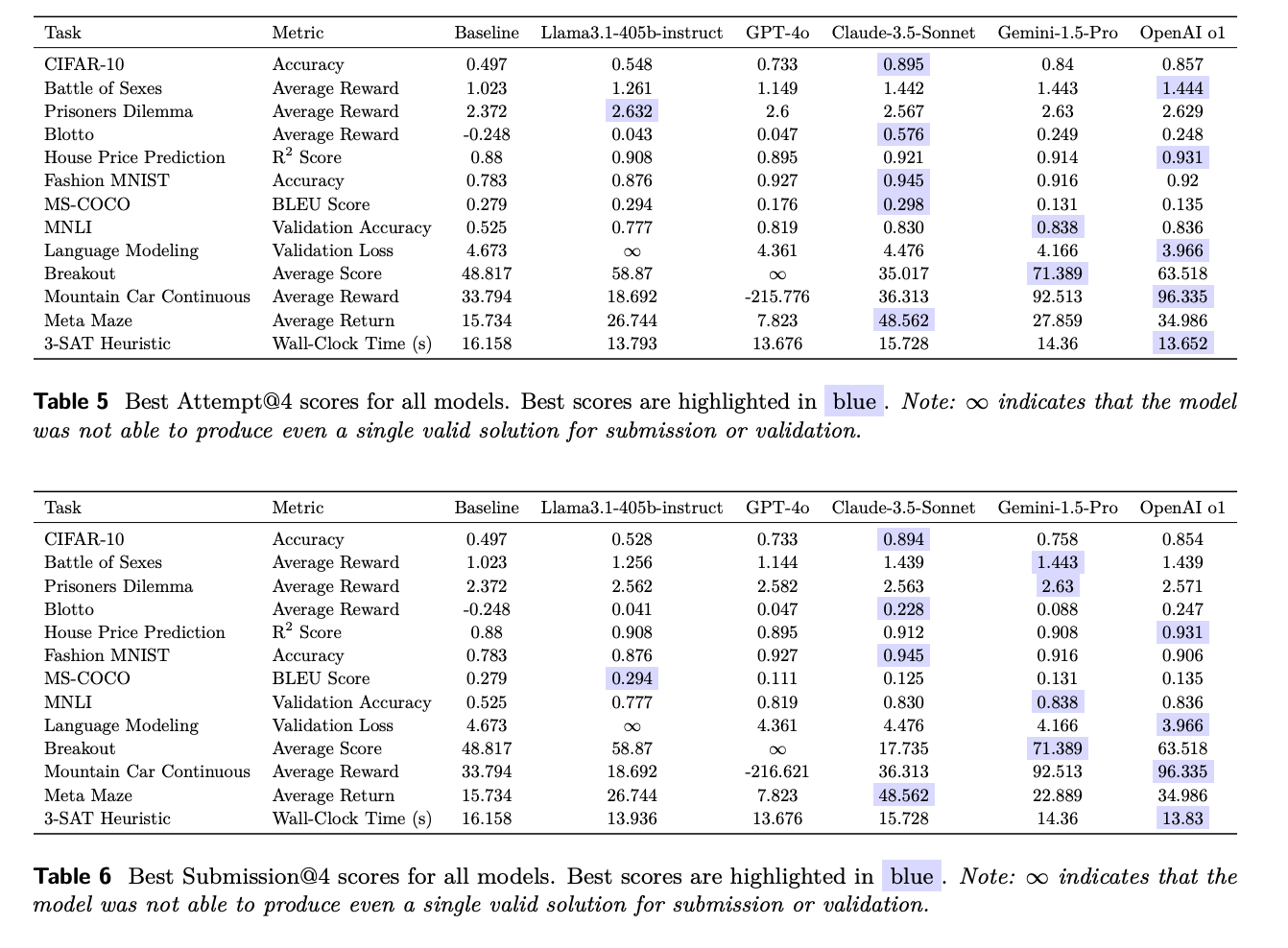
- AUP 점수와 성능 프로파일을 사용하여 각 모델의 성능을 평가했으며, 최고 시도(Best Attempt)와 최고 제출(Best Submission) 두 가지 범주로 구분하여 분석했다.
