원문: https://arxiv.org/pdf/2501.13200
이 논문은 다중 에이전트 강화 학습 (MARL) 환경에서 에이전트 간의 효과적인 협력을 위한 공유 메모리 접근법을 제안한다. 이는 에이전트들이 서로의 정보를 교환하고 행동을 조정할 수 있는 메커니즘으로, Shared Recurrent Memory Transformer (SRMT) 를 통해 구현된다. 실험 결과, SRMT는 다양한 벤치마크 문제에서 기존 접근 방식보다 뛰어난 성능을 보여주었다. 특히, 희소한 보상 상황에서도 안정적인 성과를 기록하며, 그 성과는 훈련된 길이보다 긴 경로에서도 유효했다.
1. 다중 에이전트 환경에서의 협력적 강화 학습 접근법
다중 에이전트 강화 학습(MARL)은 협력적 및 경쟁적 다중 에이전트 문제를 해결하는 데 있어 큰 진전을 보이고 있다.
에이전트의 행동을 명시적으로 예측해야 하는 것은 MARL에서 주요 문제 중 하나이다.
이를 해결하기 위해 공유 순환 메모리 변환기(SRMT)를 제안하며, 개별 작업 메모리를 풀링하고 전역적으로 방송하여 에이전트가 암시적으로 정보를 교환하고 행동을 조정할 수 있게 한다.
Bottleneck 및 POGEMA 벤치마크 설정에서 SRMT는 희소한 보상 상황에서도 기존 강화 학습 기준보다 성능이 우수하며, 훈련되지 않은 더 긴 복도에도 효과적으로 일반화된다.
공동 활용되는 순환 메모리를 변환기 기반 아키텍처에 통합하면 비중앙화 다중 에이전트 시스템에서의 협력을 강화할 수 있다.
* 다중 에이전트 강화 학습(MARL): 여러 에이전트가 공동으로 작업하거나 경쟁하는 환경에서 학습하는 방법입니다. 이것은 사람들 간의 팀워크와 비슷하게 작동합니다. 예를 들어, 여러 명이 함께 운동을 하면서 각자의 역할을 맡고 협력하여 목표를 달성하는 모습처럼, 여러 에이전트가 함께 문제를 해결하기 위해 상호작용합니다.
* SRMT: Shared Recurrent Memory Transformer의 약자로, 서로 다른 에이전트들이 정보를 공유하고 협력하는 데 도움을 주는 시스템입니다. 이는 에이전트가 독립적으로 행동하면서도 서로의 기억을 참조하여 더 나은 결정을 내릴 수 있도록 합니다. 쉽게 말해, SRMT는 마치 팀 스포츠에서 선수들이 서로의 위치를 알고 최선의 패스를 선택하는 것과 같습니다.
2. 다중 에이전트 시스템을 위한 공유 메모리 접근법
다중 에이전트 시스템은 분산된 지능과 협력을 통해 복잡한 문제를 해결할 잠재력을 지니고 있다.
기존의 다중 에이전트 간 상호 작용을 조정하는 것은 도전적이기 때문에, 이를 해결하기 위한 새로운 접근법으로 공유 메모리를 제안한다.
제안된 접근법은 글로벌 워크스페이스 이론에서 영감을 받아, 에이전트들을 독립적인 모듈로 보고 공유 메모리를 통해 조정을 개선하고 데드락을 방지하려는 것이다.
Shared Recurrent Memory Transformer (SRMT) 는 메모리 변환기를 다중 에이전트 환경에 맞춰 확장하여 에이전트들의 개별 작업 메모리를 풀링하고 글로벌로 전송한다.
SRMT는 부분적으로 관찰 가능한 다중 에이전트 경로 찾기 문제에서 에이전트 간 정보 교환을 통해 조정 능력을 향상시키며, 특히 보틀넥 내비게이션 상황에서 다른 강화 학습 기법보다 일관된 성과를 보인다.
