원본 링크: https://towardsdatascience.com/mastering-customer-segmentation-with-llm-3d9008235f41#3a33
Mastering Customer Segmentation with LLM
Unlock advanced customer segmentation techniques using LLMs, and improve your clustering models with advanced techniques
towardsdatascience.com
Intro
고객 세분화 태스크는 여러 가지 방법으로 접근할 수 있습니다. 이 글에서는 클러스터를 정의하는 것뿐만 아니라 결과를 분석하는 고급 기법을 알려드리겠습니다. 이를 통해 클러스터링 문제를 해결할 수 있는 여러 가지 도구를 갖추고, 시니어 DS(!)에 한 걸음 더 다가갈 수 있습니다.
<고객 세분화 태스크에 접근하는 3가지 방법>
Kmeans
K-Prototype
LLM + Kmeans

<세분화 태스크를 위한 차원 축소 기법>
PCA
t-SNE
MCA

노트북이 포함된 깃헙:
https://github.com/damiangilgonzalez1995/Clustering-with-LLM
EDA, 피쳐 선택 과정은 생략되었다고 합니다.
Data
프로젝트에서 사용된 데이터: "Banking Dataset - Marketing Targets"
https://www.kaggle.com/datasets/prakharrathi25/banking-dataset-marketing-targets
Banking Dataset - Marketing Targets
Banking Dataset of different customers to predict if they will convert or not.
www.kaggle.com
데이터셋에는 다음과 같은 8개의 열이 있습니다.
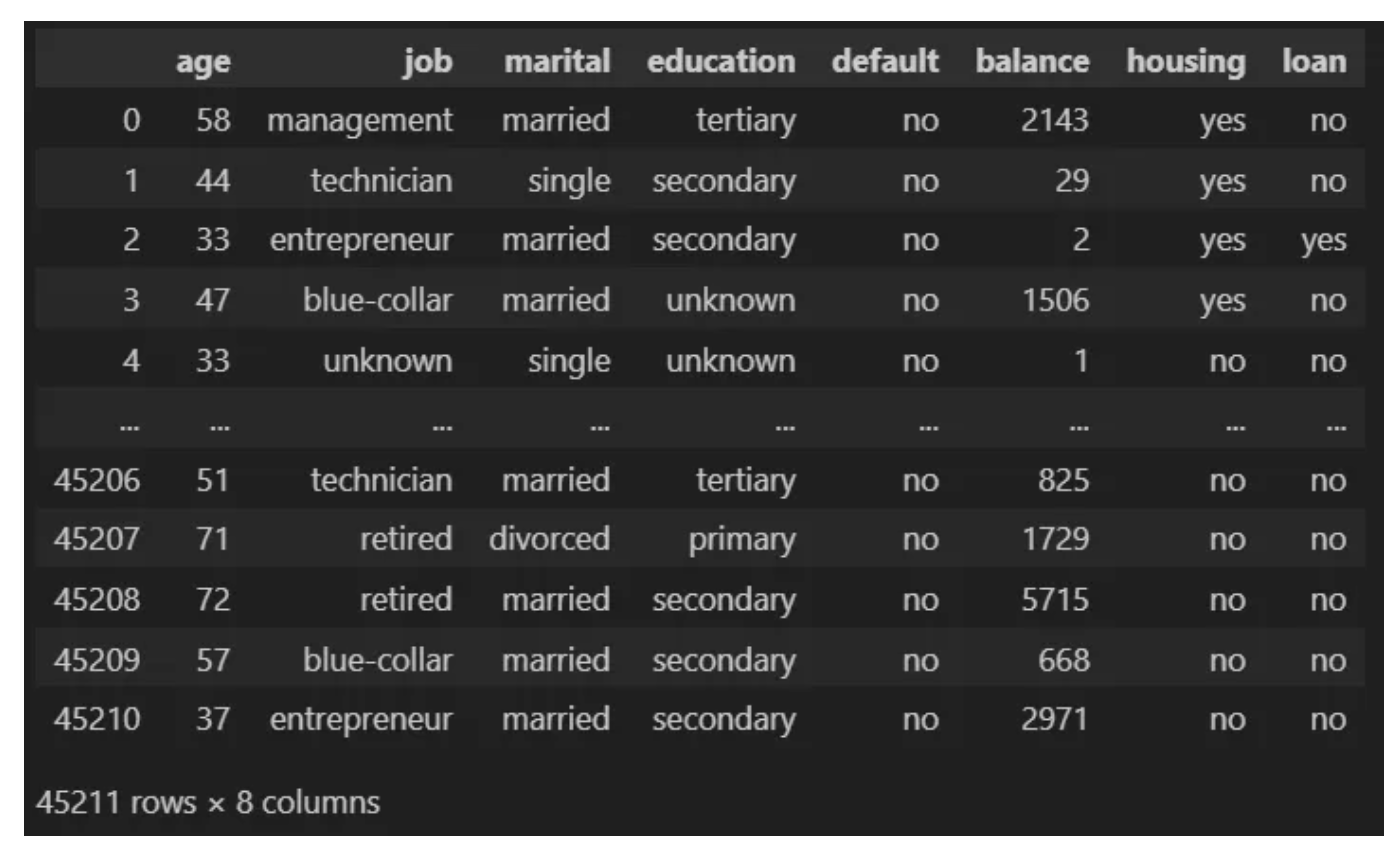
- age: 나이 (숫자형)
