4.1 word2vec 개선 1
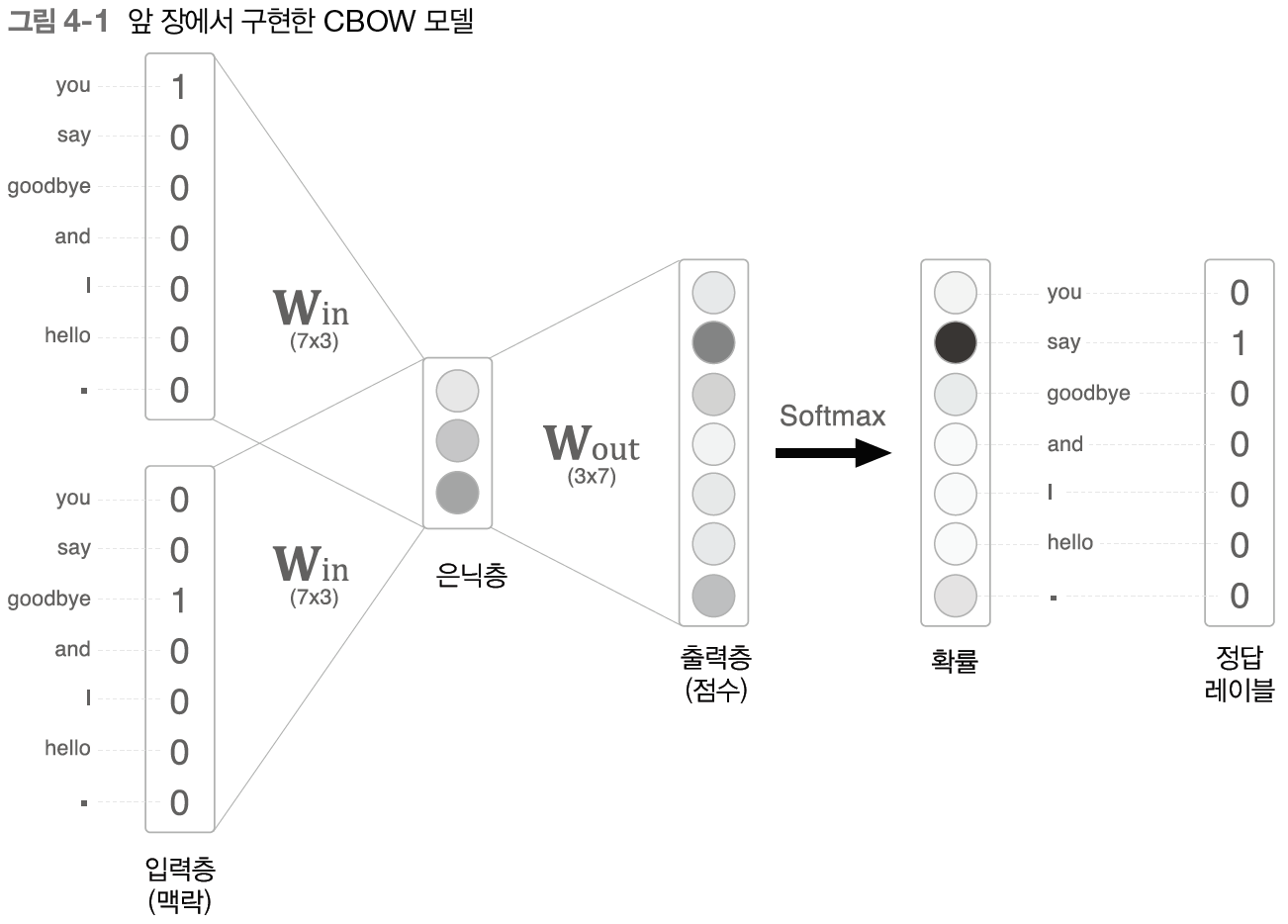
어휘가 100만개가 된다면?
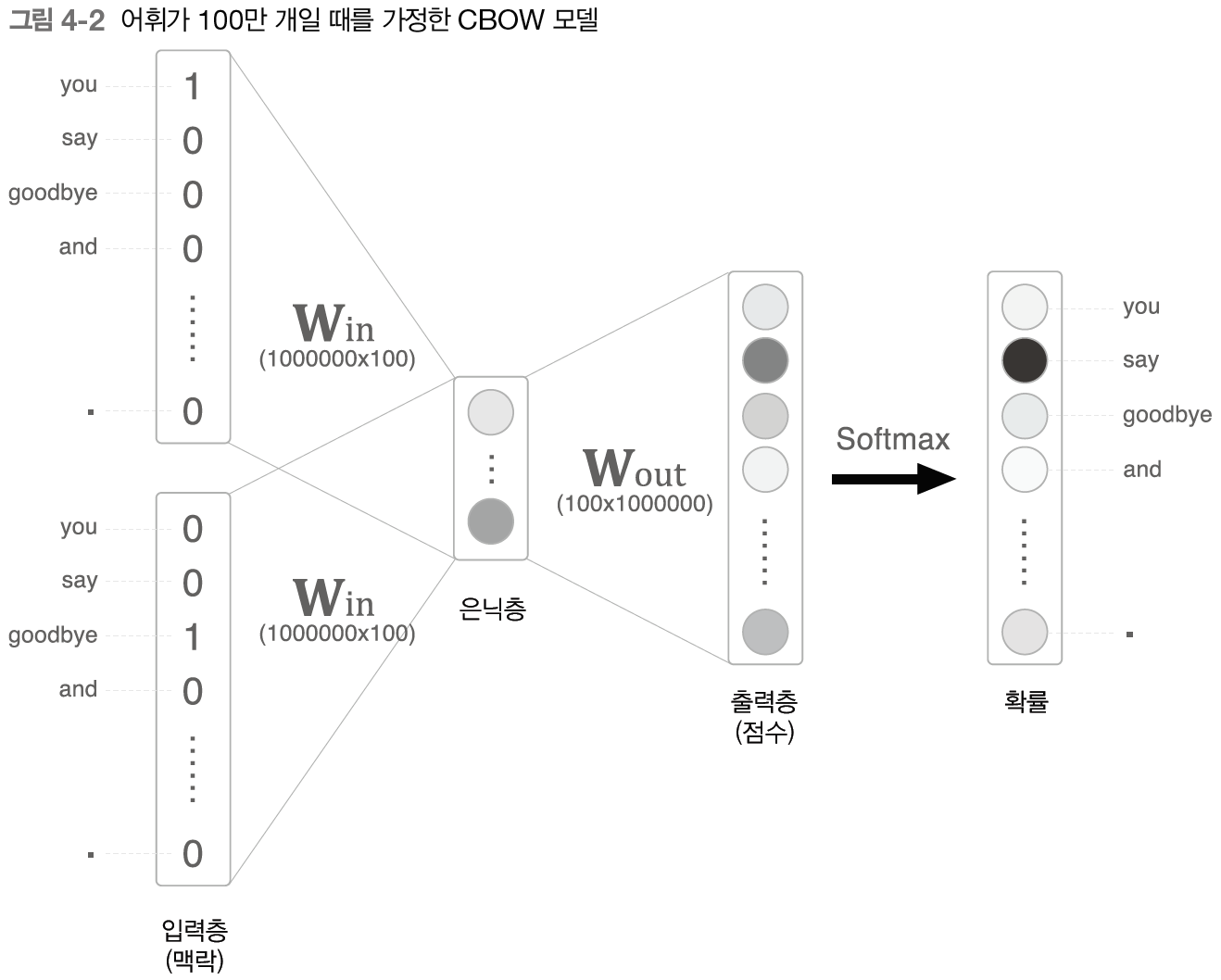
게산 병목이 생긴다
- 입력층 원핫 표현과 가중치 행렬 Win 곱 -> 4.1
- 은닉층과 가중치 행렬 Wout 곱, softmax 계산 -> 4.2
4.1.1 Embedding 계층