3. 다중 에이전트 환경에서의 통신 및 메모리 활용
공유 메모리는 에이전트가 행동을 조정하기 위해 설계되며, 이는 다중 에이전트 강화 학습(MARL)에서 에이전트 간의 통신과 밀접하게 관련되어 있다.
MARL에서 에이전트 통신 프로토콜 제공은 큰 과제로, 중앙집중식, 완전 분산식, 네트워크 연결된 에이전트 등 다양한 접근법이 사용된다.
분산형 접근법은 로컬 정보에 기반하여 의사 결정을 하며, IQL, VDN, QMIX 등은 개인 Q함수를 사용하지만 중앙집중식 학습을 경험한다.
중앙집중식 접근법은 검색 기반 계획자(LaCAM, RHCR 등)를 사용하며, 통신을 통한 정보 공유는 에이전트의 협력을 강화한다.
공유 재귀 메모리 변환기(SRMT)는 다중 에이전트 환경에서 에이전트들이 네트워크로 연결된 환경에서 간접적으로 통신할 수 있게 하며, 이는 중앙집중식과 무관하게 훈련과 실행을 지속할 수 있게 한다.
4. 다중 에이전트 경로 찾기 및 SRMT의 성능
에이전트는 부분적으로 관찰 가능한 탈중앙화된 다중 에이전트 경로 찾기 (PO-MAPF) 환경에서 독립적으로 행동하며 보상을 수집한다.
Shared Recurrent Memory Transformer (SRMT)는 에이전트의 개인 메모리와 관찰 기록, 현재 관찰을 결합하여 셀프 어텐션을 통해 처리하며, 글로벌 컨텍스트를 결정 과정에 통합한다.
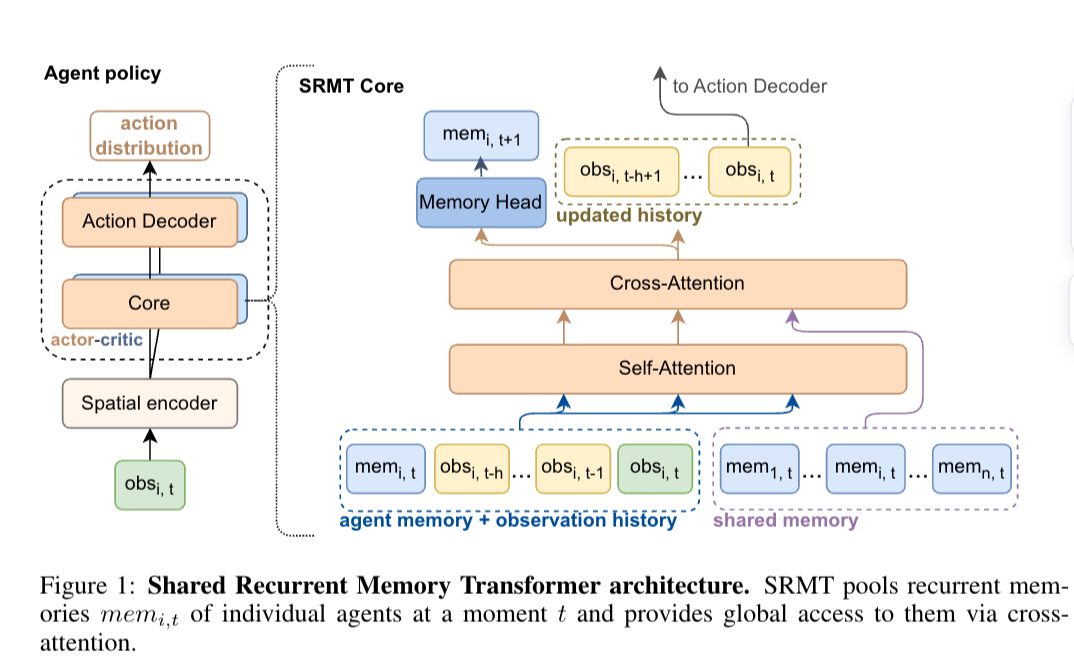
SRMT의 결과물은 에이전트의 행동을 생성하는 정책 모델의 디코더 부분으로 전달된다.
