원문: https://arxiv.org/pdf/2310.04560v1
ABSTRACT
래프는 소셜 네트워크, 추천 시스템, 금융 계산 등 실제 세계의 복잡한 관계를 표현하고 분석하는 데 매우 유용한 도구입니다. 그래프를 활용한 추론은 복잡한 시스템에서 엔티티 간의 관계를 이해하고 숨겨진 패턴과 트렌드를 발견하는 데 필수적입니다.
자연어를 사용한 자동 추론 기술이 많이 발전했지만, 대형 언어 모델(LLM)을 사용하여 그래프에서 추론하는 문제는 아직 잘 연구되지 않았습니다. 이 연구에서는 그래프 구조 데이터를 텍스트로 변환해 LLM이 처리하도록 하는 방법에 대해 처음으로 포괄적으로 분석했습니다.
연구 결과, LLM의 그래프 추론 성능은 다음 세 가지 주요 요인에 따라 달라진다는 점을 밝혔습니다:
- 그래프를 텍스트로 변환하는 방법 (그래프 인코딩 방식)
- 그래프 과제의 성격 (예: 특정 과제가 얼마나 복잡한지)
- 그래프 구조 자체 (그래프의 형태나 특성)
이 연구를 통해 얻은 통찰력은 그래프를 텍스트로 변환하는 올바른 방법을 선택하면 그래프 추론 작업에서 LLM의 성능을 4.8%에서 최대 61.8%까지 향상시킬 수 있다는 것을 보여줍니다.
1 INTRODUCTION
최근 대형 언어 모델(LLM)에 대한 연구와 응용이 눈부신 발전을 이루고 있습니다. 다양한 작업과 데이터를 기반으로 훈련된 모델들이 속속 등장하면서, LLM은 인공지능 일반화(AGI)로 가는 길에서 중요한 진전으로 여겨지고 있습니다. 하지만 이러한 성공에도 불구하고, 현재 LLM 설계와 구현에는 몇 가지 한계가 있습니다.
주요 한계
- 비구조화된 텍스트 의존성:
LLM은 주로 비구조화된 텍스트를 처리하는 데 의존하기 때문에, 명확한 논리적 결론을 도출하지 못하거나 잘못된 정보를 "환각(hallucination)"처럼 만들어낼 때가 있습니다. - 최신 정보 반영의 어려움:
LLM은 학습 시점 이후의 세계 변화를 반영하기 어렵습니다. 최신 정보를 모델에 통합하는 것은 여전히 큰 도전 과제입니다.
그래프 데이터의 가능성
그래프 구조 데이터는 정보를 표현하는 데 매우 유연한 방법이며, 위의 두 가지 문제를 해결할 잠재력을 가지고 있습니다. 하지만 놀랍게도, 그래프와 LLM의 융합은 상대적으로 적게 연구되어 왔습니다. 기존 연구들은 주로 지식 그래프(knowledge graphs)나 그래프 데이터베이스에 초점을 맞췄지만, 범용적인 그래프 구조 데이터 활용에 대한 연구는 부족합니다.
최근 Wang et al. (2023)은 LLM의 그래프 추론 능력을 평가하기 위한 그래프 벤치마킹 작업을 설계했습니다. 하지만 이 연구는 몇 가지 자연스러운 그래프 작업을 제외하고, 다양성이 부족한 그래프 구조만을 다루는 한계를 보였습니다. 다른 연구에서는 그래프 데이터를 LLM으로 대체하려고 시도했지만, 이는 LLM의 근본적인 문제를 해결하지 못했습니다.
연구 내용
이 연구는 LLM이 그래프 구조 데이터를 텍스트로 처리하는 방식에 대한 최초의 포괄적 분석을 수행했습니다. 이를 위해 다음 두 가지를 세부적으로 나눠서 연구했습니다:
- 그래프 인코딩(graph encoding):
그래프를 텍스트로 변환하는 방식에 따라 LLM이 그래프 작업에서 학습된 표현을 얼마나 잘 활용할 수 있는지 분석합니다. - 프롬프트 엔지니어링(prompt engineering):
특정 질문에 대해 원하는 답을 얻기 위해 가장 적합한 방법을 찾습니다. 다양한 프롬프트 전략이 각각 어떤 상황에서 효과적인지 실험적으로 분석했습니다.
이를 통해 GraphQA라는 새로운 벤치마크를 제안했습니다. GraphQA는 기존 연구보다 더 다양한 그래프 구조를 사용하여 LLM의 그래프 추론 성능을 측정하도록 설계되었습니다.

주요 기여
- LLM에서 그래프 구조를 활용한 프롬프트 기술에 대한 심층적 연구.
- 그래프를 텍스트로 변환하는 모범 사례 및 인사이트 제공.
- LLM이 그래프 구조 데이터를 다룰 때 성능을 평가할 수 있는 GraphQA 벤치마크 개발.
2 PROMPTING LLMS FOR GRAPH REASONING
표기 설명
이 연구에서 사용하는 주요 개념과 표기를 다음과 같이 정의합니다.
- 인터페이스 함수 f
ff는 생성형 AI 모델의 인터페이스 함수로, 고차원의 이산 입력 토큰 W를 받아 동일한 토큰 공간에서 출력을 생성합니다. 이를 수식으로 표현하면 f:W→W .여기서 f는 토큰을 입력받아 다시 토큰을 출력하는 함수입니다. - 생성형 AI 모델
본 논문에서는 f를 대형 언어 모델(LLM)이라고 부르지만, 이 논의는 동일한 이산형 인터페이스를 가진 모든 생성형 AI 모델에 적용될 수 있습니다. - 그래프 G
그래프는 다음과 같이 정의됩니다:G=(V,E)- V: 정점(노드) 집합
- E: 간선(엣지) 집합으로, 이는 V×V의 부분 집합입니다. 즉, 그래프에서 정점 간 연결 관계를 나타냅니다.