위 작업에서 결국 하는 것은 특정 행을 추출하는 것. -> 단어에 해당하는 행을 추출하기만 하면 된다.
이 계층을 임베딩 계층이라고 부른다.
4.1.2 Embedding 계층 구현
행렬에서 특정 행을 추출하기: W[2] , W[5]


class Embedding:
def __init__(self, W):
self.params = [W]
self.grads = [np.zeros_like(W)]
self.idx = None
def forward(self, idx):
W, = self.params
self.idx = idx
out = W[idx]
return out
def backward(self, dout):
dW, = self.grads
dW[...] = 0
np.add.at(dW, self.idx, dout)
return None이제 MatMul 계층을 Embedding 계층으로 전환하면 메모리 사용량을 확 줄일 수 있다.
4.2 word2vec 개선 2
4.2.1 은닉층 이후 계산의 문제점

입력층, 출력층 뉴런 각 100만개씩 존재함 -> 임베딩 계층 도입하여 입력층 계산 낭비 줄였다.
은닉층 이후에서는?
- 은닉층 뉴런과 Wout곱
- 소프트맥스 계층 계산
위 두 곳에서 오래걸린다.
4.2.2 다중 분류에서 이진 분류로


4.2.3 시그모이드 함수와 교차 엔트로피 오차
이진 분류를 푸는 방법: 시그모이드 함수를 적용해 확률로 변환하고 손실을 교차 엔트로피 오차로 구한다. (가장 흔한 조합)
<시그모이드 복습>


<교차 엔트로피 오차 복습>
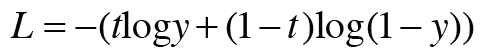
<시그모이드,크로스엔트로피에러 계산그래프>

4.2.4 다중 분류에서 이진 분류로 (구현)