- job: 직업 유형 (범주형: "admin.", "unknown", "unemployed", "management", "housemaid", "entrepreneur", "student", "blue-collar", "self-employed", "retired", "technician", "services")
- marital: 결혼 상태 (범주형: "married", "divorced", "single". "divorced"는 이혼 또는 사별을 의미)
- education: 교육 수준 (범주형: "unknown", "secondary", "primary", "tertiary")
- default: 신용 불량 여부 (이진형: "yes", "no")
- balance: 연간 평균 잔고 (숫자형, 유로)
- housing: 주택 대출 여부 (이진형: "yes", "no")
- loan: 개인 대출 여부 (이진형: "yes", "no")
프로젝트에는 Kaggle에서 제공한 훈련 데이터셋을 사용했습니다. 프로젝트 저장소에는 "data" 폴더가 있고, 그 안에 프로젝트에서 사용된 데이터셋의 압축 파일이 저장되어 있습니다. 압축 파일 안에는 두 개의 CSV 파일이 있는데, 하나는 Kaggle에서 제공한 훈련 데이터셋(train.csv)이고, 다른 하나는 임베딩을 수행한 후의 데이터셋(embedding_train.csv)입니다. 임베딩에 대해서는 나중에 더 자세히 설명하겠습니다.
프로젝트의 구조를 더 명확히 하기 위해 프로젝트 트리를 보여드렸습니다. 데이터 폴더, 이미지 폴더, 각 클러스터링 기법에 대한 노트북 파일, 임베딩 생성 스크립트, 그리고 README 파일로 구성되어 있습니다.

LLM + Kmeans
LLM은 서면 텍스트를 직접 이해할 수 없으므로 이러한 유형의 모델 입력을 변환해야 합니다. 이를 위해 문장 임베딩이 수행됩니다. 이는 텍스트를 숫자 벡터로 변환하는 것으로 구성됩니다.
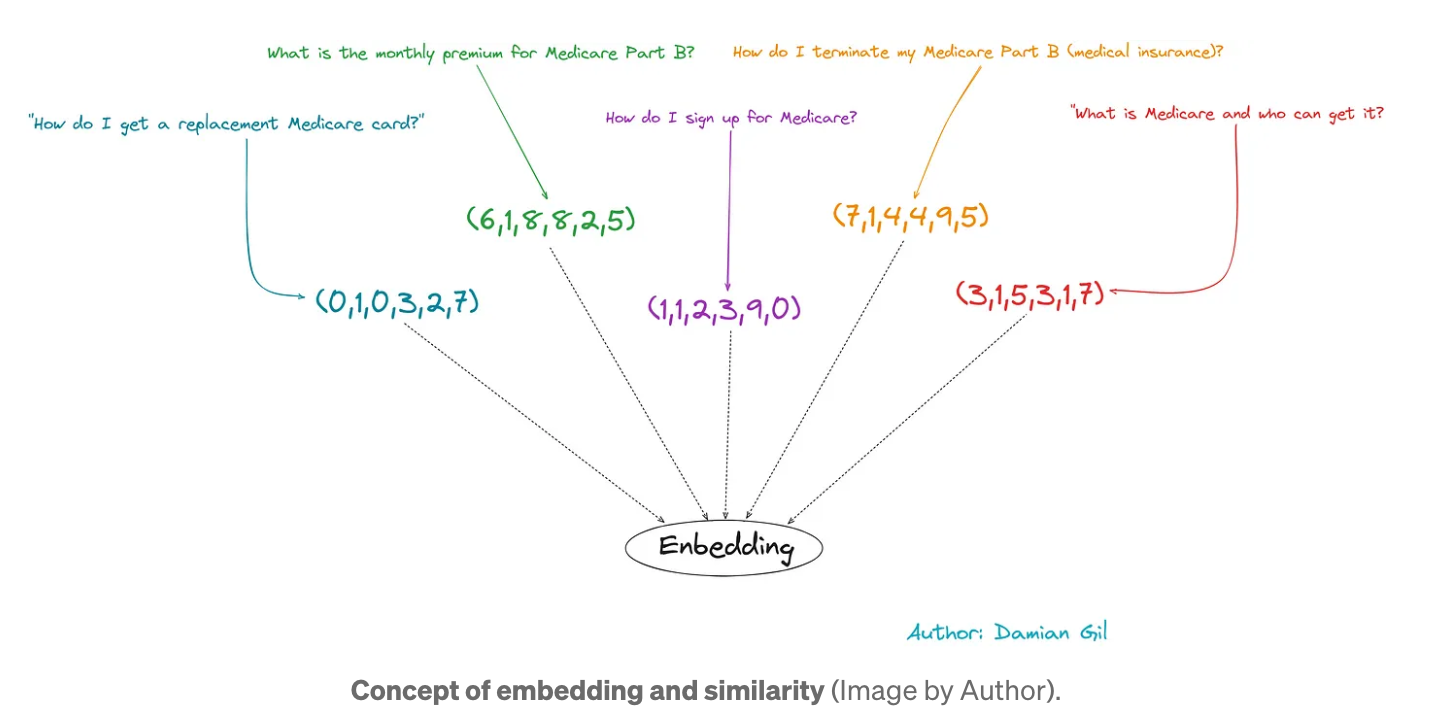
비슷한 의미를 포함하는 문구는 더 유사한 벡터를 갖게 됩니다.