2.1 PROMPT ENGINEERING
프롬프트 엔지니어링의 목표
프롬프트 엔지니어링의 목표는 질문 Q를 올바르게 표현하여 대형 언어 모델(LLM) f가 원하는 정답 A를 반환하도록 하는 것입니다. 이를 수식으로 나타내면 A=f(Q).
즉, 질문 Q를 모델 f에 입력했을 때 정답 A를 얻는 것이 목표입니다.
이 연구에서는 그래프 정보 G를 f에 제공하여, 복잡한 관계 정보를 포함한 질문/답변 작업을 더 잘 수행할 수 있도록 하는 데 초점을 맞춥니다. 이를 확장한 수식은 다음과 같습니다 A=f(G,Q).
여기서 그래프 G는 정점(노드)과 간선(엣지)으로 구성된 복잡한 데이터 구조를 나타냅니다.
기존 방법의 한계
그래프 데이터를 처리하기 위해 LLM f를 조정하는 방법으로는 다음과 같은 기법이 있습니다.
- 미세 조정(Fine-tuning): 모델의 가중치를 다시 학습시키는 방법.
- 소프트 프롬프트(Soft Prompting): 학습 가능한 프롬프트를 사용해 모델을 유도하는 방법.
- LoRA(Low-Rank Adaptation): 모델 파라미터를 효율적으로 조정하는 방법.
하지만 이들 방법은 모두 모델 내부(가중치 또는 기울기)에 접근해야 하며, 이는 실제 환경에서 모델이 제한적으로 제공되는 경우에는 적용하기 어렵습니다. 특히, 상용화된 모델들은 대개 블랙박스(내부 구조를 알 수 없는 상태)로 제공됩니다.
이 연구의 접근법
이 연구에서는 모델 f의 내부를 변경하지 않고, 블랙박스 상태에서 그래프 정보를 LLM이 처리할 수 있도록 다음 두 가지 함수를 도입합니다.
- 그래프 인코딩 함수 g(G)
그래프 G를 텍스트로 변환하여 f가 이해할 수 있도록 만듭니다.g:G→W - 질문 재구성 함수 q(Q)
질문 Q를 재구성하여 LLM f가 더 나은 답변을 생성할 수 있도록 만듭니다.q:W→W
최종적으로, f는 다음과 같이 그래프와 질문 정보를 처리해 정답 A를 생성합니다.
A=f(g(G),q(Q))
최적화 목표
그래프 기반 프롬프트 시스템의 학습 데이터 D는 G,Q,S의 삼중 조합으로 이루어져 있습니다.
- G: 그래프 정보
- Q: 질문
- S: 질문 Q에 대한 정답 (LLM이 생성해야 할 결과)
목표는 g(G)와 q(Q)를 최적화하여, 모델이 정답에 높은 점수(score)를 부여하도록 만드는 것입니다.
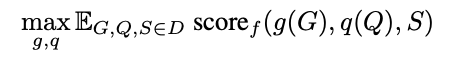
2.2 PROMPTING HEURISTICS
주요 프롬프트 기법 소개
대부분의 프롬프트 기법은 모델에 입력하는 텍스트 QQ를 최적화하여 더 나은 결과를 얻는 것을 목표로 합니다. 이 연구에서 다룬 주요 기법들은 다음과 같습니다:
1. 제로샷 프롬프팅 (Zero-shot prompting, ZERO-SHOT)
- 모델에 작업 설명만 제공하고, 별도의 훈련 없이 원하는 출력을 요청하는 방식입니다.
- 예: "이 문장을 요약해 주세요."
2. 퓨샷 학습 (Few-shot in-context learning, FEW-SHOT)
- 작업의 몇 가지 예제와 함께 정답을 모델에 제공하고, 이를 바탕으로 새로운 입력에 대한 작업을 수행하게 합니다.
- 예: "이전에 제공된 예시를 참고해 새로운 입력을 처리하세요."
3. 연쇄적 사고 프롬프팅 (Chain-of-thought prompting, CoT)
- 작업을 단계별로 해결하는 과정을 보여주는 예제를 제공합니다. 모델은 이를 바탕으로 새로운 문제도 단계적으로 해결합니다.
- 예: "단계별로 문제를 풀이하세요."
4. 제로샷 연쇄적 사고 프롬프팅 (Zero-shot CoT prompting, ZERO-COT)
- CoT 방식과 비슷하지만, 사전 예제가 필요하지 않습니다. 간단한 프롬프트로 모델이 스스로 단계별 풀이를 생성하게 유도합니다.
- 예: "Let's think step by step."
5. 그래프 중심 프롬프팅 (Bag prompting, COT-BAG)
- 그래프 관련 작업 성능을 높이기 위해 설계된 기법으로, 그래프 설명에 "Let's construct a graph with the nodes and edges first"를 추가합니다.
- 그래프를 먼저 생성하도록 유도하여 더 나은 결과를 얻습니다.
반복적 프롬프팅의 한계
최근에는 반복적 프롬프팅(Iterative Prompting)이 주목받고 있습니다. 이 방식은 모델에 여러 번 질문을 던지며 프롬프트를 점진적으로 최적화하는 방법입니다.
- 그러나 이 연구에서는 반복적 프롬프팅이 오류가 누적(cascading errors)되면서 그래프 작업 성능이 낮아지는 것을 확인했습니다.
- 따라서 이 연구는 위에서 소개한 주요 기법들에 집중합니다.
연구 목표
이 연구의 목표는 그래프 관련 기본 작업에서 그래프 인코딩 함수를 최적화하는 것입니다.
- 기본 그래프 작업은 더 복잡한 그래프 추론 작업을 수행하기 위한 중요한 중간 단계로 간주됩니다.
- 연구에서는 그래프 인코딩 함수, 질문 표현 방식, 그리고 그래프 생성 방식을 실험적으로 분석하며, 블랙박스 LLM 환경에서 그래프 인코딩 기법을 체계적으로 연구합니다.
