원문: https://arxiv.org/pdf/2409.13731v3
1. KAG의 필요성과 성능
- 최근 개발된 RAG(이중 난수 추출) 기술이 분야 특화 애플리케이션의 효율적 구축을 가능하게 하지만, 벡터 유사성과 지식 논리의 민감성 부족 등 한계가 존재한다.
- KAG(Knowledge Augmented Generation)은 이러한 한계를 극복하고 지식 그래프(KG)와 대규모 언어 모델(LLM)을 상호 강화하여 생성 및 추론 성능을 개선하는 것을 목적으로 한다.
- KAG는 다섯 가지 핵심 측면을 통해 LLM과 KG를 양방향으로 강화한다.
- KAG는 기존 RAG방법을 다중 연쇄 질의응답에서 능가하며, 특정 Q&A 과제에 적용해 전문성 향상효과를 입증했다.
- KAG는 곧 오픈소스 KG 엔진 OpenSPG를 통해 개발자들이 더 쉽게 엄격한 지식 추론 및 정보 검색서비스를 구축할 수 있도록 지원할 예정이다.
2. RAG 시스템의 한계와 KAG의 혁신적 접근
- RAG시스템은 다중 단계 및 문단간 작업에서 성능 향상을 위해 지식 그래프를 기술 프레임워크에 도입하였다.
- 기존 RAG및 최적화 과정에서의 문제인 일관성과 논리성 부족이 특정 전문 분야에서 특히 두드러진다.
- 이런 한계는 주로 RAG가 텍스트 또는 벡터의 유사성에 크게 의존하여 검색 결과의 불충분성과 반복을 초래하기 때문이다.
- LLM의 다음 토큰 예측 메커니즘은 논리적 또는 수치적 추론을 효과적으로 다루기 어렵지만, 지식 그래프가 이를 해결하는 데 도움이 될 수 있다.
- 지식 그래프는 명시적인 의미론을 통해 지식 조각의 상호 연결성을 강화하여 자동화된 방식으로 생성된 지식이 도메인 지식을 통해 연결될 수 있게 한다.


3. KAG의 구조와 적용 시나리오
- KAG는 두 개의 전문 분야, E-Government와 E-Health에서 Q&A 시나리오에서 적용된다.
- E-Government에서는 행정 절차에 관한 사용자의 질문을 문서 저장소 기반으로 답변한다.
- E-Health에서는 질병, 증상, 치료와 관련된 질문에 대해 의료 자원을 사용하여 대응한다.
- 실용적인 응용 결과는 KAG가 전통적인 RAG 방법에 비해 상당히 높은 정확도를 달성하여 신뢰성을 향상시킨다.
- Ant Group의 비즈니스 시나리오에 기반한 두 가지 산업 응용 사례가 소개되고, KAG를 사용하여 개발자들이 로컬 응용 프로그램을 구축할 수 있도록 코드가 오픈소스화되었다.
3.1. KAG 프레임워크 및 전문 분야 응용
- KAG는 지식 그래프와 대규모 언어 모델(LLM)을 결합하여 전문 분야에서 지식 증강 생성을 강화하는 새로운 프레임워크이다.
- 최근 개발된 RAG 기술은 도메인 특정 응용 프로그램의 효율적 구축을 가능하게 했지만, 벡터 유사성과 관련성 간의 격차 등 한계가 존재한다.
- KAG는 이러한 RAG의 한계를 극복하기 위해 제안된 것으로 보인다.
- 이를 통해 E-정부 및 E-헬스 분야에서 KAG의 응용이 강조되며, 제안된 방법론과 기술에 대한 배경 및 동기를 제공한다.
3.2. KAG 프레임워크의 구성 요소와 역할
- KAG (Knowledge Augmented Generation)은 전문 지식 서비스의 효과성을 방해하는 문제를 해결하기 위한 프레임워크이다.
- 지식 그래프(Knowledge Graph, KG)와 벡터 검색의 이점을 최대한 활용하기 위해 설계된 구조이다.
- 이 프레임워크는 대규모 언어 모델(LLMs)과 KG를 양방향으로 강화하여 성능을 높인다.