위 신경망을 이진 분류 신경망으로 변환해보자

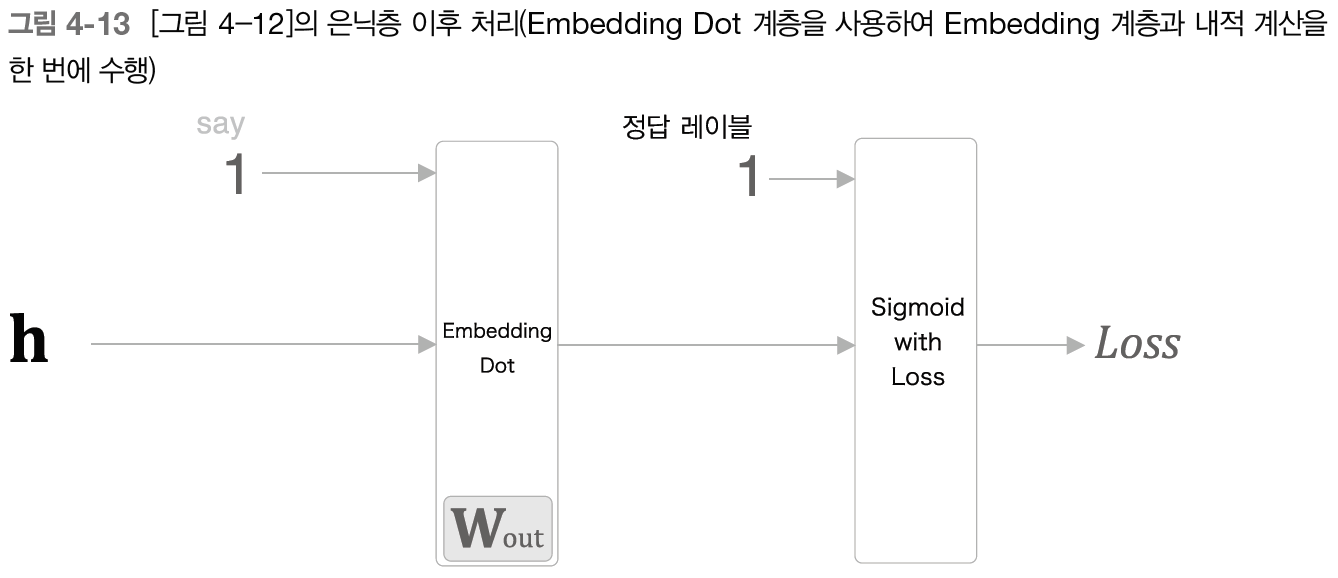
class EmbeddingDot:
def __init__(self, W):
self.embed = Embedding(W)
self.params = self.embed.params
self.grads = self.embed.grads
self.cache = None
def forward(self, h, idx):
target_W = self.embed.forward(idx)
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W)
return out
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dh4.2.5 네거티브 샘플링
지금까지 배운 것으로 다중분류를 이진 분류로 변환했다.
이제 부정적인 예를 입력하여 성능을 높여보자.
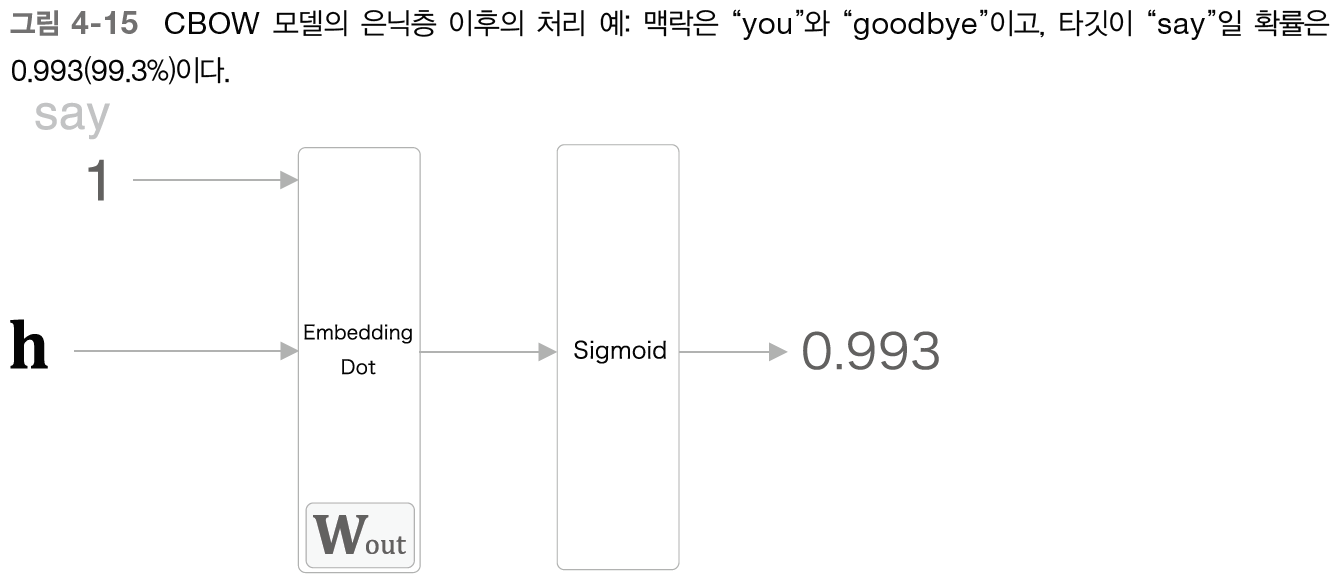
현재 신경망에서는 'say'만 학습하고 그 이외의 단어에 대해서는 어떠한 지식도 없다. -> 더 단단한 성능(로버스트)을 위해서 긍정적 답변에 대해서는 시그모이드 출력을 1로, 부정정 답변(오답)에 대해서는 시그모이드 계층 출력을 0으로 만드는 것이 필요

부정적 샘플을 모두 다 학습시킬 수 없으므로 네거티브 샘플링 기법이 필요하다.