3 TALK LIKE A GRAPH: ENCODING GRAPHS VIA TEXT
그래프 인코딩과 연구 목표
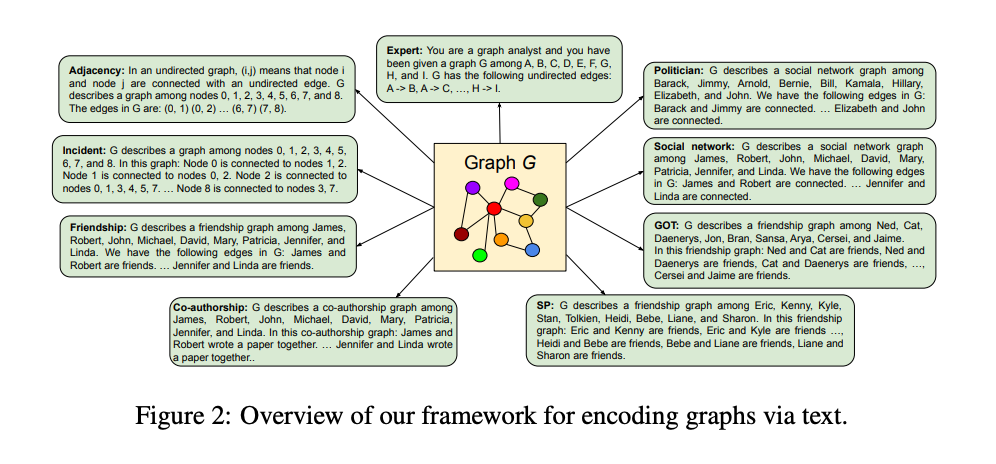
그래프 인코딩은 그래프 구조 정보를 언어 모델(LLM)이 처리할 수 있는 텍스트 시퀀스로 변환하는 필수 단계입니다. 이 섹션에서는 그래프 데이터를 LLM의 입력으로 변환하는 그래프 인코딩 함수 g(.)에 대해 분석하며, 그래프 추론 작업에서 성능을 극대화하기 위한 최적의 인코딩 방법과 프롬프트 엔지니어링을 연구합니다.
주요 연구 결과
연구에서 발견한 주요 결과는 다음과 같습니다.
- R1: LLM은 기본 그래프 작업에서 성능이 낮다.
- 그래프 관련 기본 작업에서도 LLM이 어려움을 겪는다는 점을 확인했습니다.
- R2: 그래프 인코딩 함수가 LLM의 그래프 추론 성능에 큰 영향을 준다.
- 그래프를 텍스트로 어떻게 표현하느냐에 따라 모델의 성능이 크게 달라졌습니다.
- R3: 모델의 용량(크기)이 그래프 추론 능력에 중요한 영향을 미친다.
- 더 큰 모델이 더 나은 추론 성능을 보였습니다.
그래프 인코딩 함수
그래프를 텍스트로 표현하는 다양한 방법을 조사했습니다. 이 과정은 다음 두 가지 주요 질문으로 나눌 수 있습니다.
- 노드(Node) 인코딩 방법:그래프의 정점(노드)을 텍스트로 어떻게 표현할 것인가?
- 엣지(Edge) 인코딩 방법:정점 간의 연결 관계(엣지)를 어떻게 텍스트로 표현할 것인가?
연구에서는 노드와 엣지를 텍스트로 표현하는 여러 기법을 실험적으로 비교했습니다. 이에 대한 자세한 설명과 예제는 부록 A.1에 정리되어 있습니다.
그래프 구조
실험 설계는 Wang et al. (2023)의 방법론을 참고했으며, 에르되시-레니(ER) 그래프를 활용했습니다.
- ER 그래프는 간선이 무작위로 연결되는 간단한 그래프 모델로, 그래프 실험에서 자주 사용됩니다.
- 그러나 본 연구에서는 ER 그래프 외에도 더 복잡한 그래프 구조가 LLM의 추론에 미치는 영향을 분석했습니다. 이 내용은 섹션 4에서 다룹니다.
3.1 EXPERIMENT 1: VARYING GRAPH ENCODING FUNCTIONS
실험 목표
이 실험에서는 사전 학습된 대형 언어 모델(LLM)이 다양한 그래프 태스크를 수행하는 성능을 측정합니다. 측정 대상이 되는 그래프 태스크는 다음과 같습니다.
- Edge existence (간선 존재 확인):두 노드 간에 간선(연결)이 존재하는지 확인합니다.
- Node degree (노드 차수):특정 노드에 연결된 간선의 개수를 계산합니다.
- Node count (노드 개수):그래프에 포함된 총 노드 수를 계산합니다.
- Edge count (간선 개수):그래프에 포함된 총 간선 수를 계산합니다.
- Connected nodes (연결된 노드):특정 노드에 직접 연결된 노드들을 나열합니다.
- Cycle check (사이클 확인):그래프에 사이클(노드들을 따라 다시 시작점으로 돌아오는 경로)이 있는지 확인합니다.
그래프 벤치마크: GraphQA
이 실험에서는 위의 작업을 포함한 벤치마크 데이터셋 GraphQA를 활용합니다.
- GraphQA는 다양한 그래프 작업과 구조를 포함하며, LLM의 그래프 추론 능력을 평가하기 위해 설계되었습니다.
- 각 작업과 데이터셋의 상세한 설명은 부록 A.2에 제공됩니다.