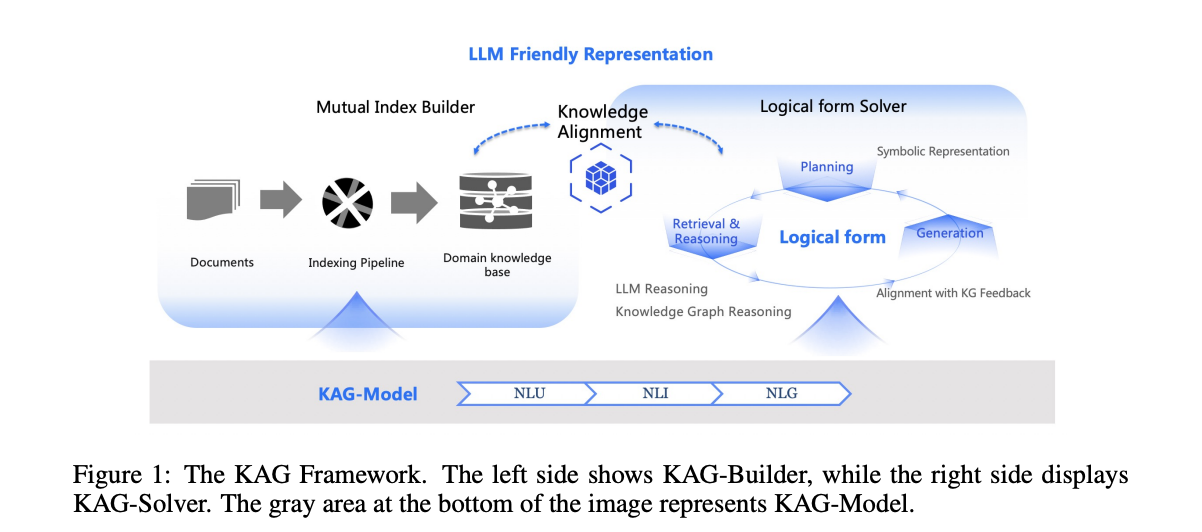
- 다섯 가지 핵심 요소를 포함하며, 대표적으로 LLM 친화적인 지식 표현및 지식 그래프와 원본 청크 사이의 상호 색인화가 있다.
3.3. KAG의 LLM 친화적 지식 표현 및 기술적 개선
- KAG는 하이브리드 추론 엔진, 지식 정렬, 그리고 모델 능력 향상을 포함한 다양한 개선 사항을 통해 기존 RAG방법보다 훨씬 뛰어난 성능을 보여준다.
- 핫팟QA에서 19.6%, 2wiki에서는 33.5%의 상대적 향상을 달성했으며, 이것은 전문 지식 Q&A 업무에서 중요한 향상을 의미한다.
- 오픈소스 KG 엔진인 OpenSPG에서 KAG의 네이티브 지원을 통해 더 높은 정확도와 효율성을 갖춘 도메인 지식 서비스를 개발할 수 있도록 한다.
- RAG시스템은 외부 검색 시스템을 활용하여 도메인별 지식을 획득하고, 이러한 접근 방식이 특별한 도메인의 애플리케이션에 효율적으로 적용될 수 있도록 한다.
- KG의 기술적 방법론을 통해 지식 그래프속의 명시적 의미를 활용해 일관성 있는 답변과 가치를 제공할 수 있게 된다.
3.4. 지식 증강 프레임워크(KAG)의 성과 및 활용 사례
- KAG는 Natural Language Understanding, Natural Language Inference, 그리고 Natural Language Generation을 통해 각 기능 모듈의 성능을 향상시킨다.
- 실험 결과에 따르면 2WikiMultiHopQA, MuSiQue, HotpotQA 세 가지 질의응답 데이터셋에서 KAG가 히포 RAG(Hippo RAG)보다 F1 점수가 각각 19.6%, 12.2%, 12.5% 향상되었다.
- E-Government와 E-Health라는 두 가지 전문 분야에서 KAG를 적용하여 전통적인 RAG방법보다 높은 정확성을 달성하였다.
- KAG는 OpenSPG 오픈 소스 KG 엔진을 통해 더 쉽게 개발자들이 엄격한 지식 의사결정이나 편리한 정보 검색서비스를 구축할 수 있도록 지원한다.
- KAG의 효과성을 복잡한 질의응답 작업에 기반하여 검증하였으며, 코드가 오픈 소스로 공개되어 개발자들이 현지 응용 프로그램을 구축하는 데 도움을 줄 수 있다.
3.5. KAG 프레임워크의 지식 표현 및 향상된 정보 추출 기법
- KAG-Solver는 LLM 추론, 지식 정렬, 수리 논리 추론을 결합하여 지식 표현과 검색의 정확성을 높인다.
- KAG-Model은 일반 언어 모델을 기반으로 각 모듈에 필요한 역량을 최적화하여 성능을 향상시킨다.