4.2.6 네거티브 샘플링의 샘플링 기법
부정적 예를 어떻게 샘플링할까? -> 말뭉치에서 자주 등장하는 단어를 많이 추출하고, 드물게 등장하는 단어를 적게 추출
p = [0.5, 0.1, 0.05, 0.2, 0.05, 0.1]
np.random.choice(words, p=p)
그런데 word2vec의 네거티브 샘플링에서는 확률분포에 0.75를 제곱한다.
왜? 확률이 낮은 단어를 아예 버리지는 않게하기 위해서.

p = [0.7, 0.29, 0.01]
new_p = np.power(p, 0.75)
new_p /= np,sum(p, 0.75)new_p => [0.64... , 0.331.., 0.0265...]
4.2.7 네거티브 샘플링 구현
# coding: utf-8
import sys
sys.path.append('..')
from common.np import * # import numpy as np
from common.layers import Embedding, SigmoidWithLoss
import collections
class EmbeddingDot:
def __init__(self, W):
self.embed = Embedding(W)
self.params = self.embed.params
self.grads = self.embed.grads
self.cache = None
def forward(self, h, idx):
target_W = self.embed.forward(idx)
out = np.sum(target_W * h, axis=1)
self.cache = (h, target_W)
return out
def backward(self, dout):
h, target_W = self.cache
dout = dout.reshape(dout.shape[0], 1)
dtarget_W = dout * h
self.embed.backward(dtarget_W)
dh = dout * target_W
return dh
class UnigramSampler:
def __init__(self, corpus, power, sample_size):
self.sample_size = sample_size
self.vocab_size = None
self.word_p = None
counts = collections.Counter()
for word_id in corpus:
counts[word_id] += 1
vocab_size = len(counts)
self.vocab_size = vocab_size
self.word_p = np.zeros(vocab_size)
for i in range(vocab_size):
self.word_p[i] = counts[i]
self.word_p = np.power(self.word_p, power)
self.word_p /= np.sum(self.word_p)
def get_negative_sample(self, target):
batch_size = target.shape[0]
if not GPU:
negative_sample = np.zeros((batch_size, self.sample_size), dtype=np.int32)
for i in range(batch_size):
p = self.word_p.copy()
target_idx = target[i]
p[target_idx] = 0
p /= p.sum()
negative_sample[i, :] = np.random.choice(self.vocab_size, size=self.sample_size, replace=False, p=p)
else:
# GPU(cupy)로 계산할 때는 속도를 우선한다.
# 부정적 예에 타깃이 포함될 수 있다.
negative_sample = np.random.choice(self.vocab_size, size=(batch_size, self.sample_size),
replace=True, p=self.word_p)
return negative_sample
class NegativeSamplingLoss:
def __init__(self, W, corpus, power=0.75, sample_size=5):
self.sample_size = sample_size
self.sampler = UnigramSampler(corpus, power, sample_size)
self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)]
self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)]
self.params, self.grads = [], []
for layer in self.embed_dot_layers:
self.params += layer.params
self.grads += layer.grads
def forward(self, h, target):
batch_size = target.shape[0]
negative_sample = self.sampler.get_negative_sample(target)
# 긍정적 예 순전파
score = self.embed_dot_layers[0].forward(h, target)
correct_label = np.ones(batch_size, dtype=np.int32)
loss = self.loss_layers[0].forward(score, correct_label)
# 부정적 예 순전파
negative_label = np.zeros(batch_size, dtype=np.int32)
for i in range(self.sample_size):
negative_target = negative_sample[:, i]
score = self.embed_dot_layers[1 + i].forward(h, negative_target)
loss += self.loss_layers[1 + i].forward(score, negative_label)
return loss
def backward(self, dout=1):
dh = 0
for l0, l1 in zip(self.loss_layers, self.embed_dot_layers):
dscore = l0.backward(dout)
dh += l1.backward(dscore)
return dh4.3 개선판 word2vec 학습
4.3.1 CBOW 모델 구현
SimpleCBOW 클래스 개선해보자
- 임베딩 계층 적용
- 네거티브 샘플링 로스 계층 적용
- 맥락의 윈도우 크기 조절가능하도록 확장
# coding: utf-8
import sys
sys.path.append('..')
from common.np import * # import numpy as np
from common.layers import Embedding
from ch04.negative_sampling_layer import NegativeSamplingLoss
class CBOW:
def __init__(self, vocab_size, hidden_size, window_size, corpus):
V, H = vocab_size, hidden_size
# 가중치 초기화
W_in = 0.01 * np.random.randn(V, H).astype('f')
W_out = 0.01 * np.random.randn(V, H).astype('f')
# 계층 생성
self.in_layers = []
for i in range(2 * window_size):
layer = Embedding(W_in) # Embedding 계층 사용
self.in_layers.append(layer)
self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5)
# 모든 가중치와 기울기를 배열에 모은다.
layers = self.in_layers + [self.ns_loss]
self.params, self.grads = [], []
for layer in layers:
self.params += layer.params
self.grads += layer.grads
# 인스턴스 변수에 단어의 분산 표현을 저장한다.
self.word_vecs = W_in
def forward(self, contexts, target):
h = 0
for i, layer in enumerate(self.in_layers):
h += layer.forward(contexts[:, i])
h *= 1 / len(self.in_layers)
loss = self.ns_loss.forward(h, target)
return loss
def backward(self, dout=1):
dout = self.ns_loss.backward(dout)
dout *= 1 / len(self.in_layers)
for layer in self.in_layers:
layer.backward(dout)
return None