문장 임베딩은 특화된 알고리즘을 통해 수행됩니다. 일반적으로 이 인코딩에서 나오는 숫자 벡터의 크기를 선택할 수 있는데, 여기에 핵심 포인트 하나가 있습니다.
임베딩으로 생성된 벡터의 크기가 커지면 데이터의 작은 변화도 더 정밀하게 볼 수 있습니다.
따라서 정보가 풍부한 Kmeans 모델에 입력을 제공하면 더 나은 예측 결과를 얻을 수 있습니다. 이것이 이 글의 핵심 아이디어이며 아래 단계로 나눌 수 있습니다.
1. 문장 임베딩을 통해 원본 데이터 세트 변환하기
2. Kmeans 모델 생성
3. 평가하기
첫 번째 단계는 문장 임베딩을 통해 정보를 인코딩하는 것입니다. 각 클라이언트의 정보를 가져와서 모든 특성을 포함하는 텍스트로 통합하는 것이 목적입니다. 이 부분은 컴퓨팅 시간이 많이 걸립니다. 그래서 이 작업을 수행하는 스크립트인 embedding_creation.py를 만들었습니다. 이 스크립트는 학습 데이터 세트에 포함된 값을 수집하고 임베딩에서 제공하는 새로운 데이터 세트를 생성합니다. 다음은 스크립트 코드입니다.
https://github.com/damiangilgonzalez1995/Clustering-with-LLM/blob/main/embedding_creation.py
import pandas as pd # dataframe manipulation
import numpy as np # linear algebra
from sentence_transformers import SentenceTransformer
df = pd.read_csv("data/train.csv", sep = ";")
# -------------------- First Step --------------------
def compile_text(x):
text = f"""Age: {x['age']},
housing load: {x['housing']},
Job: {x['job']},
Marital: {x['marital']},
Education: {x['education']},
Default: {x['default']},
Balance: {x['balance']},
Personal loan: {x['loan']},
contact: {x['contact']}
"""
return text
sentences = df.apply(lambda x: compile_text(x), axis=1).tolist()
# -------------------- Second Step --------------------
model = SentenceTransformer(r"sentence-transformers/paraphrase-MiniLM-L6-v2")
output = model.encode(sentences=sentences,
show_progress_bar=True,
normalize_embeddings=True)
df_embedding = pd.DataFrame(output)
df_embedding이 단계를 이해하는 것이 매우 중요하기 때문에 단계별로 살펴보겠습니다.
1단계: 전체 고객/행 정보를 포함하는 각 행에 대한 텍스트가 생성됩니다. 또한 나중에 사용할 수 있도록 파이썬 리스트에 저장합니다.

2단계: 트랜스포머를 호출하는 단계입니다. 이를 위해 HuggingFace에 저장된 모델을 사용할 것입니다. 이 모델은 토큰과 단어 수준에서 인코딩하는 데 중점을 둔 Bert의 모델과 달리 문장 수준에서 임베딩을 수행하도록 특별히 훈련되었습니다. 이 모델을 호출하려면 리포지토리 주소(이 경우 "sentence-transformers/paraphrase-MiniLM-L6-v2")만 제공하면 됩니다. 각 텍스트에 대해 반환되는 숫자 벡터는 Kmeans 모델이 입력의 척도에 민감하기 때문에 정규화됩니다. 생성된 벡터의 길이는 384입니다. 이 벡터를 사용하여 동일한 수의 열을 가진 데이터 프레임을 만듭니다.