3.1.1 RESULTS
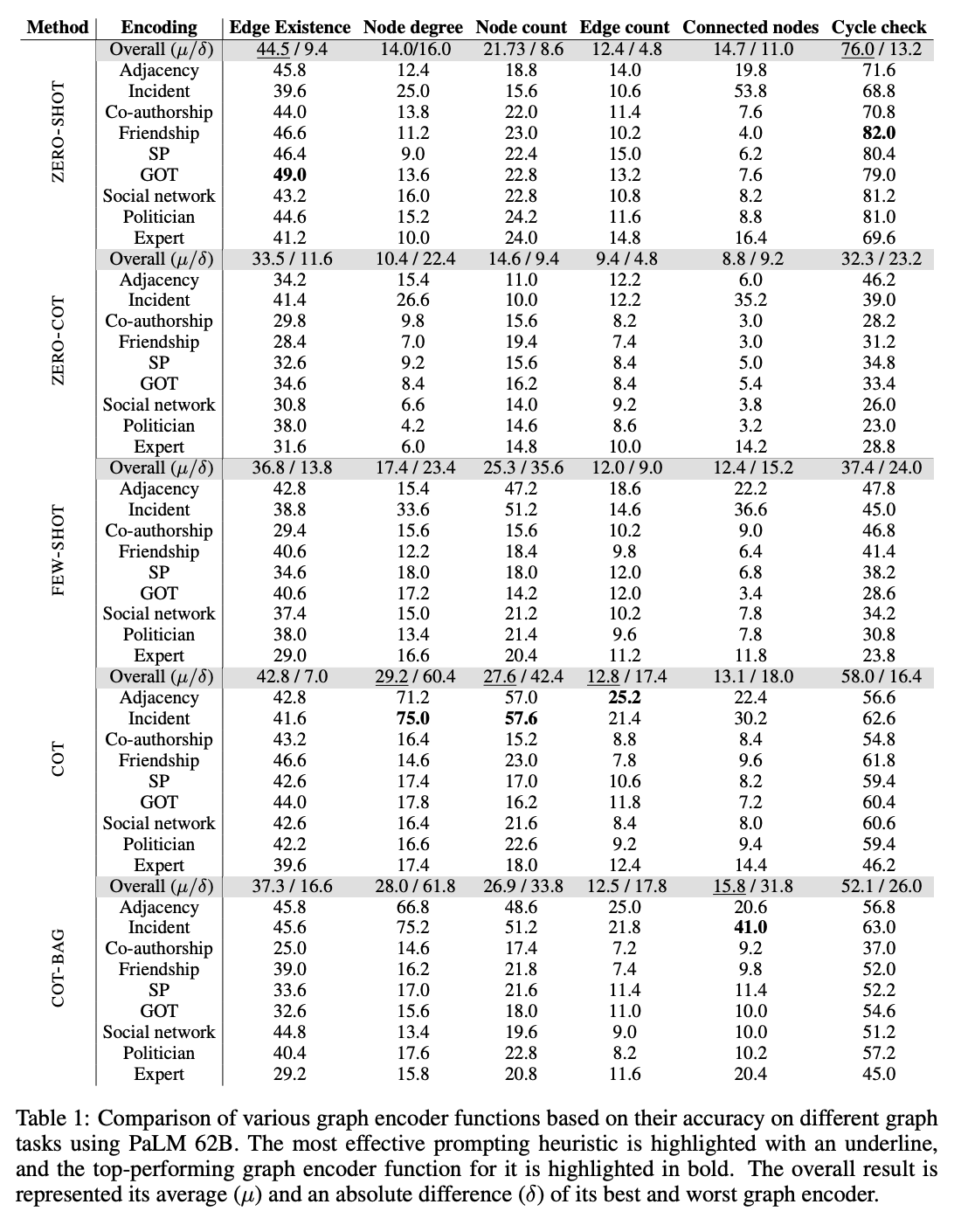
LLM의 기본 그래프 작업 성능은 낮음
- 대부분의 기본 그래프 작업에서 LLM은 성능이 저조했습니다.
- 특히, 다음 두 작업에서 다수결 기준(majority baseline)**보다도 낮은 성능을 보였습니다.
- 간선 존재 여부(edge existence): 간선이 없는 경우가 53.96%였으나, LLM은 이를 잘 예측하지 못함.
- 사이클 확인(cycle check): 그래프에 사이클이 있는 경우가 81.96%였으나, 이를 정확히 판단하지 못함.
- 이는 LLM이 간단한 그래프 구조도 제대로 이해하지 못한다는 것을 시사합니다.
간단한 작업에는 간단한 프롬프트가 효과적
- ZERO-COT(제로샷 연쇄적 사고 프롬프트)는 기본 그래프 작업에서 ZERO-SHOT(제로샷 프롬프트)보다 성능이 낮았습니다. 이유는 기본 그래프 작업은 다중 단계 추론(multi-hop reasoning)을 요구하지 않으며, ZERO-SHOT 프롬프트로도 충분히 수행 가능.
- 반면, 복잡한 작업에서는 퓨샷(Few-shot) 예제와 CoT(연쇄적 사고) 프롬프팅이 성능을 향상시켰습니다. 퓨샷 예제는 모델이 작업을 더 잘 이해하도록 돕고, CoT는 문제를 해결하는 단계적 과정을 제공하여 성능을 높였습니다.
그래프 인코딩 함수의 선택이 성능에 중요한 영향
- 그래프 인코딩 방식에 따라 LLM의 그래프 작업 성능이 크게 달라졌습니다.
- 예:연결된 노드 찾기(connected nodes):
- Adjacency 인코딩: 19.8% 정확도.
- Incident 인코딩: 53.8% 정확도로 더 우수.
- 노드 차수(node degree) 및 연결된 노드 찾기: Incident 인코딩이 가장 우수한 성능을 보임.
- 이유: Incident 인코딩은 관련 정보를 모델이 더 쉽게 접근할 수 있도록 가깝게 배치했기 때문.
정수 기반 노드 인코딩은 산술 작업 성능을 향상
- 노드를 정수(integer)로 인코딩하면, 산술 작업(노드 차수, 노드 수, 간선 수 예측)에서 성능이 향상되었습니다 이유는 입력과 출력이 동일한 공간(숫자 형태)이기 때문에, 모델이 두 값 사이의 관계를 더 쉽게 학습.