PO-MAPF 환경에서, 각 에이전트는 협력하여 경로찾기 작업을 수행하며, 다른 에이전트와 충돌 없이 목표에 도달하는 것이 목표이다.
SRMT는 다양한 보상 설정(예: sparsate 보상) 하에서도 다른 접근 방식보다 뛰어난 성능을 보이며 이로 인해 글로벌 정보 교환의 중요성이 강조된다.
4.1. MARL의 진보와 협력 문제
다중 에이전트 강화 학습(MARL)은 여러 환경에서 협력과 경쟁 문제가 해결될 수 있음을 보여준다.
MARL에서 가장 큰 도전 과제 중 하나는 에이전트 간 명시적인 협력 필요성이다.
MARL은 다양한 환경에서 다중 에이전트 문제 해결에서 큰 발전을 이루고 있다.
4.2. 다중 에이전트 강화 학습에서의 협력적 행동 및 정보 교환
Shared Recurrent Memory Transformer (SRMT)는 에이전트의 행동을 예상하고 협력을 증진시키기 위해 제안된 방법이다.
SRMT는 개별 에이전트의 작동 메모리를 풀로 모아 전 세계에 방송함으로써, 에이전트들이 정보를 암묵적으로 교환하고 행동을 조정할 수 있게 한다.
이 방법은 부분적으로 관측 가능한 다중 에이전트 경로 찾기 문제에서 평가되었다.
4.3. SRMT를 통한 다중 에이전트 시스템의 협력 향상
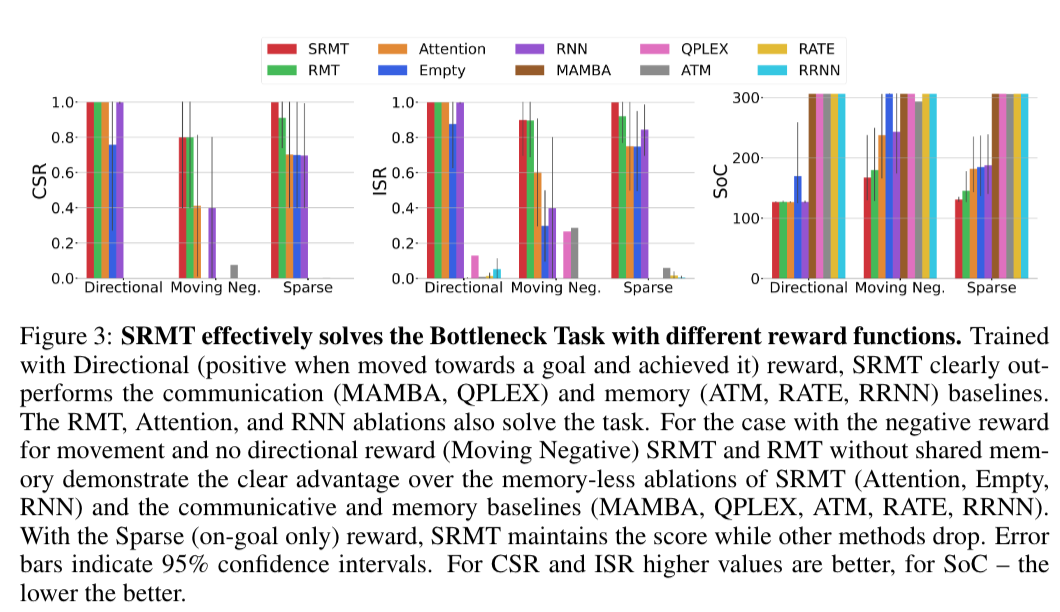
SRMT는 협소한 복도를 통과해야 하는 내비게이션 태스크에서 기존의 강화 학습 기반 AI를 압도하며, 특히 희소한 보상 환경에서도 탁월한 성능을 보인다.
SRMT는 학습 중에 경험하지 못한 긴 복도에서도 효과적으로 일반화하여 성과를 낸다.