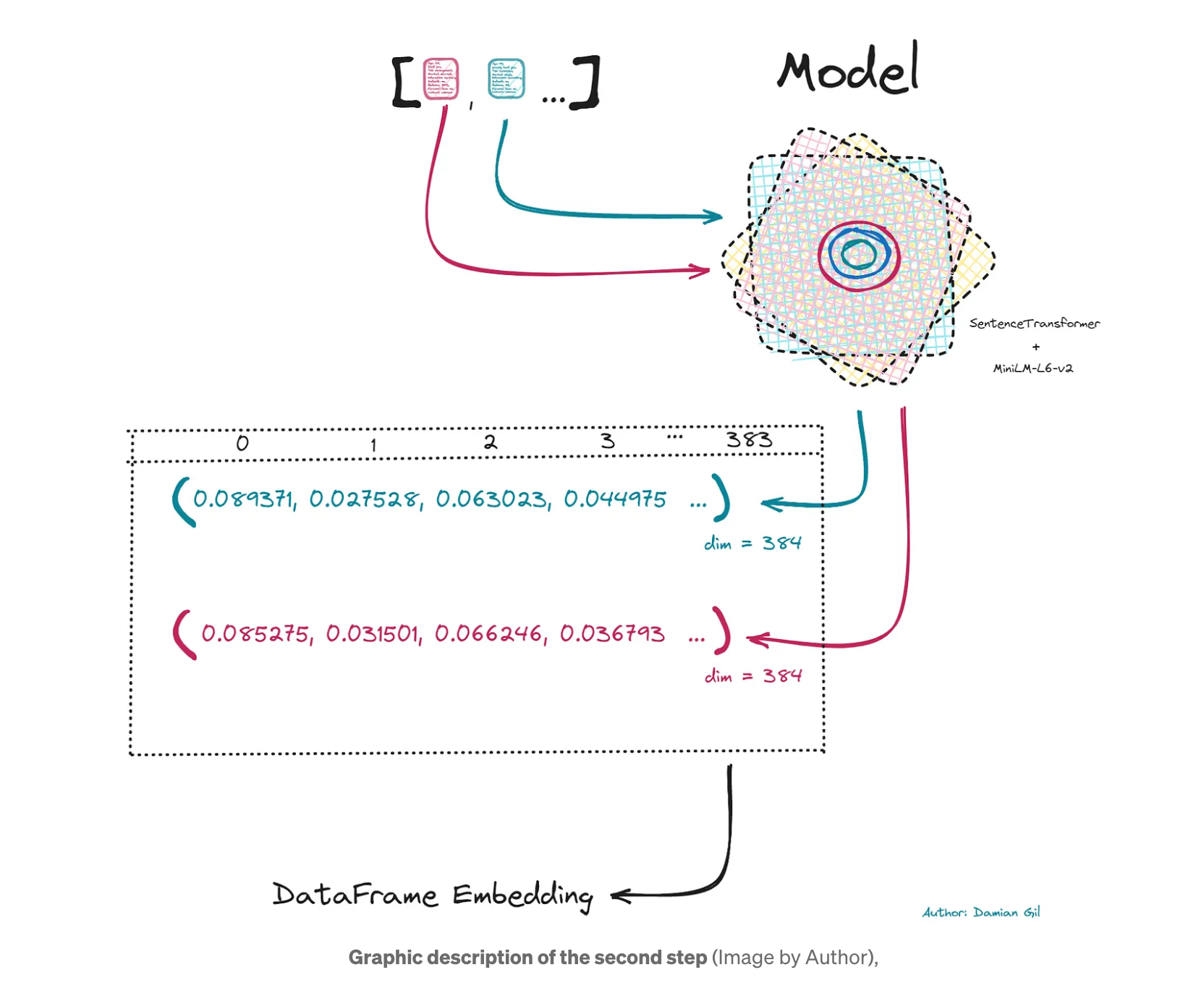
마지막으로 임베딩에서 데이터 프레임을 얻는데, 이 데이터 프레임은 Kmeans 모델의 입력이 될 것입니다.

이 단계는 가장 흥미롭고 중요한 단계 중 하나로, 앞으로 생성할 Kmeans 모델의 입력을 생성합니다.
생성 및 평가 절차는 위에 표시된 것과 유사합니다. 게시물이 지나치게 길어지지 않도록 각 포인트의 결과만 표시합니다. 모든 코드는 임베딩이라는 주피터 노트북에 포함되어 있으므로 직접 결과를 재현할 수 있습니다.
https://github.com/damiangilgonzalez1995/Clustering-with-LLM/blob/main/embedding.ipynb
또한 문장 임베딩을 적용한 결과의 데이터 세트는 csv 파일로 저장됩니다. 이 csv 파일의 이름은 embedding_train.csv입니다. Jupyter 노트북에서 해당 데이터 세트에 액세스하여 이를 기반으로 모델을 생성하는 것을 볼 수 있습니다.