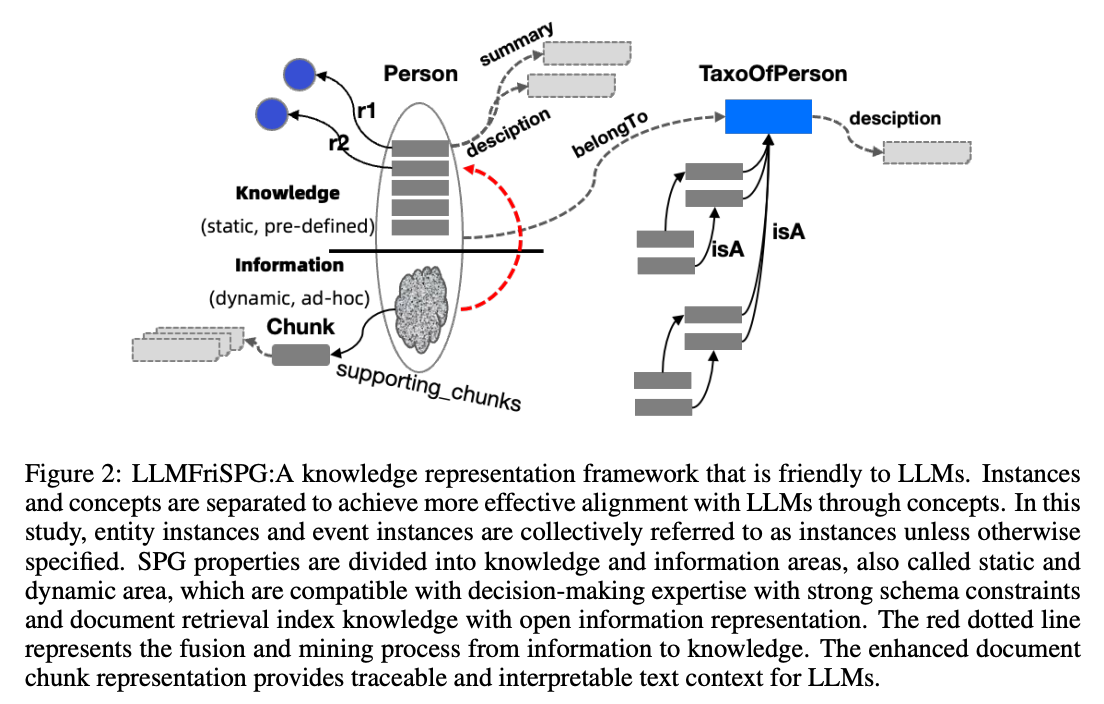
- LLM에 친화적인 지식 표현을 위해 SPG를 심층 텍스트-문맥 인식, 동적 속성 및 지식 계층화 관점에서 업그레이드한 LLMFriSPG를 정의한다.
- LLMFriSPG는 예측 및 해석 가능한 텍스트 문맥을 제공하여 LLM이 특정 인스턴스나 타입의 정확한 의미를 이해하는 데 도움을 주며, 정보 추출, 엔티티 연결, 요약 생성 등의 작업에 사용된다.
- SPG 속성은 정적 및 동적 영역으로 나뉘며, 이는 강력한 스키마 제약을 가진 의사 결정 전문 지식 및 문서 검색 인덱스와 호환된다.
3.6. KAG의 상호 색인 및 지식 관리 메커니즘
- 정적 속성과 동적 속성이 동시에 존재할 수 있으며, 이러한 접근 방식은 전문적인 의사 결정과 정보 검색시나리오에서 균형을 더 잘 맞출 수 있다.
- 정보 검색시나리오는 주로 동적 속성을 구체화하고, 전문적인 의사 결정 시나리오는 주로 정적 속성을 구체화한다.
- 사용자는 비즈니스 시나리오 요구에 따라 사용 편의성과 전문성 간의 균형을 맞출 수 있다.
- 개념은 특정 문서나 인스턴스에 의존하지 않는 일반 상식 지식으로, 다양한 인스턴스가 같은 개념 노드에 연결되어 인스턴스를 분류하는 목적을 달성할 수 있다.
- 개념 그래프를 통해 LLM과 인스턴스 간의 의미적 정렬을 달성할 수 있으며, 이는 지식 검색을 위한 내비게이션으로도 활용될 수 있다.
3.7. ️ KAG의 논리적 형식 처리 및 복합 문제 해결
- KAG는 논리적 형식 처리를 통해 복잡한 문제를 해결하기 위한 계획, 추론, 검색 단계로 구성된다.
- 논리적 형식은 문제를 여러 논리적 표현으로 분해하고, 각각의 표현은 검색 또는 논리 작업을 포함할 수 있다.
- 다단계 해결 메커니즘은 반성과 전역 메모리에 기반하여 설계되며, 구조화된 지식을 통해 다단계 추론을 실행한다. 만약 명확한 답을 얻을 수 없다면 보충 질문을 생성하여 반복한다.
- 논리적 형식 언어 사용의 세 가지 장점은 문제 분해 및 추론의 엄격성을 향상시키고, 대규모 언어 모델을 활용하여 상징적 그래프 구조를 기반으로 사실 및 지식을 검색하며, 문제 분해 및 검색 과정을 통합하여 시스템 복잡성을 줄이는 것이다.
- KAG의 해결 과정은 질문을 서브질문으로 분해, 서브질문의 하이브리드 추론 수행, 저장된 전역 리스트와 대조하여 질문 해결 여부를 판단하는 흐름이다.