- OpenAI O1-preview가 전반적으로 가장 우수한 성능을 보였으며, Gemini 1.5 Pro와 Claude-3.5-Sonnet이 그 뒤를 이었다.
- 성능 프로파일 그래프를 통해 각 모델의 성능을 시각적으로 비교할 수 있으며, 이는 다양한 메트릭을 가진 작업들에서 모델 간 성능을 비교하는 데 효과적인 방법이다.
- 일부 작업에서는 Gemini-1.5-Pro, Claude-3.5-Sonnet, Llama-3.1-405b-Instruct가 더 나은 성능을 보이기도 했지만, OpenAI O1-Preview가 대부분의 작업에서 상위권을 유지했다.
- Llama-3.1-405b-Instruct와 GPT-4o는 각각 언어 모델링과 Breakout 작업에서 유효한 해결책을 제시하지 못하는 한계를 보였다.

4.5. 모델 성능과 비용의 균형 분석
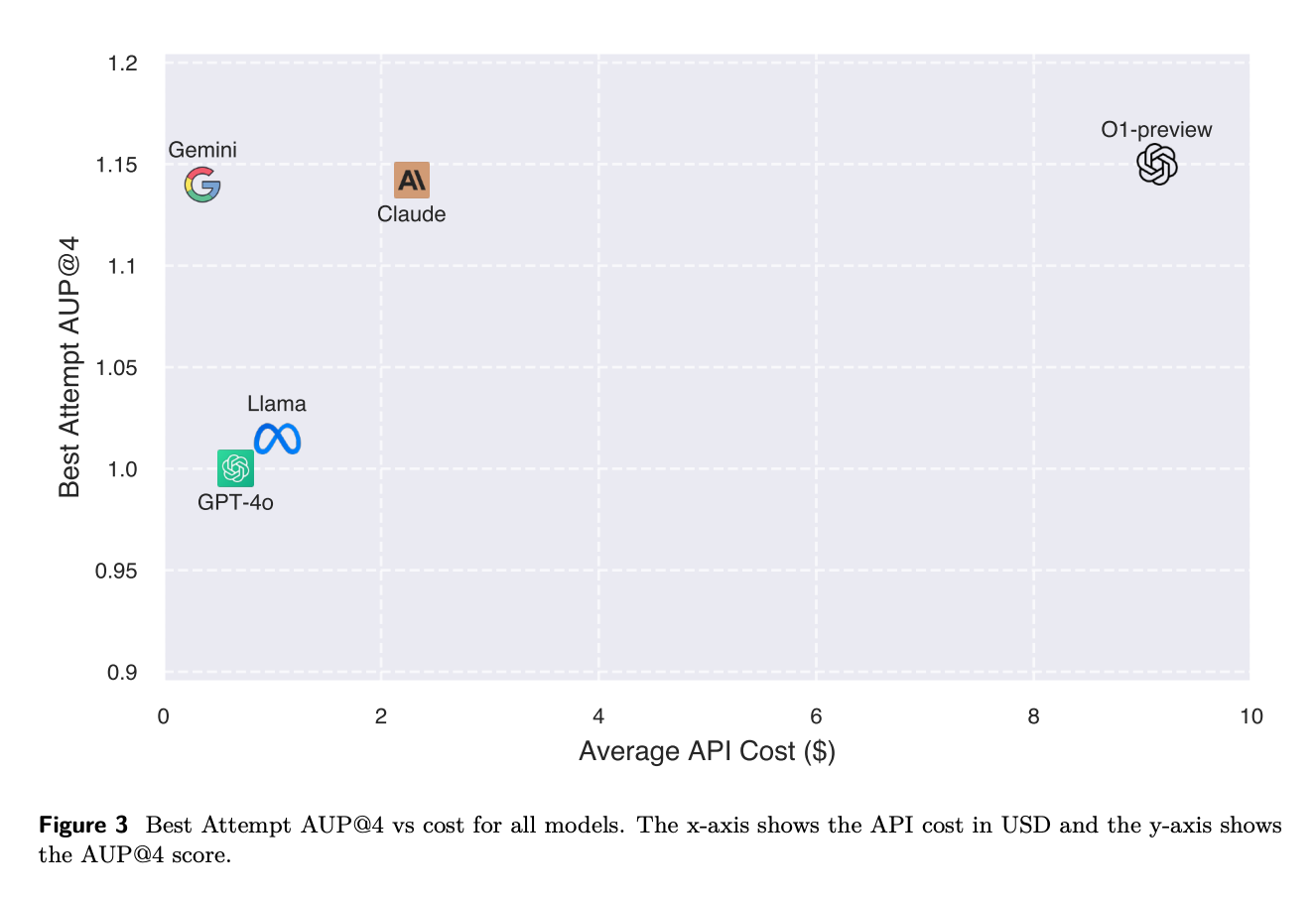
- 성능 대비 비용의 파레토 곡선을 통해 에이전트의 능력과 계산 비용을 종합적으로 평가한다.