4.3.2 CBOW 모델 학습 코드
# coding: utf-8
import sys
sys.path.append('..')
import numpy as np
from common import config
# GPU에서 실행하려면 아래 주석을 해제하세요(CuPy 필요).
# ===============================================
# config.GPU = True
# ===============================================
import pickle
from common.trainer import Trainer
from common.optimizer import Adam
from cbow import CBOW
from skip_gram import SkipGram
from common.util import create_contexts_target, to_cpu, to_gpu
from dataset import ptb
# 하이퍼파라미터 설정
window_size = 5
hidden_size = 100
batch_size = 100
max_epoch = 10
# 데이터 읽기
corpus, word_to_id, id_to_word = ptb.load_data('train')
vocab_size = len(word_to_id)
contexts, target = create_contexts_target(corpus, window_size)
if config.GPU:
contexts, target = to_gpu(contexts), to_gpu(target)
# 모델 등 생성
model = CBOW(vocab_size, hidden_size, window_size, corpus)
# model = SkipGram(vocab_size, hidden_size, window_size, corpus)
optimizer = Adam()
trainer = Trainer(model, optimizer)
# 학습 시작
trainer.fit(contexts, target, max_epoch, batch_size)
trainer.plot()
# 나중에 사용할 수 있도록 필요한 데이터 저장
word_vecs = model.word_vecs
if config.GPU:
word_vecs = to_cpu(word_vecs)
params = {}
params['word_vecs'] = word_vecs.astype(np.float16)
params['word_to_id'] = word_to_id
params['id_to_word'] = id_to_word
pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl'
with open(pkl_file, 'wb') as f:
pickle.dump(params, f, -1)GPU가 있다면 꼭 주석을 해제하고 GPU로 실행하세요!
CPU로 돌리면 너무 오래걸리니, https://github.com/WegraLee/deep-learning-from-scratch-2/blob/master/ch04/cbow_params.pkl
deep-learning-from-scratch-2/ch04/cbow_params.pkl at master · WegraLee/deep-learning-from-scratch-2
『밑바닥부터 시작하는 딥러닝 ❷』(한빛미디어, 2019). Contribute to WegraLee/deep-learning-from-scratch-2 development by creating an account on GitHub.
github.com
여기서 받아가세요!
4.3.3 CBOW 모델 평가
# coding: utf-8
import sys
sys.path.append('..')
from common.util import most_similar, analogy
import pickle
pkl_file = 'cbow_params.pkl'
# pkl_file = 'skipgram_params.pkl'
with open(pkl_file, 'rb') as f:
params = pickle.load(f)
word_vecs = params['word_vecs']
word_to_id = params['word_to_id']
id_to_word = params['id_to_word']
# 가장 비슷한(most similar) 단어 뽑기
querys = ['you', 'year', 'car', 'toyota']
for query in querys:
most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
# 유추(analogy) 작업
print('-'*50)
analogy('king', 'man', 'queen', word_to_id, id_to_word, word_vecs)
analogy('take', 'took', 'go', word_to_id, id_to_word, word_vecs)
analogy('car', 'cars', 'child', word_to_id, id_to_word, word_vecs)
analogy('good', 'better', 'bad', word_to_id, id_to_word, word_vecs)결과를 출력해보면 꽤 괜찮은 유사도 높은 단어들이 나온다.