- 반면, 이름 기반 인코딩(e.g., "David")은 산술이 아닌 작업(e.g., 간선 존재, 사이클 확인)에서 더 나은 성능을 보였습니다.
올바른 그래프 인코딩 함수의 중요성
- 적절한 그래프 인코딩 방식을 선택하면 그래프 알고리즘 작업에서 LLM 성능을 크게 향상시킬 수 있습니다.
- 예:
- 소셜 네트워크에서 영향력 있는 노드 찾기는 노드 차수를 찾는 작업과 유사.
- 적절한 그래프 인코딩을 사용하면 이와 같은 작업의 성능이 향상될 수 있음.
결론
- 그래프 작업에서 LLM 성능을 최적화하려면, 작업의 특성에 맞는 그래프 인코딩 방식을 신중하게 선택해야 합니다.
- 그래프 인코딩 방법의 상대적 성능 비교는 부록 A.3에서 더 자세히 다룹니다.
3.2 EXPERIMENT 2: VARYING PROMPT QUESTIONS
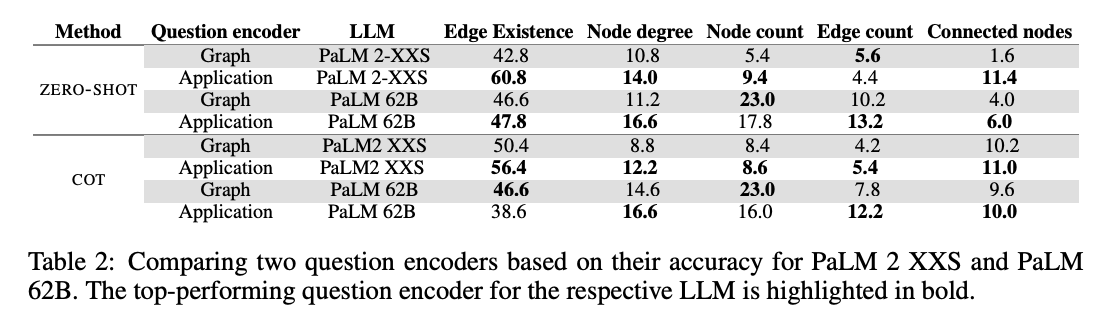
이 실험에서는 그래프 인코딩 함수를 "우정(friendship)"이라는 개념에 고정한 상태에서, 질문 인코더 함수를 두 가지로 나누어 비교했습니다.
첫 번째는 그래프 질문 인코더(graph question encoder)로, 그래프와 관련된 작업을 직접적으로 표현합니다.
예를 들어, 특정 노드의 차수를 묻는 질문은 “노드 i의 차수는 무엇인가?”와 같이 작성됩니다.
두 번째는 응용 질문 인코더(application question encoder)로, 그래프 작업을 실생활에서 더 친숙한 형태로 변환합니다.
예를 들어, 간선 존재 여부는 “두 사람이 친구인가요?”로, 노드 차수는 “한 사람이 몇 명의 친구를 가지고 있나요?”와 같이 표현됩니다.
결과적으로, 응용 질문 인코더가 대부분의 작업에서 그래프 질문 인코더보다 우수한 성능을 보였습니다. 예를 들어, PALM 2 XXS 모델에서 ZERO-SHOT 간선 존재 여부 작업을 수행했을 때, 그래프 질문 인코더는 42.8%의 정확도를 기록한 반면, 응용 질문 인코더는 60.8%의 정확도를 달성했습니다. 이는 두 인코더가 동일한 그래프 인코딩 함수를 사용했음에도, 질문을 표현하는 방식의 차이가 성능에 큰 영향을 미쳤음을 보여줍니다.
결론적으로, LLM이 기본 그래프 알고리즘을 처리할 때 질문을 어떻게 표현하느냐가 중요한 요인이 됩니다. 따라서 LLM을 활용한 추론 작업에서는 주어진 작업을 더 의미 있는 문맥적 표현으로 변환하는 것이 성능을 높이는 핵심 전략이라고 할 수 있습니다.
3.3 EXPERIMENT 3: MULTIPLE RELATION ENCODING
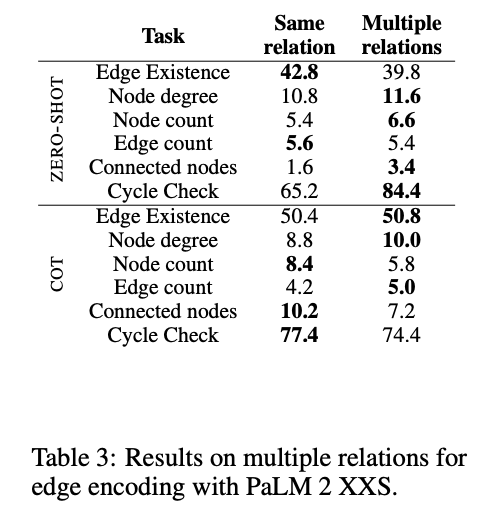
이 실험에서는 우정(friendship) 그래프 인코딩 함수를 수정하여, 간선을 단일 유형의 관계로 표현하는 대신 다양한 관계 유형으로 표현했습니다. 간선(노드 간 연결)은 친구, 동료, 배우자, 형제자매, 이웃, 지인, 팀원, 반 친구, 직장 동료, 룸메이트 등으로 무작위로 선택된 관계 유형으로 표시되었습니다. 이렇게 다양한 단어를 사용해 관계를 표현하는 방식은 이전 실험에서 동일한 토큰으로 간선을 표현하던 방식과 차별화됩니다.
결과적으로, 관계를 나타내는 여러 단어를 사용하는 방식이 LLM 성능에 부정적인 영향을 미치지 않았으며, 일부 작업에서는 오히려 성능이 향상되었습니다. 이 향상의 이유는 다음과 같습니다:
- 다양한 관계 유형이 LLM에 더 풍부한 텍스트 정보를 제공했기 때문입니다.