- OpenAI O1-Preview는 최고 성능을 보이지만, 계산 비용이 가장 높은 모델이다.
- Gemini-1.5-Pro와 Claude-3.5-Sonnet은 O1에 근접한 높은 성능을 보이면서도 훨씬 더 비용 효율적이다.
- Gemini-1.5-Pro는 GPT-4o와 Llama-3.1-405b-Instruct보다 저렴하면서도 성능이 크게 향상되었다.
- 전반적으로 Gemini-1.5-Pro가 MLGym-Bench에서 성능과 비용 사이의 최적의 균형을 보여주며, O1보다 약 9배 저렴하면서 99% 수준의 AUP를 달성했다.
5. MLGym 프레임워크의 명령어 및 사용 지침
- MLGym은 파일 편집기와 특수 명령어를 포함한 커맨드 라인 인터페이스를 제공한다.
- 주요 명령어로는 파일 열기(open), 이동(goto), 스크롤(scroll_down/up), 파일 생성(create), 검색(search_dir/file), 편집(edit), 삽입(insert), 제출(submit), 검증(validate) 등이 있다.
- 응답 형식은 토론(DISCUSSION)과 명령(command) 필드로 구성되며, 한 번에 하나의 명령만 실행해야 한다.
- 목표는 최고 점수를 달성하는 것으로, 다양한 전략을 시도하고 'validate' 명령으로 검증한 후 최종 해결책을 'submit' 명령으로 제출해야 한다.
- 파일 편집 시 들여쓰기에 주의해야 하며, 베이스라인 스크립트 이해, 명령어 오류 시 수정, 효율적인 파일 탐색 등의 팁을 제공한다.
5.1. 에이전트 행동 분석 및 실패 모드
- API 가격 정보는 각 모델의 가격 페이지에서 확인했으며, Llama-3.1-405b-instruct 모델의 경우 together.ai에서 정보를 얻었다.