4.4 word2vec 남은 주제
4.4.1 word2vec을 사용한 애플리케이션의 예
전이 학습(transfer learning): 한 분야에서 배운 지식을 다른 분야에도 적용하는 기법
이전에 만들어 둔 것을 그대로 쓴다!

4.4.2 단어 벡터 평가 방법
word2vec 분산 표현 평가 방법
- 일단 단어의 분산 표현을 실제 애플리케이션과 분리해서 평가한다.
- 자주 사용되는 평가 척도: '유사성', '유추 문제'
<유사성>
cat - animal => 8
cat - car => 2
<유추 문제>
단어의 의미나 문법적인 문제를 제대로 이해하고 있는지 유추 문제로 푼다.
king : queen = man: ?

의미: king:queen = actor:actess
구문: bad:worst = good:best
- 모델에 따라 정확도가 다르다(말뭉치에 따라 적합한 모델 선택)
- 일반적으로 말뭉치가 클 수록 결과 가 좋음
- 단어 벡터 차원 수는 적당하게. (너무 커도 정확도 내려감)
4.5 정리
CBOW 모델 개선 (word2vec 고속화)
- 임베딩 계층 구현
- 네거티브 샘플링 도입
이번 장에서 배운 내용
- Embedding 계층은 단어의 분산 표현을 담고 있으며, 순전파 시 지정한 단어 ID의 벡터를 추출한다
- word2vec은 어휘 수의 증가에 비례하여 계산량도 증가하므로, 근사치로 계산하는 빠른 기법을 사용하면 좋다.
- 네거티브 샘플링은 부정적 예를 몇 개 샘플링하는 기법으로, 이를 이용하면 다중 분류를 이진 분류처럼 취급할 수 있다.
- word2vec으로 얻은 단어의 분산 표현에는 단어의 의미가 녹아들어 있으며, 비슷한 맥락에서 사용되는 단어는 단어 벡터 공간에서 가까이 위치한다
- word2vec의 단어의 분산 표현을 이용하면 유추 문제를 벡터의 덧셈과 뺄셈으로 풀 수 있게 된다.
- word2vec은 전이 학습 측면에서 특히 중요하며, 그 단어의 분산 표현은 단어의 자연어 처리 작업에 이용할 수 있다.
'ML & DL > 책 & 강의' 카테고리의 다른 글
| [밑시딥2] CHAPTER 6 게이트가 추가된 RNN (0) | 2024.07.29 |
|---|---|
| [나는 리뷰어다] 실무로 통하는 타입스크립트 (1) | 2024.07.28 |
| [나는 리뷰어다] 러닝 깃허브 액션 (0) | 2024.06.23 |
| Mastering Customer Segmentation with LLM (1) | 2024.06.16 |
| [나는 리뷰어다] 인사이드 머신러닝 인터뷰 (1) | 2024.04.28 |




댓글