3.8. 자연어 이해(NLU)의 성능 향상 방법
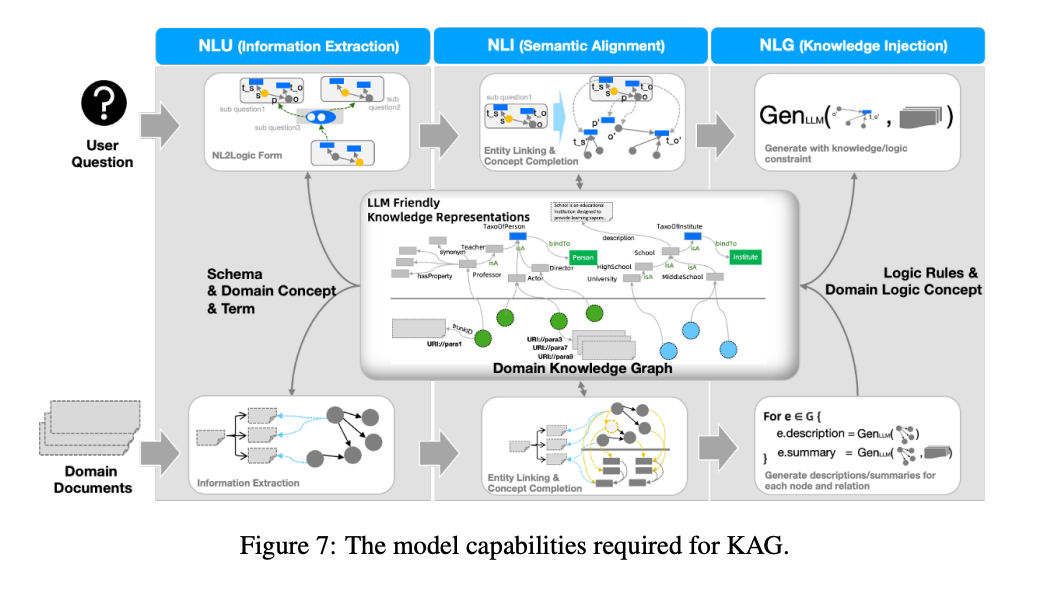
- 구조화된 지식 검색은 명시적인 필터링 기준과 선택 조건을 통해 정확한 검색을 가능하게 한다.
- SPO 형태의 지식을 논리적 기능으로 검색할 수 없으면, 반구조화 및 비구조화 검색이 대안으로 사용된다.
- 정보의 가용성과 특성에 따라 적절한 검색 전략을 활용하여 시스템의 적응성을 강조한다.
- 지식을 구성하고 정렬하기 위해 정보 추출 및 벡터 유사성 기반의 검색이 진행되며, 개념 그래프를 이용해 오프라인 지식 색인을 강화하고 있다.
- KAG모델은 오프라인 색인 구축과 온라인 질의 응답 생성을 통해 효율적인 성능을 보장한다.
3.9. 다중 학습 QA 데이터셋에서의 KAG 평가
- NLI(Natural Language Inference) 작업에는 엔티티 연결, 엔티티 비모호화, 분류 체계 확장, 상위어 발견, 텍스트 포함 및 함의가 포함된다.
- 지식 기반 질의응답(Q&A)에서 자연어 표현의 다양성과 모호성은 구문 간의 미묘하고 다양한 의미론적 연결로 인해 NLI 작업을 통한 추가적인 정렬이나 관련 정보 검색이 자주 필요하다.
4. KAG 및 성능 비교
- KAG프레임워크는 IRCoT + Hippo RAG과 비교했을 때 HotpotQA, 2WikiMultiHopQA, MuSiQue에서 각각 11.5%, 19.8%, 10.5%의 EM 향상을 보였으며, 동일 세 가지 데이터셋에서 F1 점수 또한 각각 12.5%, 19.1%, 12.2% 증가하였다.
- 싱글 스텝 리트리버와 멀티 스텝 리트리버의 성능을 비교한 결과 회수 성능 측면에서 멀티 스텝 리트리버가 대체로 더 우수함이 드러났다.
- 싱글 스텝 리트리버가 검색한 콘텐츠는 유사성이 매우 높아 특정 데이터에 대한 답을 도출하는 데 어려움을 겪었으며, 멀티 스텝 리트리버는 이러한 문제를 해결했다.
- KAG프레임워크는 멀티 스텝 리트리버를 직접 활용하여 상호 인덱싱, 논리 형식 해결 및 지식 정렬과 같은 전략을 통해 검색 성능을 크게 향상시켰다.
4.1. 복합 접근법 성과의 평가
- 여러 검색 및 질문-답변 프레임워크에 대한 평가 방법론과 성능 지표를 논의한다.
- KAG는 지식 그래프와 대규모 언어 모델(LLM)을 결합하여 효과적인 질문-답변프로세스를 지원한다.
- 기존의 RAG기술에 비해 KAG의 성능이 상당히 개선된 것으로 나타났다.
4.2. KAG의 성능 평가 및 비교 분석
- RAG기술은 전문 분야에 특화된 애플리케이션의 효율적인 구성을 가능하게 하지만, 벡터 유사도와 관련성 간의 간극이라는 한계가 존재한다.
- KAG는 이러한 RAG기술의 한계를 극복하기 위해 제안된 새로운 프레임워크이다.
- KAG는 지식 그래프와 대규모 언어 모델(LLM)을 상호 강화하여 더욱 효과적인 질문-답변프로세스를 제공한다.
- Github 링크를 통해 KAG의 자세한 내용을 확인할 수 있다.
4.3. KAG의 성능 및 응용 사례
- KAG은 지식 그래프와 대규모 언어 모델(LLM)을 상호 강화하여 성능을 향상시키는 프레임워크이다.
- 다섯 가지 핵심 측면을 통해 LLM과 KG를 개선하며, 기존의 RAG방법들과 비교하여 multi-hop 질문 응답에서 우수한 성능을 보인다.