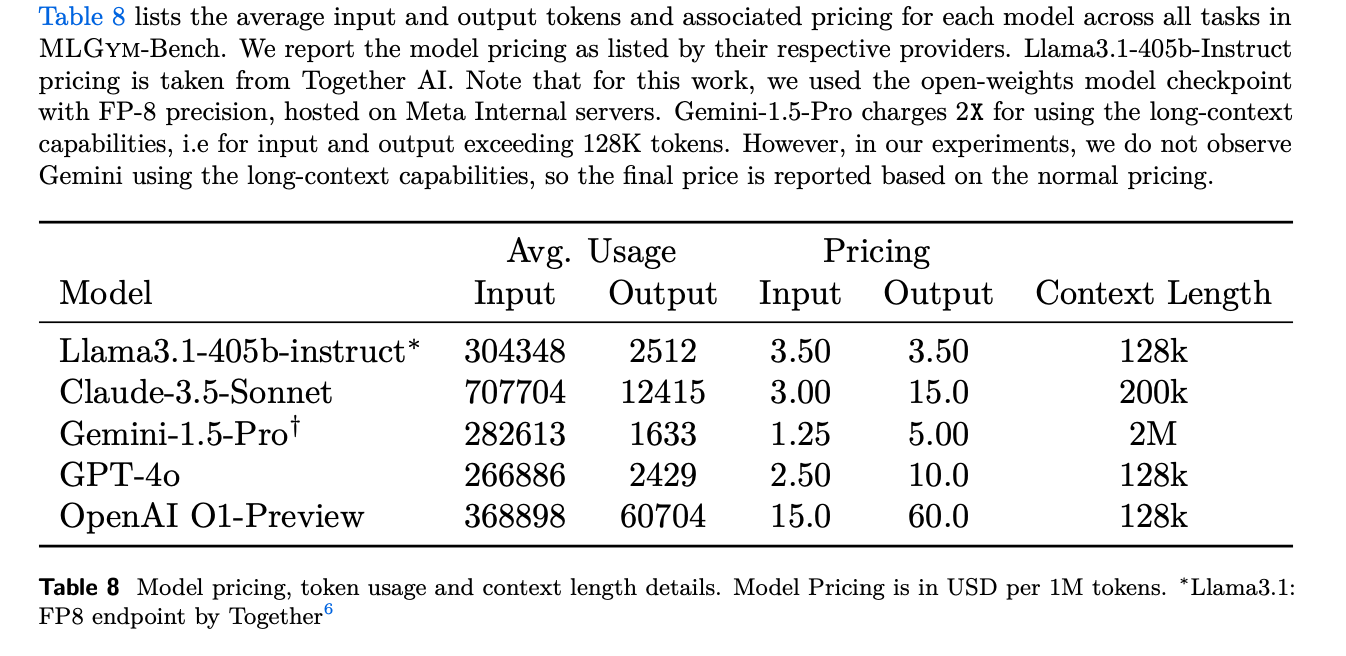
- API 가격, 사용된 토큰 수, 컨텍스트 길이에 대한 자세한 정보는 Table 8에서 확인할 수 있다.
- 에이전트의 행동을 분석하기 위해 실패 모드 분석이 수행되었다.
- 이 분석은 MLGym 프레임워크를 사용한 대규모 언어 모델(LLM) 에이전트의 성능 평가 맥락에서 이루어졌다.
- 이러한 분석을 통해 LLM의 다양한 과학적 워크플로우 처리 능력과 한계를 평가하는 것이 목표로 추정된다.
5.2. 에이전트 실패 모드 분석
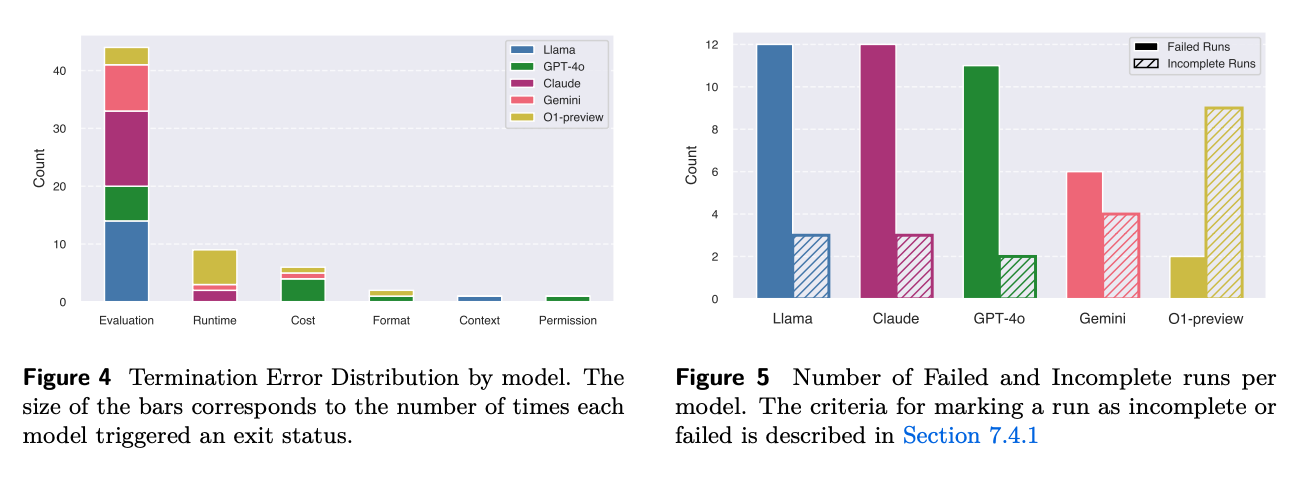
- MLGym-Bench 작업에서 에이전트의 실패 모드를 종료 오류 분포, 실패 또는 불완전 실행률, 작업별 실패 패턴의 세 가지 관점에서 분석했다.