- 이러한 표현 방식이 LLM이 훈련 중에 접했을 가능성이 높은 텍스트 형태와 더 유사했기 때문입니다.
관계를 단일한 표현으로 제한하기보다 다양한 표현으로 관계를 나타내는 것이 LLM이 그래프 작업을 수행하는 데 도움이 될 수 있음을 보여줍니다.
3.4 EXPERIMENT 4: MODEL CAPACITY AND GRAPH REASONING ABILITY
이 실험에서는 모델의 크기(용량)가 그래프 작업에 미치는 영향을 측정했습니다. 이를 위해 PaLM 2 모델의 다양한 버전(XXS, XS, S, L)을 비교했으며, 각 모델은 매개변수의 수가 달라 성능에도 차이가 있습니다. 참고를 위해 다수결 기준(majority baseline) 성능도 함께 보고했습니다.
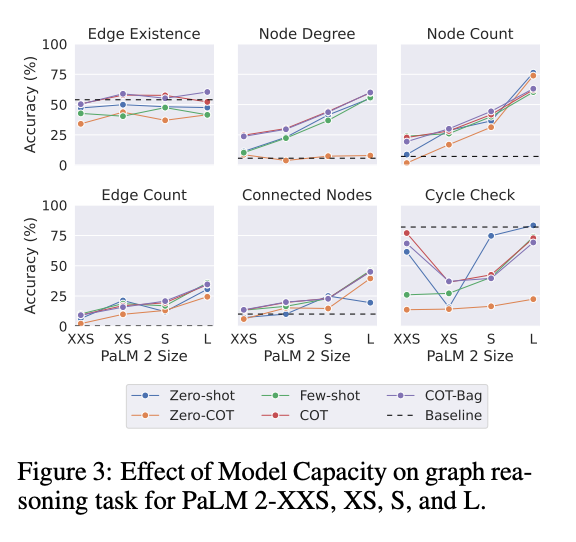
결과
- 모델 크기가 클수록 그래프 추론 성능이 향상됨
- 모델이 클수록(즉, 더 많은 매개변수를 가질수록) 그래프 작업에서 전반적으로 더 나은 성능을 보였습니다.
- 이는 큰 모델이 더 많은 정보와 복잡한 패턴을 학습하고 저장할 수 있기 때문입니다.
- 간선 존재 여부(edge existence) 작업에는 모델 크기의 효과가 미미
- 다른 작업에서는 모델 크기가 성능에 큰 영향을 미쳤지만, 간선 존재 여부 작업에서는 모델 크기의 효과가 적었습니다.
- 심지어 큰 모델에서도 간선 존재 여부 작업에서 다수결 기준(majority baseline)을 넘어서지 못했습니다.
3. 5 EXPERIMENT 5: REASONING IN THE ABSENCE OF EDGES
이 실험에서는 연결되지 않은 노드(disconnected nodes)를 찾는 작업에서 LLM의 성능을 평가했습니다. 이 작업은 이전 작업과는 달리, 그래프에서 명시적으로 제공되지 않은 정보(연결되지 않은 노드에 대한 정보)를 추론해야 한다는 점에서 차이가 있습니다.
결과
- LLM은 그래프의 전체적인 구조를 이해하지 못함
- ZERO-SHOT 프롬프팅 방식으로 수행한 결과, 정확도는 0.5%에 불과했습니다.
- ZERO-COT, FEW-SHOT, COT, COT-BAG 등 다른 프롬프팅 방식에서는 정확도가 거의 0.0%에 가까웠습니다.
- 이는 연결되지 않은 노드를 찾는 작업에서 LLM이 연결된 노드를 처리하는 작업보다 훨씬 낮은 성능을 보인다는 것을 보여줍니다.
- 이유: 그래프 인코딩 함수의 제한
- 그래프 인코딩 함수는 주로 연결된 노드 간의 관계를 텍스트로 변환하지만, 연결되지 않은 노드에 대한 정보를 명시적으로 포함하지 않습니다.
- 그 결과, LLM은 연결 관계를 처리하는 데는 상대적으로 강하지만, 연결이 없는 상태를 추론하는 작업에서는 성능이 떨어집니다.
LLM은 그래프의 연결되지 않은 상태를 추론하는 작업에서 매우 낮은 성능을 보입니다. 이는 그래프 인코딩 함수가 명시적으로 연결되지 않은 정보를 제공하지 않기 때문입니다. 따라서 이러한 작업에서는 LLM의 성능을 향상시키기 위해 그래프 인코딩 방식을 개선할 필요가 있습니다.
4 DOES THE STRUCTURE OF THE GRAPH MATTER FOR THE LLM?
이 연구에서는 그래프의 구조가 LLM의 추론 능력에 어떤 영향을 미치는지 조사했습니다. 이는 최근 그래프 신경망(GNN)을 분석한 연구들(Palowitch et al., 2022; Yasir et al., 2023)에서 영감을 받아 수행되었습니다. 여기서는 다양한 구조를 가진 그래프에서 LLM의 추론 성능을 비교합니다.
주요 내용
- 그래프 구조의 중요성
- 그래프의 생성 방식이나 구조 자체가 LLM의 추론 성능에 중요한 영향을 미칠 수 있다는 점을 확인했습니다.
- 특정 그래프 구조는 모델이 정보를 처리하고 추론하는 데 유리하거나 불리하게 작용할 수 있습니다.
- 그래프 생성 방식
- 다양한 생성 프로세스를 통해 만든 그래프를 실험에 사용했습니다.
- 예를 들어, 랜덤 그래프, 트리 구조, 클러스터형 그래프 등 서로 다른 구조의 그래프들이 포함되었습니다.
- 결과와 시사점
- 그래프의 구조는 LLM이 작업을 수행하는 데 있어 성능 차이를 유발하는 중요한 요인으로 작용했습니다.