- KAG는 HotpotQA에서 19.6%, 2wiki에서 33.5%의 F1 점수 상대적 개선을 달성하였다.
- Ant Group의 E-Government Q&A와 E-Health Q&A 등 두 가지 전문 지식 Q&A 작업에 성공적으로 적용되어 RAG방법과 비교하여 전문성이 향상되었다.
- OpenSPG 오픈소스 KG 엔진에서 KAG를 본격적으로 지원할 예정이며, 이를 통해 정확하고 효율적인 도메인 지식 서비스를 개발할 수 있다.
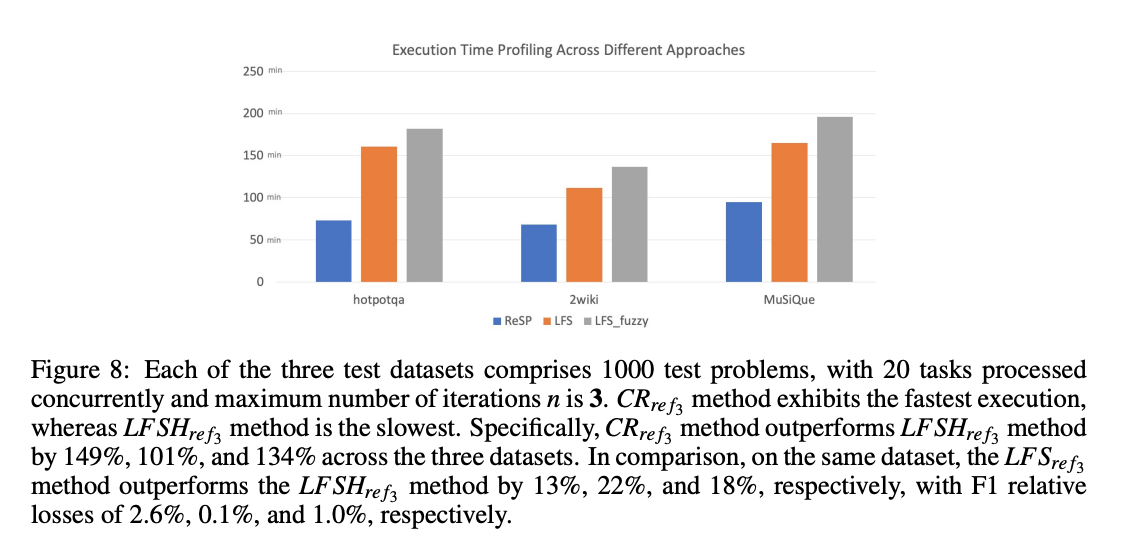
4.4. 지식 증강 생성(KAG)의 핵심 사항
- 전문 분야의 질문-답변성과 향상을 목표로, KAG는 KG와 RAG의 상호 보완적인 특성을 활용한 프레임워크이다.
- KAG는 LLM 친화적인 지식 표현을 통해 정보 추출 및 전문 지식의 구성, 그래프 기반 색인의 구축을 지원한다.
- 자연어를 문제 해결 과정으로 변환하는 논리형 가이드 하이브리드 추론 엔진을 제안하여, 해당 과정에서 다양한 연산자와 추론 과정을 통합하여 활용한다.
- 의미론적 추론에 기반한 지식 정렬 접근 방식을 제안하여, 다양한 의미 관계를 정의하고 오프라인 색인 및 온라인 검색 단계에서 단편적인 지식을 정렬하고 연결한다.
- KAG는 세 가지 복잡한 데이터 세트에 대해 평가되었으며, 기존 방법보다 19.6%, 12.2% 및 12.5% 만큼의 F1 점수를 향상시켰다.