# Normal Dataset
df = pd.read_csv("data/train.csv", sep = ";")
df = df.iloc[:, 0:8]
# Embedding Dataset
df_embedding = pd.read_csv("data/embedding_train.csv", sep = ",")Preprocessed
임베딩을 전처리로 간주합니다.
Outliers
이상값을 탐지하기 위해 이미 제시된 방법인 ECOD를 적용합니다. 이러한 유형의 포인트가 포함되지 않은 데이터 집합을 만듭니다.
df_embedding_no_out.shape -> (40690, 384)
df_embedding_with_out.shape -> (45211, 384)Modeling
먼저 최적의 클러스터 수가 얼마인지 알아내야 합니다. 이를 위해 엘보 방법을 사용합니다.
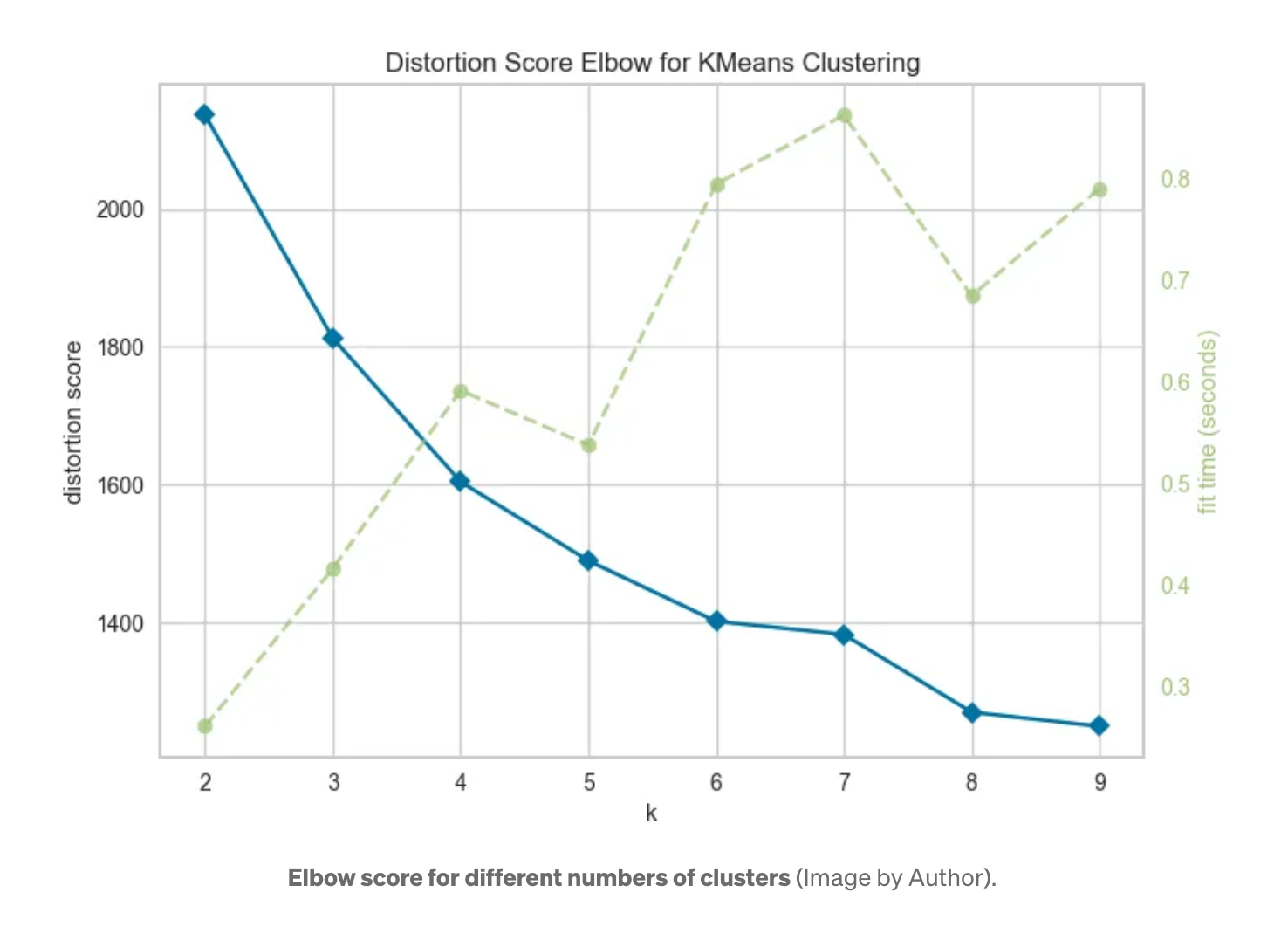
다양한 클러스터 수에 대한 엘보 점수 그래프를 그려 본 후 클러스터 수로 k=5를 선택합니다.
n_clusters = 5
clusters = KMeans(n_clusters=n_clusters, init = "k-means++").fit(df_embedding_no_out)
print(clusters.inertia_)
clusters_predict = clusters.predict(df_embedding_no_out)Evaluation
다음은 k=5로 Kmeans 모델을 만드는 것입니다. 이제 다음과 같은 메트릭을 얻을 수 있습니다.