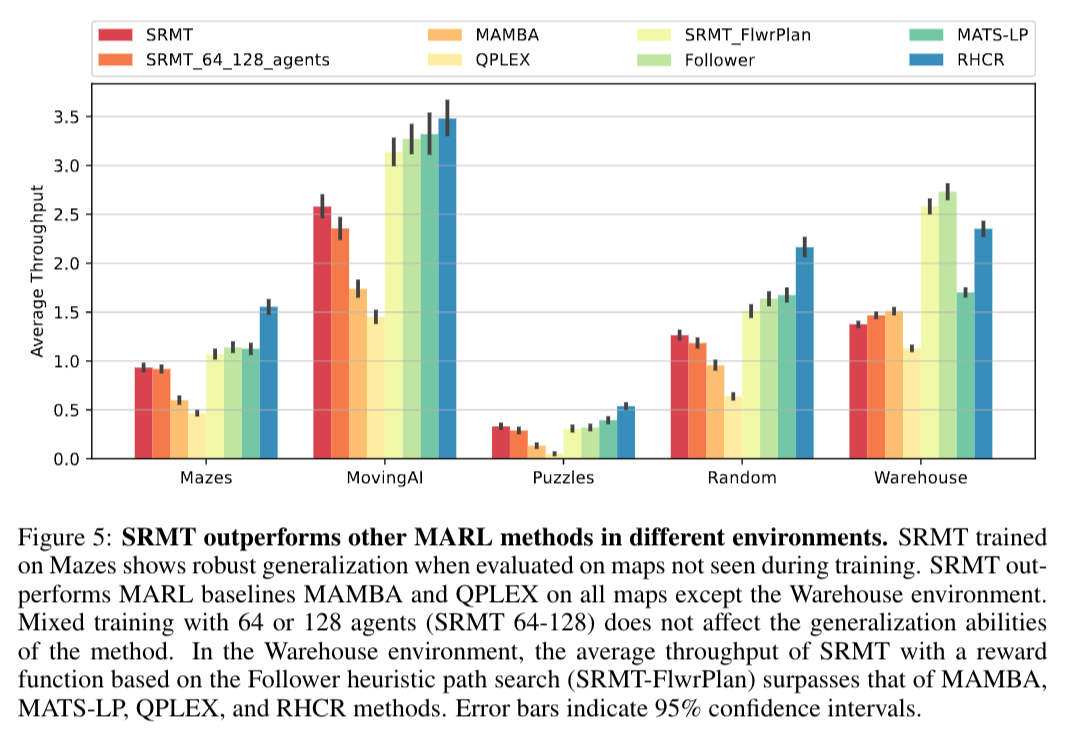
SRMT는 POGEMA 지도, 미로, 무작위, 이동AI를 포함한 환경에서 최근의 MARL, 하이브리드 및 계획 기반 알고리즘과 경쟁력을 가진다.
공유 순환 메모리를 트랜스포머 기반 구조에 통합함으로써 분산형 다중 에이전트 시스템에서의 협력을 향상할 수 있음을 시사한다.

4.4. SRMT와 다중 에이전트 경로 찾기
Shared Recurrent Memory Transformer (SRMT)는 다중 에이전트 환경에서의 정보 교환과 행동 조정을 위한 메커니즘으로, 협력을 개선하고 교착 상태를 피하기 위해 제안되었다.
SRMT는 개별 작업 메모리를 풀링(pooling)하고 전역적으로 방송하여 다중 에이전트 설정으로 확장된 메모리 변환기를 기반으로 한다.
부분 관찰 가능한 다중 에이전트 경로 찾기(PO-MAPF) 테스트에서 각 에이전트는 다른 에이전트의 행동과 정적 장애물을 포함한 환경의 상태를 관찰하면서 목표에 도달하려고 한다.
기존의 MAPF 문제 해결은 보통 독립적으로 보상을 수집하고 행동을 결정하는 방식으로 진행되며, 이는 종종 수작업으로 보상을 조정해야 하는 문제가 발생한다.
