Abstract
프록시말 정책 최적화(Proximal Policy Optimization, PPO)는 강화학습을 위한 새로운 정책 경사 방법입니다. 이 방법은 환경과의 상호작용을 통해 데이터를 샘플링하고, 확률적 경사 상승법을 사용하여 "대리" 목적 함수를 최적화하는 과정을 번갈아 수행합니다.
기존의 정책 경사 방법은 데이터 샘플 하나당 한 번의 경사 업데이트를 수행하는 반면, PPO는 미니배치 업데이트를 여러 번 수행할 수 있는 새로운 목적 함수를 제안합니다. 이는 트러스트 영역 정책 최적화(Trust Region Policy Optimization, TRPO)의 장점을 가지면서도, 구현이 훨씬 간단하고 더 일반적이며, 실험적으로 더 나은 샘플 복잡도를 보입니다.
PPO는 시뮬레이션 로봇 이동과 아타리 게임 플레이 등 다양한 벤치마크 작업에서 테스트되었으며, 다른 온라인 정책 경사 방법보다 우수한 성능을 보였습니다. 전반적으로 PPO는 샘플 복잡도, 단순성, 수행 시간 사이에서 좋은 균형을 이루는 것으로 나타났습니다.
요약하면, PPO는 강화학습에서 정책 경사 방법의 새로운 대안으로, 간단하고 효율적인 알고리즘으로 기존 방법의 단점을 개선하였습니다.
1 Introduction
최근 몇 년 동안, 신경망 함수 근사기를 사용한 강화학습을 위해 여러 가지 접근 방식이 제안되었습니다. 대표적인 방법으로는 딥 Q-러닝, "바닐라" 정책 경사법, 트러스트 영역/자연 정책 경사법 등이 있습니다. 하지만 이러한 방법들은 확장성, 데이터 효율성, 강건성 등의 측면에서 개선의 여지가 있습니다.
Q-러닝은 많은 간단한 문제에서 실패하고 이해하기 어려우며, 바닐라 정책 경사법은 데이터 효율성과 강건성이 좋지 않습니다. 트러스트 영역 정책 최적화(TRPO)는 상대적으로 복잡하고, 노이즈나 파라미터 공유와 같은 아키텍처와 호환되지 않습니다.
이 논문은 TRPO의 데이터 효율성과 안정적인 성능을 달성하면서도, 1차 최적화만을 사용하는 알고리즘을 소개함으로써 현재 상황을 개선하고자 합니다. 저자들은 클리핑된 확률 비율을 사용한 새로운 목적 함수를 제안하며, 이는 정책 성능의 비관적 추정(즉, 하한)을 형성합니다.
정책을 최적화하기 위해, 저자들은 정책에서 데이터를 샘플링하고 샘플링된 데이터에 대해 여러 번의 최적화를 수행하는 과정을 번갈아 수행합니다. 실험 결과, 클리핑된 확률 비율을 사용한 버전의 성능이 가장 좋았습니다.
PPO는 연속 제어 작업에서 다른 알고리즘보다 우수한 성능을 보였고, 아타리 게임에서는 A2C보다 훨씬 적은 샘플 복잡도로 비슷한 성능을 달성했습니다.
요약하면, PPO는 기존의 강화학습 알고리즘들이 가진 한계를 개선한 새로운 방법으로, 데이터 효율성과 안정성을 유지하면서도 간단한 1차 최적화만을 사용하여 우수한 성능을 달성했습니다.
2 Background: Policy Optimization
2.1 Policy Gradient Methods
정책 경사 방법은 정책 경사를 계산하고 이를 확률적 경사 상승 알고리즘에 대입하여 작동합니다. 가장 일반적으로 사용되는 경사 추정기는 다음과 같은 형태를 가집니다:
ĝ = Êt[∇θ log πθ(at | st)Ât]
여기서 πθ는 확률적 정책이고, Ât는 t 시점에서의 이점 함수 추정치입니다. Êt[...]는 유한한 샘플 배치에 대한 경험적 평균을 나타내며, 샘플링과 최적화를 번갈아 수행하는 알고리즘에서 사용됩니다.
자동 미분 소프트웨어를 사용하는 구현은 정책 경사 추정기로 목적 함수의 경사를 구성하여 작동하며, 추정기 ĝ는 다음과 같이 목적 함수를 미분하여 얻습니다:
LPG(θ) = Êt [log πθ(at | st)Ât]
이 손실 LPG에 대해 여러 단계의 최적화를 수행하는 것은 매력적으로 보이지만, 그렇게 하는 것은 잘 정당화되지 않으며, 경험적으로 파괴적으로 큰 정책 업데이트로 이어질 수 있습니다 (6.1절의 결과는 표시되지 않았지만 "클리핑이나 패널티가 없는" 설정과 유사하거나 더 나빴습니다).
요약하면, 정책 경사 방법은 경사 추정기를 계산하고 이를 확률적 경사 상승법에 사용하여 정책을 최적화합니다. 하지만 단순히 이 추정기로 목적 함수를 구성하여 여러 단계의 최적화를 수행하는 것은 바람직하지 않은 결과를 초래할 수 있습니다.