- 이는 그래프의 특성(노드와 간선의 배치 방식)이 모델이 정보를 이해하고 활용하는 방식에 영향을 미치기 때문입니다.
그래프의 구조는 LLM의 추론 능력에 큰 영향을 미칠 수 있습니다. 따라서 그래프와 관련된 작업에서 성능을 최적화하려면, 사용되는 그래프의 구조를 신중히 고려해야 합니다. 이 연구는 다양한 그래프 구조가 LLM의 성능에 미치는 영향을 시각적으로 보여주는 Figure 4를 통해 이를 설명합니다.
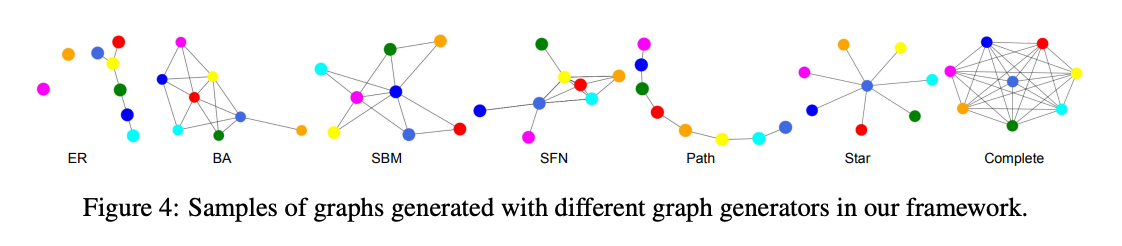
4. 1 RANDOM GRAPH GENERATION
이 연구에서는 LLM이 그래프 작업을 수행하는 능력을 평가하기 위해 다양한 그래프 생성 알고리즘을 사용해 랜덤 그래프를 생성했습니다. 이를 통해 다음과 같은 이점을 얻고자 했습니다.
다양한 그래프 특성 포함
- 서로 다른 그래프 생성기는 각기 다른 특성을 가진 그래프를 생성합니다.
- 에르되시-레니(ER) 그래프: 희소(sparse)하고 평균 차수가 작은 그래프.
- 바라바시-알버트(BA) 그래프: 밀도가 높고 차수가 파워 법칙(power-law)을 따르는 그래프.
- 다양한 생성기를 사용함으로써, GraphQA 벤치마크가 다양한 특성을 가진 그래프를 포함하도록 설계되었습니다.
평가 편향 방지
- 그래프 문제의 난이도는 그래프의 특성에 따라 달라질 수 있습니다.
- 특정 생성기만 사용하면 편향된 결과를 얻을 수 있으므로, 여러 종류의 그래프를 포함해 공정한 평가가 이루어지도록 했습니다.
현실적인 벤치마크 제공
- 실제 세계의 그래프는 매우 다양한 특성을 가지고 있습니다.
- 단일한 생성기만으로 현실적인 그래프 특성을 모두 반영하기는 어렵기 때문에, 다양한 생성기를 사용해 더 현실적인 벤치마크를 만들었습니다.
사용된 그래프 생성기
- 랜덤 그래프
- Erdős–Rényi (ER): 무작위로 간선을 연결하여 생성.
- Barabási–Albert (BA): 차수가 높은 노드가 더 많은 연결을 갖는 스케일-프리 네트워크 생성.
- Stochastic Block Model (SBM): 군집(cluster) 구조를 갖는 그래프 생성.
- 특정 구조의 그래프
- 스타 그래프: 중심 노드에 다른 노드가 연결된 형태.
- 경로 그래프: 노드가 선형으로 연결된 형태.
- 완전 그래프: 모든 노드가 서로 연결된 형태.
그래프 생성에는 NetworkX 라이브러리(Hagberg et al., 2008)를 사용했습니다. 더 자세한 내용은 부록 A.4에 정리되어 있습니다.
4. 2. RESULTS ON RANDOM GRAPH GENERATORS
이 실험에서는 다양한 그래프 생성 알고리즘이 LLM의 그래프 추론 작업 성능에 미치는 영향을 분석했습니다. 이전 실험에서는 Erdős-Rényi (ER) 그래프를 사용했지만, ER 그래프는 현실 세계의 그래프 특성을 잘 반영하지 못합니다. 따라서 이번 실험에서는 여러 생성 알고리즘을 사용해 더 현실적인 평가를 수행했습니다. 또한, 퓨샷(Few-shot) 예제를 다양한 그래프 생성기에서 무작위로 샘플링하여 실험에 활용했습니다.
주요 결과
- 그래프 구조는 LLM 성능에 큰 영향을 미침
- 그래프를 생성하는 알고리즘이 LLM의 작업 성능에 중요한 영향을 미쳤습니다.
- 사이클 확인 작업
- 완전 그래프(Complete Graphs): 항상 사이클을 가지므로 정확도가 91.7%로 높게 나옴.
- 경로 그래프(Path Graphs): 사이클이 없으므로 정확도가 5.9%로 낮게 나옴.
- 퓨샷 예제를 추가했을 때, 경로 그래프에서 정확도가 5.9% → 19.7%로 상승.
- 간선 존재 여부 작업
- 경로 그래프에서는 간선이 드물어 정확도가 60.0%로 높음.
- 완전 그래프에서는 모든 노드가 연결되어 있어 정확도가 19.8%로 낮음. 이는 LLM이 노드 간 연결 가능성을 과소평가하는 경향을 보였기 때문.
- 혼란을 유발하는 그래프 인코딩이 성능에 부정적 영향을 미침
- 노드 차수, 노드 수, 연결된 노드 작업에서 스타 그래프와 경로 그래프가 가장 높은 정확도를 기록.
- 이유: 이 그래프들은 간선이 적어 그래프 인코딩이 간단하고, 불필요한 정보(혼란을 유발하는 진술)가 적었기 때문.
- 반면, 완전 그래프는 간선이 많아 불필요한 정보가 증가하고, 정확도가 낮아짐.