- 11개 작업과 5개 모델에 대해 4개의 시드로 총 220개의 궤적을 수집했으며, 각 작업과 모델에 대해 20개와 44개의 궤적을 얻었다.
- 평가 오류가 전체 종료 오류의 75%를 차지하며 가장 빈번한 최종 오류로 나타났다.
- Gemini-1.5-Pro는 유일하게 잘못된 솔루션을 제출하지 않았으며, OpenAI O1-Preview와 Claude-3.5-Sonnet이 그 뒤를 이었다. [5-9]
- GPT-4o는 가장 높은 실패율을 보인 반면, Gemini-1.5-Pro와 OpenAI O1-Preview는 가장 높은 완료율을 달성했다.
5.3. 에이전트 행동 분석 및 분포
- 에이전트의 행동은 Edit, View, Search, Validate, Submit 등의 카테고리로 분류되며, Python과 Bash 명령어도 별도로 구분된다.
- 파일 편집(Edit)과 보기(View) 명령어가 전체 행동의 약 50%를 차지하여 가장 빈번히 사용되며, 이는 에이전트가 반복적인 개발 주기에 많은 시간을 할애함을 시사한다.
- Python 명령어와 Validate 명령어가 자주 사용되는 것으로 보아, 에이전트들이 정기적인 실험 평가와 주기적인 해결책 검증을 수행하는 경향이 있다.
- Search 명령어는 전체 행동의 약 1%로 가장 적게 사용되어, 에이전트들이 정보 검색보다는 직접적인 파일 조작에 집중하는 것으로 보인다.
- 모델별 행동 분포를 보면, Claude, Llama, Gemini, GPT-4 등 다양한 모델이 사용되었으며, 각 모델마다 Edit, Validate, View, Bash, Submit 등의 명령어 사용 빈도에 차이가 있다.
5.4. 모델별 행동 분포 및 궤적 분석
- 모델별 행동 분포를 분석한 결과, GPT-4는 전체적으로 가장 적은 수의 행동을 수행하며, 이는 오류 발생 또는 최적의 해결책에 도달하기 전 조기 제출을 의미한다.
- 최고 성능 모델 중 Claude-3.5-Sonnet과 OpenAI O1-Preview는 실행당 가장 많은 행동을 수행하는 반면, Gemini-1.5-Pro는 가장 적은 행동을 수행하여 비용 효율성이 가장 높다.
- 궤적 단계별 행동 분포를 보면, 초기에는 명령어 사용이 주를 이루다가 점차 Edit 행동이 가장 빈번해지며, 이는 코드 수정과 개선에 집중하는 패턴을 보여준다.
- Python과 Validate 명령어는 전 과정에 걸쳐 꾸준히 사용되어 실험과 평가의 반복적 주기를 나타내며, Submit 행동은 주로 과정 후반부에 나타나지만 일부 모델은 조기에 제출하는 경향을 보인다.
- 전반적으로 에이전트들은 환경 파악, 반복적 실험 및 검증, 최종 제출의 구조화된 접근 방식을 보이며, Search 명령어 사용 빈도가 낮아 코드 편집 효율성 향상을 위한 개선이 필요할 것으로 보인다.