SRMT는 Bottleneck 내비게이션 과제에서 다양한 강화 학습 기준선을 일관되게 능가하며, POGEMA 벤치마크에서는 최신 하이브리드 및 계획 기반 알고리즘과 경쟁할만한 성능을 보여준다.
4.5. 다중 에이전트 강화 학습에서의 통신 및 조정 전략
다중 에이전트 강화 학습(MARL)에서는 에이전트 간 통신 프로토콜 제공이 단일 에이전트 강화 학습보다 큰 어려움으로 작용한다.
이를 해결하는 일반적인 전략에는 중앙화 설정, 완전 분산 설정, 네트워크 기반의 분산 설정이 포함된다.
특정 다중 에이전트 경로 찾기 문제에서는 VDN, QMIX, QPLEX 같은 방법이 있으며, 이들은 중앙화된 훈련을 통해 분산된 방법으로 수행된다.
중앙화 방법론에는 중앙화 검색 기반 플래너를 사용하는 LaCAM과 RHCR이 있다.
분산 통신 방법론에는 DCC, MAMBA, SCRIMP가 있으며, 이들은 에이전트 간 정보 공유를 통해 조정을 강화하고 충돌을 방지한다.
4.6. 다중 에이전트 시스템의 공유 메모리 접근법
MAMBA는 모델 기반 강화 학습 프레임워크 내에서 중앙 집중식 훈련과 분산 실행을 특징으로 하여, 에이전트들이 커뮤니케이션 블록을 통해 세계 모델을 업데이트하고 행동을 예측할 수 있게 한다.
QPLEX는 다중 에이전트 Q-러닝을 통해 중앙 집중식 훈련을 제공하며, 에이전트들이 독립적인 결정을 내리면서 중앙 집중식 훈련의 이점을 얻을 수 있도록 듀플렉스 듀얼링 메커니즘을 사용한다.
Follower와 MATS-LP는 커뮤니케이션 없는 평생 MAPF(Method for Lifelong Multi-Agent Pathfinding)를 위한 학습 가능한 방법으로, 각각 수정된 A* 유리스틱 검색 및 몬테카를로 트리 검색을 사용한다.
RHCR는 교육이 필요 없는 중앙 집중식 계획자이며, 재계획 스케줄에 따라 충돌을 해결하는 윈도우드 MAPF 인스턴스 시퀀스로 평생 MAPF를 분해한다.
Shared Recurrent Memory Transformer (SRMT)는 각 에이전트가 자체 메모리를 재귀적으로 업데이트하고, 공유 공간에 개별 메모리 표현을 읽고 쓰도록 학습하여 다중 에이전트 시스템의 분산 설정에서 공동 의사 결정을 촉진한다.
4.7. SRMT의 구조와 성능 분석
Shared Recurrent Memory Transformer (SRMT)는 에이전트 간의 메모리를 교차 어텐션 메커니즘(cross-attention mechanism)을 통해 공유하여 글로벌 정보를 접근할 수 있게 한다.
이 모델은 부분적으로 관측 가능한 다중 에이전트 마르코프 결정 프로세스를 활용하여, 공동 행동과 환경 상태 전이를 포함한 다양한 요소를 정의한다.
모든 에이전트가 행동을 수행하면, 그들의 성과를 반영한 스칼라 보상을 수신하고, 다음 단계로 나아가기 전에는 기본적 관찰을 새로 받는다.정책 근사화는 심층 신경망 구조를 통해 시도되고, 이 과정에서 ResNet과 MLP를 이용한 공간 인코더, 액션 디코더 및 비평가 네트워크가 활용된다.
SRMT는 에이전트 메모리 벡터, 관찰 역사, 현재 관찰 세 가지 요소를 결합한 셀프 어텐션 메커니즘을 사용하여 에이전트의 의사결정 과정에서 글로벌 컨텍스트를 포함할 수 있도록 한다.
4.8. 실험 조정 및 결과 분석
실험은 SRMT와 유사한 에이전트를 대상으로 진행되었다.