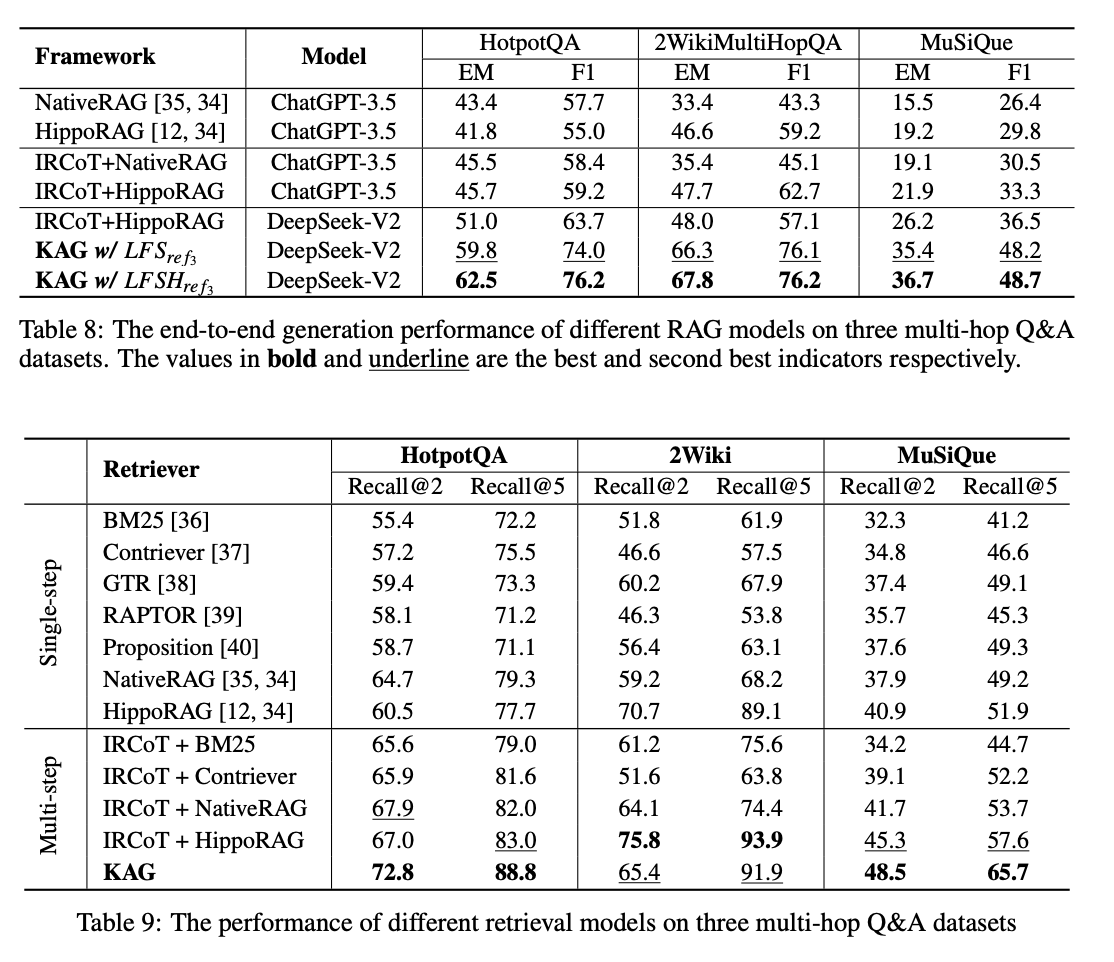
4.5. KAG 프레임워크의 특성과 데이터 표현 방식
- KAG프레임워크는 내장 속성을 사용하여 시스템을 구성하는데, 여기에는 지원하는 청크(supporting chunks), 설명(description), 개요(summary), 그리고 속한 항목(belongTo) 등이 포함된다.
- 청크 생성 전략과 설명의 최대 길이는 사용자가 정의하며, 이는 KAG빌더 단계에서 반영된다.
- 설명은 특정 인스턴스나 타입에 부여될 수 있는데, 타입에 부여될 경우 전역적 설명(global description) 을 의미하고, 특정 인스턴스에 부여될 때에는 문서의 맥락과 일치하는 일반적 설명으로 사용된다.
- 이러한 설명은 LLM이 특정 인스턴스나 타입의 정확한 의미를 이해하고 정보 추출, 엔티티 연결, 개요 생성 등의 작업을 수행하는 데 효과적이다.
- 속한 항목(belongTo) 는 원본 문서 맥락에서 귀납적 의미를 나타내며, 이를 통해 인스턴스를 개념으로 연관 지을 수 있다.
4.6. 전문 분야에서의 정보 검색 및 의사 결정 과정의 구조적 접근
- 전문 분야 의사 결정과 정보 검색이 두 가지 주요 시나리오로 구분된다. 전자는 주로 정적 속성을, 후자는 동적 속성을 구현한다.
- 사용자는 사업 시나리오 요구 사항에 따라 전문성과 이용 편의성 간의 균형을 맞출 수 있다.
- 개념 그래프는 LLM과 인스턴스 간의 의미적 정렬을 가능케 하며, 지식 검색의 내비게이션 역할을 한다.
- KG 지식 계층은 도메인 스키마 제약을 준수하며 요약, 통합 및 평가된 도메인 지식을 나타낸다.
- SPG 계층은 높은 지식 정확성과 논리적 엄밀성을 가지지만, 수작업에 의존하여 높은 노동 비용과 정보 완전성 부족의 단점을 지닌다.