Davies bouldin score: 1.8095386826791042
Calinski Score: 6419.447089002081
Silhouette Score: 0.20360442824114108
PCA 분석으로 얻은 표현을 살펴봅시다.

클러스터가 기존 방식보다 훨씬 더 잘 차별화되는 것을 볼 수 있습니다. 이것은 좋은 소식입니다. PCA 분석의 처음 세 가지 구성 요소에 포함된 변동성을 고려하는 것이 중요하다는 점을 기억하세요. 경험상 약 50%(3D PCA)가 되면 어느 정도 명확한 결론을 도출할 수 있다고 말할 수 있습니다.
그러면 3개 구성 요소의 누적 변동성이 40.44%이며, 이는 허용 가능한 수준이지만 이상적이지는 않다는 것을 알 수 있습니다.
클러스터가 얼마나 조밀한지 시각적으로 확인할 수 있는 한 가지 방법은 3D 표현에서 포인트의 불투명도를 수정하는 것입니다. 즉, 포인트가 특정 공간에 모여 있으면 검은 점이 관찰될 수 있습니다. 두 번째 차원 축소 방법을 사용하여 얻은 개선이 눈에 띕니다. 2D 비교를 살펴보겠습니다.
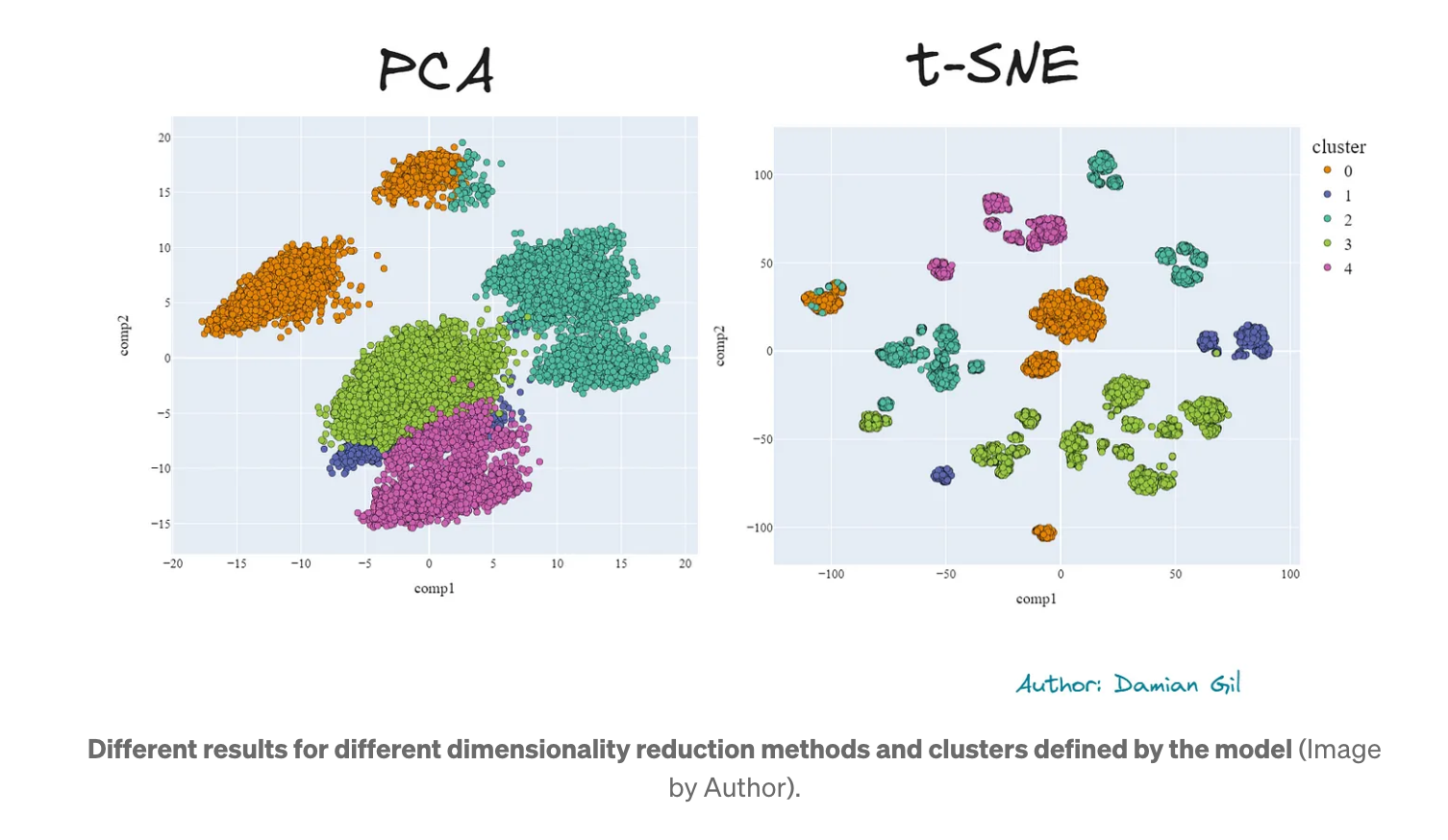
다시 말하지만, t-SNE의 클러스터가 PCA보다 더 분리되고 더 잘 구분되는 것을 볼 수 있습니다. 또한 품질 측면에서 두 방법의 차이는 기존의 Kmeans 방법을 사용할 때보다 더 작습니다.