- 노드 차수, 노드 수, 연결된 노드 작업에서 스타 그래프와 경로 그래프가 가장 높은 정확도를 기록.
- 퓨샷 예제가 성능 향상에 도움
- 퓨샷 예제와 연쇄적 사고(Chain of Thought, CoT) 프롬프팅을 추가했을 때 대부분의 작업에서 성능이 향상.
- 이 실험에서는 퓨샷 예제가 반드시 같은 그래프 생성기에서 나올 필요가 없었습니다.
- 이는 퓨샷 예제의 주요 역할이 LLM에게 작업을 설명하는 데 있다는 것을 보여줌.
결론
- 그래프 구조와 그래프 인코딩의 복잡성은 LLM의 그래프 작업 성능에 큰 영향을 미칩니다.
- 간선이 적고 인코딩이 간단한 그래프에서 성능이 더 좋음.
- 퓨샷 예제는 작업 성능 향상에 중요한 역할을 하며, 예제가 특정 그래프 생성기에서 나올 필요는 없음.
- 현실적인 그래프 생성 방식을 포함한 다양한 구조를 고려할 때, LLM의 그래프 추론 능력을 더 공정하게 평가할 수 있음.
5 RELATED WORK
In-Context Learning
- In-Context Learning은 LLM을 사전 학습 데이터 없이 새로운 작업에 적응시키는 방법입니다.
- 예: 테스트 입력 앞에 k개의 입력-출력 예제를 제공하여 작업 맥락을 모델에 전달하는 퓨샷(Few-Shot) 방법.
- 장점: 별도의 훈련 없이도 성능 향상이 가능하며, 새로운 작업에도 적용할 수 있음.
- 단점: 대규모 모델에서 계산 비용이 높고, 훈련 데이터 준비가 복잡할 수 있음.
- 최근 연구는 문맥 예제 선택을 최적화하는 전략을 제안
- 유사한 예제 검색 (Liu et al., 2021)
- 연쇄적 사고(Chain-of-Thought, CoT) 사용 (Wei et al., 2022)
- 작업을 하위 문제로 분해 (Zhou et al., 2022a)
텍스트 기반 추론
- LLM을 사용한 추론에서 두 가지 접근법이 주로 사용됨
- 모듈형 추론(Modular Reasoning): 문제를 여러 작은 모듈로 나누고 각 모듈을 처리하는 방식 (Zhou et al., 2022a; Kazemi et al., 2022).
- 단일 호출 추론(Single LM Call): 한 번의 모델 호출로 질문에 대한 답을 예측하는 방식.
- 본 연구는 두 번째 접근법에 초점을 맞춤.
지식 증강 LLM (Knowledge-Augmented LLMs)
- LLM의 이해력을 향상시키기 위해 지식 그래프(KG)와 같은 외부 지식을 활용.
- 방법:
- KG에서 추가 학습 데이터를 생성 (Guu et al., 2020; Lewis et al., 2020)
- KG 기반으로 사전 학습을 확장 (Yasunaga et al., 2022; Jin et al., 2023).
- 방법:
그래프 추론과 LLM
- 그래프와 LLM의 결합은 빠르게 발전하는 연구 분야.
- 예: InstructGLM (Ye et al., 2023)은 그래프 노드 분류 작업을 위한 모델을 제안.
- Chen et al. (2023)은 LLM을 그래프 학습 모델에서 텍스트 속성을 활용하는 도구로 사용.
- Wang et al. (2023)은 LLM의 그래프 작업 능력을 벤치마킹하기 위한 초기 작업을 수행.
- 한계
- 자연스러운 그래프 작업을 일부 제외.
- 다양한 그래프 구조를 충분히 고려하지 않음.
- 고정된 그래프 및 질문 인코더 함수 사용.
- 한계
본 연구의 기여
- 기본 그래프 작업에 초점: 더 복잡한 그래프 추론 작업의 필수적인 중간 단계를 구성.
- 광범위한 실험: 그래프 및 질문 인코딩 함수, 다양한 그래프 생성 알고리즘을 포함하여 실험 수행.
- GraphQA 벤치마크:그래프 구조가 LLM의 인코딩에 미치는 영향을 평가하는 새로운 벤치마크 도구.
- 모범 사례 제안: 그래프를 텍스트로 인코딩하여 LLM에서 사용하는 최적의 방법론 제시.
6 CONCLUSIONS
이 연구에서는 LLM이 처리할 수 있도록 그래프 구조 데이터를 텍스트로 인코딩하는 방법에 대한 최초의 포괄적인 연구를 제시했습니다. 그래프 추론 작업에서 LLM의 성능이 다음 세 가지 근본적인 수준에서 달라진다는 것을 보여주었습니다.
- 그래프 인코딩 방식,
- 그래프 작업 자체의 특성,
- 그리고 흥미롭게도 고려된 그래프 구조 자체.
이러한 새로운 결과는 그래프를 텍스트로 인코딩하는 전략에 대한 중요한 통찰을 제공하며, 이를 통해 LLM의 그래프 추론 작업 성능을 4.8%에서 최대 61.8%까지 향상시킬 수 있습니다. GraphQA 벤치마크 작업이 이 분야에서 추가적인 연구를 촉진하기를 바랍니다.
'ML & DL > 논문리뷰' 카테고리의 다른 글
| Critique Fine-Tuning:Learning to Critique is More Effective than Learning to Imitate (0) | 2025.02.02 |
|---|---|
| SRMT: SHARED MEMORY FOR MULTI-AGENT LIFE-LONG PATHFINDING (0) | 2025.01.26 |
| A Generalization of Transformer Networks to Graphs (0) | 2025.01.05 |
| KAG: Boosting LLMs in Professional Domains viaKnowledge Augmented Generation (2) | 2024.12.15 |
| Vector Database Management Techniques and Systems (0) | 2024.12.08 |




댓글