4.7. 지식 그래프와 문서의 상호 연계
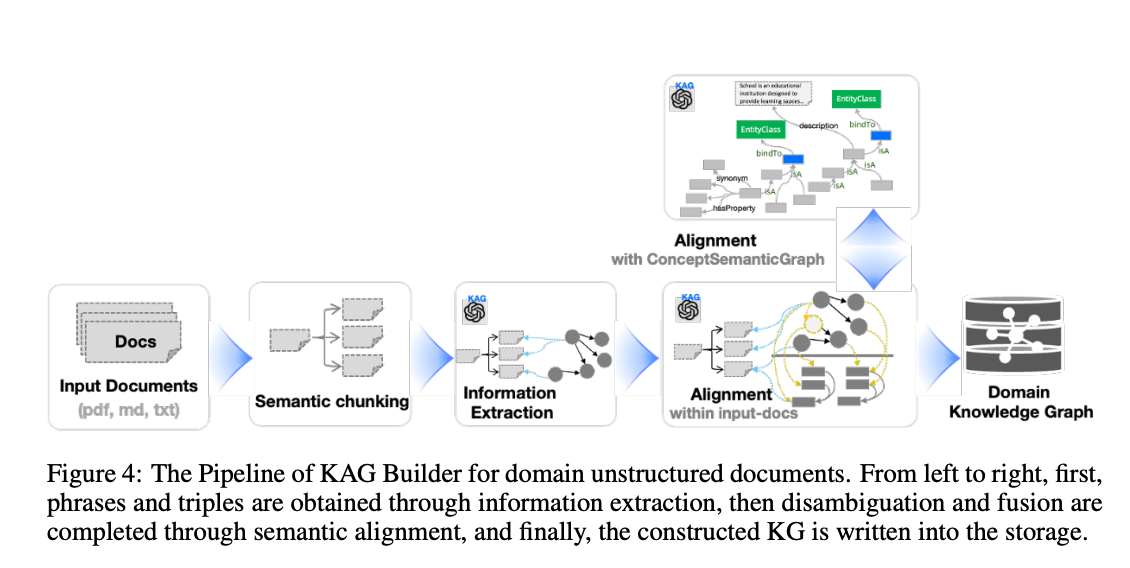
- 지식 그래프는 문서의 텍스트와 그래프 구조 간의 상호 색인을 구축하여 설명적 문맥을 추가한다.
- 의미론적 청킹은 문서의 구조적 계층과 논리적 연결을 바탕으로 하여, 내용의 테마적 일관성을 보장하는 청킹을 생성한다.
- 문서 및 분할된 청크 사이의 상호 연계 관계가 유지되어 맥락을 쉽게 이해할 수 있다.
- 정보 추출 과정에서는 개체별로 기본 속성 설명, 요약 및 의미 유형을 생성하여 LLM으로 문장 내 정보의 구체적인 집합을 만든다.
- KAG의 상호 색인 메커니즘은 LLM의 의미 표현을 따르며, 다양한 범주의 데이터 구조를 포함한다.
5. KAG 프레임워크의 주요 과제 및 발전 방향
- KAG프레임워크의 현 버전은 다양한 제약사항을 가지고 있으며, 다수의 LLM 호출이 필수적이어서 계산량과 경제적 부담을 초래하고 있다.
- 문제 분해 및 기호 표현을 위한 중간 토큰의 수가 광범위하게 필요하여 약 두 배의 생성 토큰을 필요로 한다.
- 기존에는 큰 모델을 사용하여 엔티티 인식, 관계 추출 등을 수행하였으나, 이는 전체 실행 시간을 상당히 증가시킨다.
- 복잡한 문제를 계획하고 분해하는 것은 높은 수준의 역량을 요구하며, 현재로서는 복잡한 문제 해결에 있어 계획 능력 향상이 필요하다.
- 지식 정렬의 기술적 과제를 해결하기 위해, 여러 라운드의 지식 추출의 정확성과 일관성을 최적화할 필요가 있다.
5.1. KAG 프레임워크의 소개와 제한 사항
- KAG는 전문 분야의 질문-답변(QA) 시나리오에서 큰 성과를 위해 제안된 새로운 프레임워크이다.
- KAG는 지식 그래프와 대규모 언어 모델(LLM)을 상호 강화한다는 점에서 주목받고 있다.
- 이 프레임워크는 기존 방법에 비해 효율적이지만, QA 시나리오에서의 적용 가능성에 한계도 존재한다.
- KAG는 다양한 전문 지식 서비스분야에 실용적으로 적용될 수 있는 가능성을 제시한다.
5.2. KAG 프레임워크의 도전 과제
- RAG 기술은 도메인 특화 애플리케이션의 효율적인 구축을 가능하게 하였지만 한계도 존재한다.
- RAG의 한계는 벡터 유사성과 지식 추론 간의 차이로 인해 생겨난다.
- 지식 논리에 대한 민감성 부족, 예를 들어 숫자 값, 시간 관계, 전문가 규칙이 주요 문제이다.
5.3. KAG 프레임워크의 설계 및 핵심 특징
- KAG(Knowledge Augmented Generation)는 전문 분야지식 서비스의 복잡한 문제를 해결하기 위해 설계된 프레임워크이다.
- 이 프레임워크는 지식 그래프(KG)와 벡터 검색을 활용하여 대규모 언어 모델(LLMs)을 양방향으로 강화함으로써 생성 및 추론 성능을 향상시키는 것을 목표로 한다.
- 다섯 가지 주요 측면으로 구성되며, 첫 번째는 LLM에 적합한 지식 표현이다.
- 두 번째는 지식 그래프와 원본 청크 간의 상호 색인화이고, 세 번째는 논리 형식에 기반한 하이브리드 추론 엔진이다.
- 네 번째는 의미적 추론과의 지식 정렬이며, 마지막으로 다섯 번째는 KAG를 위한 모델 능력의 향상이다.
5.4. KAG 적용 및 성과
- KAG는 HotpotQA에서 F1 스코어의 19.6%, 그리고 2wiki에서 33.5%의 상대적 성과 향상을 달성한 것으로 나타난다.