Kmeans 모델이 어떤 변수에 의존하는지 이해하기 위해 이전과 동일한 방법으로 분류 모델(LGBMClassifier)을 만들고 특징의 중요도를 분석합니다.
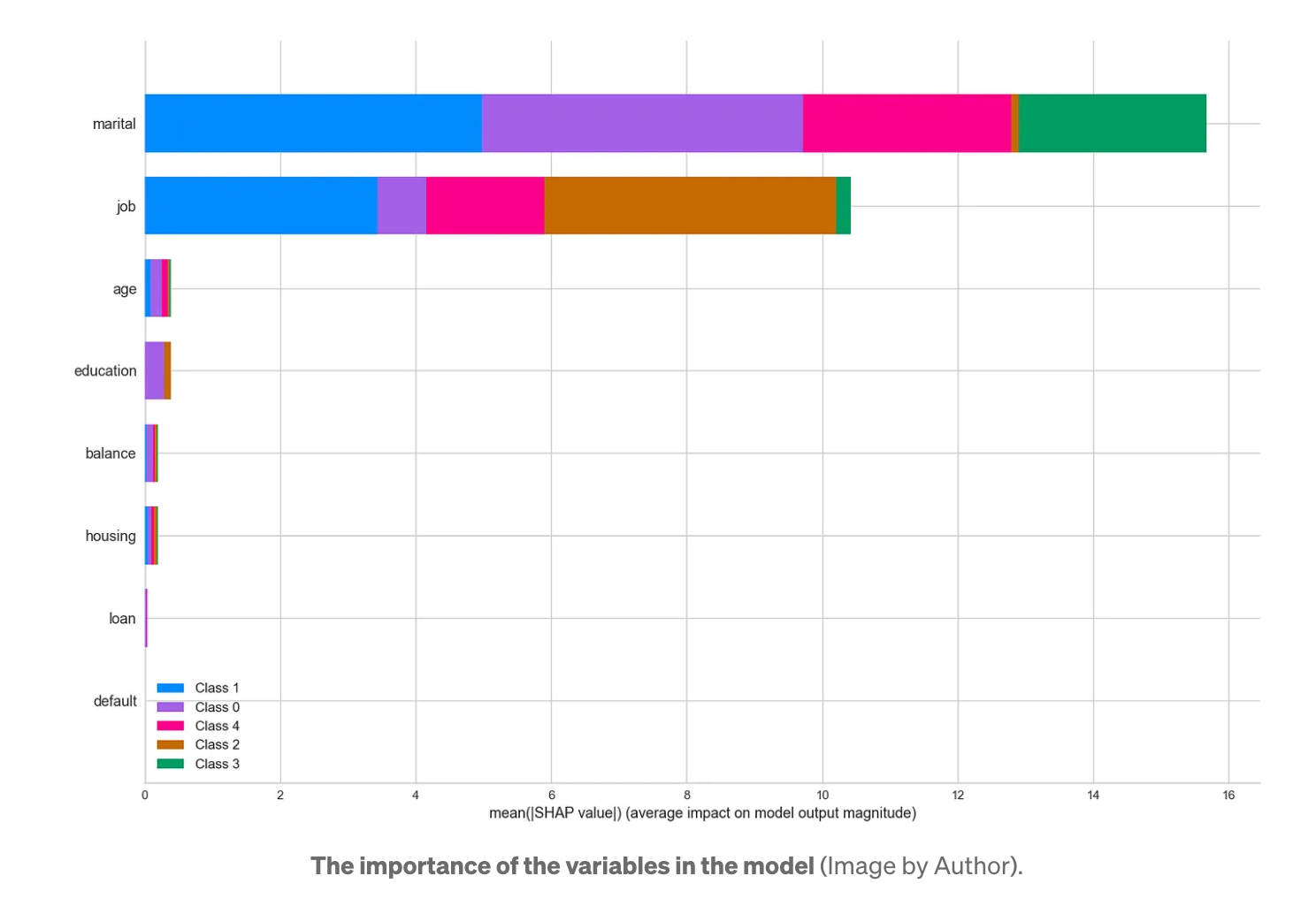
이 모델은 무엇보다도 '결혼'과 '직업' 변수에 기반하고 있음을 알 수 있습니다. 반면에 많은 정보를 제공하지 않는 변수가 있다는 것을 알 수 있습니다. 실제 사례에서는 이러한 변수를 제외하고 정보가 거의 없는 새로운 버전의 모델을 만들어야 합니다.