5.5. LLM 에이전트의 과학적 워크플로우 활용
- MLGym 프레임워크와 MLGym-Bench 작업을 통해 현대 LLM 에이전트가 다양한 정량적 실험을 성공적으로 수행할 수 있음을 입증했다.
- 에이전트의 AI 연구 능력을 더욱 평가하기 위해 대규모 도메인별 데이터셋과 더 복잡한 작업, AI 외 분야로 평가 프레임워크를 확장할 필요가 있다.
- 방법 평가 단계에서는 새로운 방법의 일반화 가능성을 자동으로 평가하고, 다양한 도메인에 적용해 보는 접근이 필요하다.
- 과학적 '새로움'과 '발견'의 개념을 에이전트에 적합한 형태로 정의하고 자동화하는 것은 아직 명확하지 않다.
- 데이터 개방성이 과학적 진보를 촉진하는 데 중요하며, 재현 가능한 코드와 도메인별 데이터를 포함한 '세계의 대표적 말뭉치'를 널리 접근 가능하게 만드는 것이 협력과 발견을 가속화할 수 있다.
5.6. AI 연구 에이전트의 윤리적 고려사항과 영향
- AI 에이전트가 과학 연구를 수행할 수 있게 되면 과학적 발전이 급격히 가속화될 수 있다.
- MLGym-Bench는 OpenAI, Anthropic, Google DeepMind 등의 AI 안전 정책 프레임워크에서 모델 자율성을 측정하는 지표로 활용될 수 있다.
- AI 연구 에이전트의 발전은 의료, 기후 과학 등 다양한 분야의 발전과 경제 성장을 촉진할 수 있지만, 동시에 위험성도 존재한다.
- AI 모델의 능력이 인간의 이해 속도를 넘어설 경우, 재앙적 피해나 오용 가능성이 있는 모델이 개발될 수 있다.
- MLGym과 MLGym-Bench를 오픈소스로 공개함으로써 AI 연구 에이전트의 능력에 대한 이해와 연구를 촉진하고, 최첨단 AI 연구소의 가속화 위험에 대한 투명성을 높이고자 한다.
5.7. AI 연구 에이전트의 발전 방향과 잠재력
- MLGym과 MLGym-Bench는 AI 연구를 위한 LLM 에이전트를 구축하는 초기 단계로 소개되었다.
- 장문 맥락 추론, 더 나은 에이전트 아키텍처, 훈련 및 추론 알고리즘의 개선이 필요하다.
- 더 풍부한 평가 방법론 개발이 AI의 과학적 발견 잠재력을 완전히 활용하는 데 필수적이다.
- 다양한 분야의 연구자들 간 협력을 통해 AI 주도 에이전트가 과학 연구를 의미 있게 가속화할 수 있는 미래로 나아갈 수 있다.
- 특히 최첨단 모델 훈련 워크플로우에 맞춘 자동화된 AI 연구 능력에 대한 평가가 중요하다.
5.8. 연구 기여자 및 감사의 말
- 과학적 발견의 검증 가능성, 재현성, 무결성을 유지하는 것의 중요성을 강조한다.
- Sten Sootla, Mikayel Samvelyan, Sharath Chandra Raparthy, Mike Plekhanov, Rishi Hazra 연구자들은 AI 연구 에이전트의 평가와 개발에 대해 통찰력 있는 논의를 제공했다.
5.9. 참고 문헌 목록
- 인공지능, 기계학습, 강화학습, 대규모 언어 모델, 에이전트 시스템 등 다양한 주제의 연구들이 포함되어 있다.
- 최근의 연구 동향을 반영하는 2023년, 2024년 발표된 논문들이 다수 포함되어 있다.
- 인용된 연구들은 MLGym, MLGym-Bench 등 본 논문에서 제안하는 프레임워크와 관련된 기존 연구들을 포괄하고 있는 것으로 보인다.




댓글