- Ant Group의 E-정부 Q&A와 E-헬스 Q&A 같은 전문 지식 Q&A 작업에서 KAG를 적용하여 RAG방법들에 비해 전문성이 크게 향상되었다.
- KAG는 곧 오픈 소스 KG 엔진 OpenSPG에서 지원될 예정이며, 이를 통해 개발자들이 보다 엄격한 지식 결정 지원이나 편리한 정보 검색서비스를 구축할 수 있게 될 것이다.
- KAG의 향후 지원은 이 기술의 로컬화된 개발을 장려하며 개발자들이 혁신적인 애플리케이션을 구현할 수 있는 기회를 제공한다.
5.5. KAG 프레임워크 내 지식 그래프의 중요성
- Retrieval-Augmented Generation (RAG) 기술은 빠르게 발전하고 있다.
- RAG는 대규모 언어 모델(LLMs)이 지식을 획득하는 능력을 갖추는 데 핵심적인 역할을 하고 있다.
- KAG프레임워크는 이러한 RAG기술을 바탕으로 전문 분야의 높은 정확도와 효율성을 갖춘 지식 서비스를 제공할 수 있다.
5.6. KAG 프레임워크의 지식 정렬 한계와 개선 필요성
- 도메인 특화 지식을 통한 기술 개선은 외부 검색 시스템을 활용하여 답변의 환각 발생을 크게 줄이고 특정 분야의 응용 프로그램을 효율적으로 구축할 수 있게 한다.
- RAG시스템의 성능을 향상시키기 위해 지식 그래프가 도입되었으며, 이는 다중 홉 및 교차 단락 작업에서 강력한 추론 능력을 보여준다.
- RAG와 그 최적화는 대부분의 환각 문제를 해결했지만, 생성된 텍스트는 여전히 일관성과 논리성이 부족하며, 특히 법률, 의학, 과학 같은 전문 분야에서 분석적 추론이 필요한 경우에는 적절한 답변을 제공할 수 없는 한계를 지닌다.
- 이러한 문제의 주요 원인은 세 가지로 요약되는데, 첫째로 실제 비즈니스 과정은 일반적으로 지식 조각 간의 특정 관계에 기반한 추론적 이유를 필요로 한다.
- 그러나 RAG는 일반적으로 참조 정보를 검색할 때 텍스트나 벡터의 유사성에 의존하여, 불완전하거나 반복적인 검색 결과를 초래할 수 있다.
5.7. KAG 프레임워크 개선 방안
- 자연어 모델의 다음 토큰 예측 메커니즘은 복잡한 문제를 해결하기에 여전히 약점이 있다.
- 지식 그래프는 명시적인 의미론을 사용하여 정보를 정리하며, SPO 트리플을 구성하여 명확한 엔티티 유형과 관계를 가진다.
- 동일한 의미지만 다르게 표현된 엔티티는 엔티티 정규화를 통해 통합될 수 있으며, 이는 중복을 줄이고 지식의 상호 연결성을 향상시킨다.
- 검색 시 SPARQL이나 SQL과 같은 쿼리 구문을 사용하면 엔티티 유형을 명시적으로 지정할 수 있어, 동일한 이름의 잡음을 줄일 수 있다.
5.8. KAG의 관계 기반 지식 검색 기능
- KAG는 쿼리 요구에 기반한 관계를 명시하여, 추론적 지식 검색이 가능하다.
- 비슷하고 중요한 인접 콘텐츠로 불필요하게 확장하는 것을 피할 수 있다.
5.9. 지식 그래프와 LLM의 상호작용
- 지식 그래프에서 얻은 결과는 명시적 의미를 가지고 있어서 특정한 변수로 사용될 수 있다.
- 이는 LLM의 계획 및 함수 호출 기능의 추가 활용을 가능하게 한다.
- 검색 결과는 함수 매개 변수의 변수로 대체되어 결정론적 추론을 수행한다.
- 결정론적 추론에는 수치 계산 및 집합 연산이 포함된다.
5.10. KAG: 전문 지식 분야에서의 지식 증강 생성
- 지식 증강 생성(KAG)은 전문 분야의 지식 서비스 요구를 충족시키기 위해 KG와 RAG기술의 상호 보완적 특징을 활용한다.
- KAG는 다양한 연산자를 통해 문제 해결 과정을 자연어와 기호를 결합하여 수행하며, 이는 정보 검색과 언어 추론, 수치 계산을 포함한다.
- KG 기반 인덱스 구축과 조화로운 지식 표현을 위한 다양한 모듈을 제안하고, 이로써 일반 LLM의 3가지 특정 능력을 강화한다: 자연어 이해(NLU), 자연어 추론(NLI), 자연어 생성(NLG).
- 세 가지 복잡한 Q&A 데이터셋에서 KAG의 성능을 평가한 결과, F1 점수가 모두 상당히 개선되었으며, 검색 지표 또한 눈에 띄게 향상되었다.
- KAG는 두 가지 전문 분야Q&A 시나리오에 적용되었으며, 기존 RAG방법 대비 현저히 높은 정확도를 달성하여 전문 분야Q&A 애플리케이션의 신뢰성을 향상시켰다.




댓글