더 적은 수의 변수가 있어야 좋은 예측을 할 수 있기 때문에 Kmeans + Embedding 모델이 더 최적입니다. 좋은 소식입니다!
가장 핵심적이고 중요한 부분으로 마무리합니다.
관리자와 비즈니스는 PCA, t-SNE 또는 임베딩에 관심이 없습니다. 그들이 원하는 것은 이 경우 고객의 주요 특성이 무엇인지 알 수 있는 것입니다.
이를 위해 각 클러스터에서 찾을 수 있는 주요 프로필에 대한 정보가 포함된 표를 만듭니다.
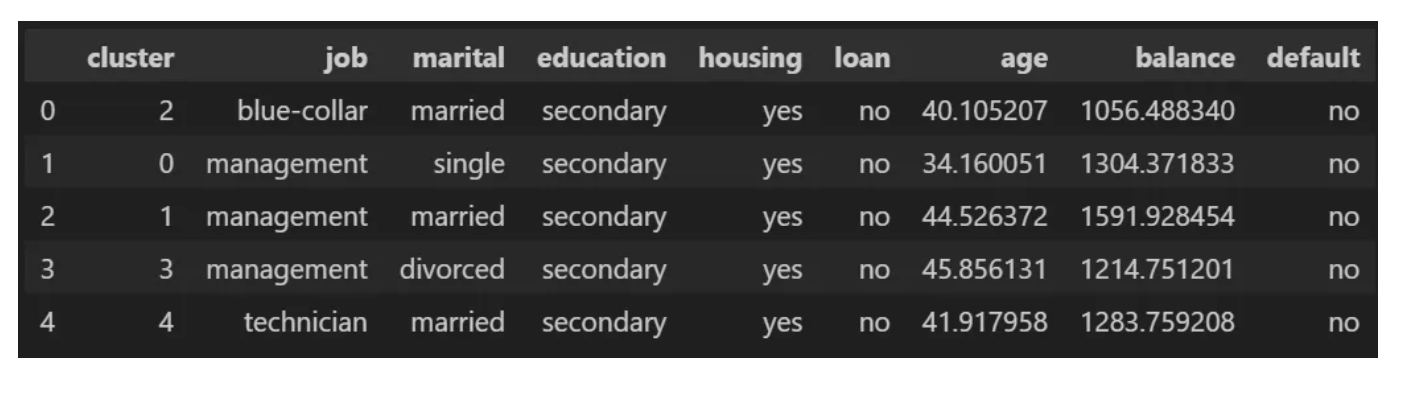
매우 흥미로운 점은 '관리자' 직책이 가장 많은 클러스터가 3개라는 점입니다. 여기서 우리는 독신 관리자는 젊고, 기혼자는 나이가 많고, 이혼자는 나이가 많다는 매우 특이한 행동을 발견할 수 있습니다. 반면에 잔액은 다르게 행동하여 미혼자는 이혼한 사람보다 평균 잔액이 더 높고 기혼자는 평균 잔액이 더 높습니다. 말씀하신 내용은 다음 이미지로 요약할 수 있습니다.

이 결과는 현실과 사회적 측면에 부합합니다. 또한 매우 구체적인 고객 프로필을 보여줍니다. 이것이 바로 데이터 과학의 마법입니다.
Conclusion
결론은 분명합니다.

실제 프로젝트에서는 모든 전략이 효과가 있는 것은 아니며 가치를 더할 수 있는 리소스가 있어야 하기 때문에 다양한 도구가 필요합니다. 그러나 LLM의 도움이 효과가 있는 것은 분명해 보입니다.
'ML & DL > 책 & 강의' 카테고리의 다른 글
| [밑시딥2] CHAPTER 4 (4) | 2024.07.15 |
|---|---|
| [나는 리뷰어다] 러닝 깃허브 액션 (0) | 2024.06.23 |
| [나는 리뷰어다] 인사이드 머신러닝 인터뷰 (1) | 2024.04.28 |
| [나는 리뷰어다] 실무로 통하는 인과추론 with 파이썬 (0) | 2024.03.24 |
| [나는 리뷰어다] 밑바닥부터 시작하는 딥러닝 4 (0) | 2024.02.25 |




댓글