Moving Negative 보상 체계가 사용되었으며, 이를 통해 결과 성과를 측정했다.
각 에피소드의 길이는 2*통로 길이 + 100으로 조정되었다.
에이전트들이 각 에피소드 내에서 목표에 도달할 수 있는 충분한 시간을 확보하도록 조정되었다.
5. Shared Recurrent Memory Transformer의 특징 및 성과
SRMT는 명시적 통신 프로토콜 없이 에이전트 간 정보 교환과 조정 행동을 가능하게 하는 새로운 아키텍처이다.
병목 내비게이션 작업에서 SRMT는 기본 모델보다 우수한 성능을 일관되게 보여주며, 특히 희소한 보상 및 긴 경로에 대한 상황에서도 뛰어난 성과를 보인다.
공유 메모리 메커니즘은 훈련 중에 경험하지 못한 긴 경로에서도 학습된 정책을 일반화할 수 있도록 하며, 이는 확장성과 견고성을 증명한다.
POGEMA 맵(미로, 무작위, 이동 AI, 창고)에서 다양한 최신 MARL, 하이브리드, 계획 기반 알고리즘과 경쟁력이 있다.
이러한 결과는 다중 에이전트 강화 학습에 공유 메모리 구조를 통합하는 것이 갖는 잠재력을 강조한다.
5.1. SRMT 아키텍처와 협력적 통신 방식
다중 에이전트 강화 학습(MARL)는 다양한 환경에서 협력적이고 경쟁적인 문제를 해결하는 데 중요한 진전을 보이고 있다.
SRMT는 메모리 트랜스포머를 다중 에이전트 설정으로 확장하여 각 개별 에이전트의 작업 메모리를 풀링하고 글로벌로 방송하여 에이전트가 정보를 암묵적으로 교환하고 행동을 조정할 수 있게 한다.
SRMT의 성능은 부분적으로 관찰 가능한 다중 에이전트 경로 찾기 문제에서 평가되었으며, 특히 좁은 보틀넥을 통과해야 하는 네비게이션 작업에서 다양한 강화 학습 기준치를 일관되게 능가하는 성과를 보였다.
5.2. 다중 에이전트 시스템에서의 공유 메모리 활용
다중 에이전트 경로 찾기(MAPF) 문제에서 에이전트들은 공유 메모리를 사용해 정보를 교환하고 협업하여 교착 상태를 피할 수 있다.
Shared Recurrent Memory Transformer (SRMT)은 메모리 변환기를 다중 에이전트 설정으로 확장하여 에이전트의 개별 작업 메모리를 풀링하고 전역으로 방송한다.
기존의 중앙집중식 훈련을 중심으로 한 접근 방식과 대조적으로 SRMT는 훈련과 실행 동안 완전히 탈중앙화된 설정을 유지한다.
SRMT는 Mazes, Random, MovingAI를 포함한 POGEMA 벤치마크에서 최근 MARL 및 기타 알고리즘과 경쟁력을 갖는다.
5.3. SRMT의 훈련 및 메커니즘
Shared Recurrent Memory Transformer (SRMT) 아키텍처는 에이전트의 개인 메모리와 관찰 이력을 활용하여 다중 에이전트 환경에서 글로벌 메모리 접근을 제공한다.
SRMT는 부분적으로 관측 가능한 다중 에이전트 마코프 결정 과정(M)을 기반으로 정의되며, 에이전트들의 행동을 조합하여 환경 상태를 업데이트한다.
각 에이전트는 수행된 행동에 따라 보상을 받고, 이 보상은 미래 보상의 중요성을 결정하는 할인 인자 γ를 가진다.
에이전트의 정책은 깊은 신경망을 통해 근사하며, 에이전트가 균일하다고 가정하여 훈련 중에 정책을 공유한다.
에이전트의 행동은 개인 메모리 벡터, 과거 관찰 이력, 현재 관찰을 결합한 입력 시퀀스를 기반으로 하며, 출력물은 정책 모델의 디코더 부분을 통해 에이전트의 행동을 생성한다.




댓글