2.2 Trust Region Methods
TRPO(Trust Region Policy Optimization)에서는 정책 업데이트의 크기에 제약을 두고 "대리" 목적 함수를 최대화합니다. 구체적으로,
maximize_θ Êt [πθ(at | st) / πθ_old(at | st) * Ât]
subject to Êt[KL[πθ_old(·|st), πθ(·|st)]] ≤ δ.
여기서 θ_old는 업데이트 이전의 정책 파라미터 벡터입니다. 이 문제는 목적 함수를 선형 근사하고 제약 조건을 이차 근사한 후, 켤레 경사 알고리즘을 사용하여 효율적으로 해결할 수 있습니다.
TRPO를 정당화하는 이론은 실제로 제약 조건 대신 패널티를 사용할 것을 제안합니다. 즉, 무제약 최적화 문제를 푸는 것입니다:
maximize_θ Êt [πθ(at | st) / πθ_old(at | st) * Ât - β KL[πθ_old(·|st), πθ(·|st)]]
여기서 β는 어떤 계수입니다. 이는 특정 대리 목적 함수(평균에 대한 최대 KL을 계산하는)가 정책 π의 성능에 대한 하한(즉, 비관적 한계)을 형성한다는 사실에서 나옵니다. TRPO는 패널티보다는 경성 제약 조건을 사용하는데, β를 잘 선택하면 서로 다른 문제에서도 좋은 성능을 낼 수 있기 때문입니다. 심지어 학습 과정에서 특성이 변하는 단일 문제 내에서도 마찬가지입니다.
따라서 TRPO의 단조 개선을 에뮬레이트하는 일차 알고리즘을 달성하기 위해서는 고정된 패널티 계수 β를 단순히 선택하는 것만으로는 충분하지 않으며, 페널티를 가한 목적 함수인 식 (5)에 대해 SGD를 사용할 때 추가적인 수정이 필요합니다.
3 Clipped Surrogate Objective
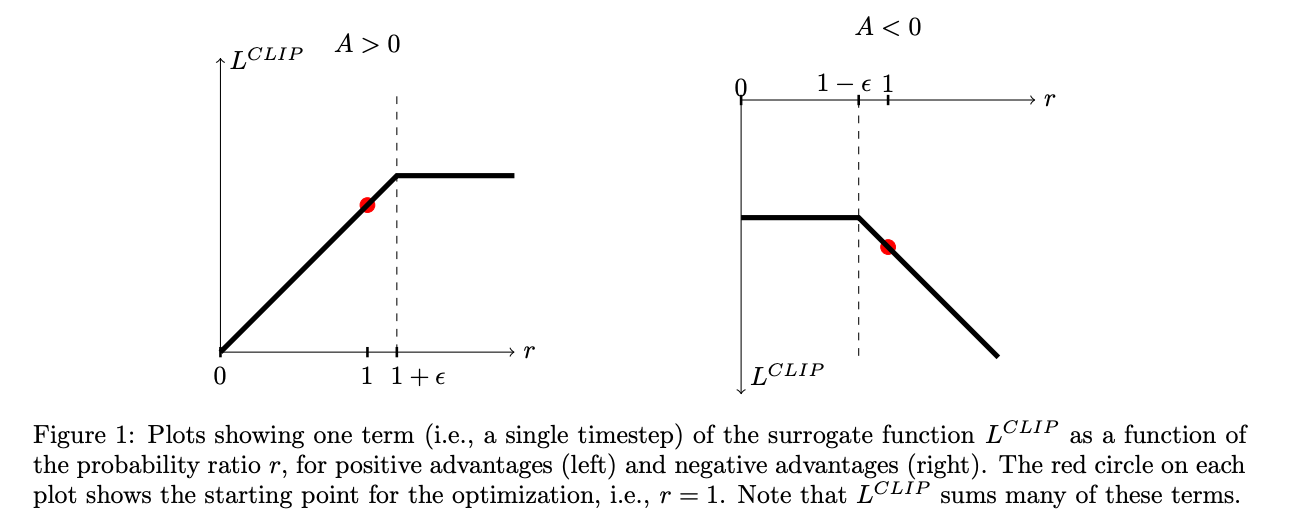
이미지 1에 따르면, TRPO는 "대리" 목적 함수를 최대화하며, 이는 다음과 같이 정의됩니다:
L^CPI(θ) = Êt [πθ(at|st) / πθ_old(at|st) * Ât] = Êt [rt(θ)Ât].
여기서 rt(θ)는 확률 비율로, rt(θ) = πθ(at|st) / πθ_old(at|st)이고, r(θ_old) = 1입니다.
우리가 제안하는 주요 목적 함수는 다음과 같습니다.
L^CLIP(θ) = Êt [min(rt(θ)Ât, clip(rt(θ), 1 - ϵ, 1 + ϵ)Ât)]
여기서 ϵ은 하이퍼파라미터이며, 예를 들어 ϵ = 0.2입니다. 이 목적 함수의 동기는 다음과 같습니다. min 안의 첫 번째 항은 L^CPI입니다. 두 번째 항 clip(rt(θ), 1 - ϵ, 1 + ϵ)Ât는 확률 비율을 클리핑하여 대리 목적 함수를 수정합니다. 이는 rt가 구간 [1 - ϵ, 1 + ϵ] 바깥으로 벗어나는 것을 막습니다.
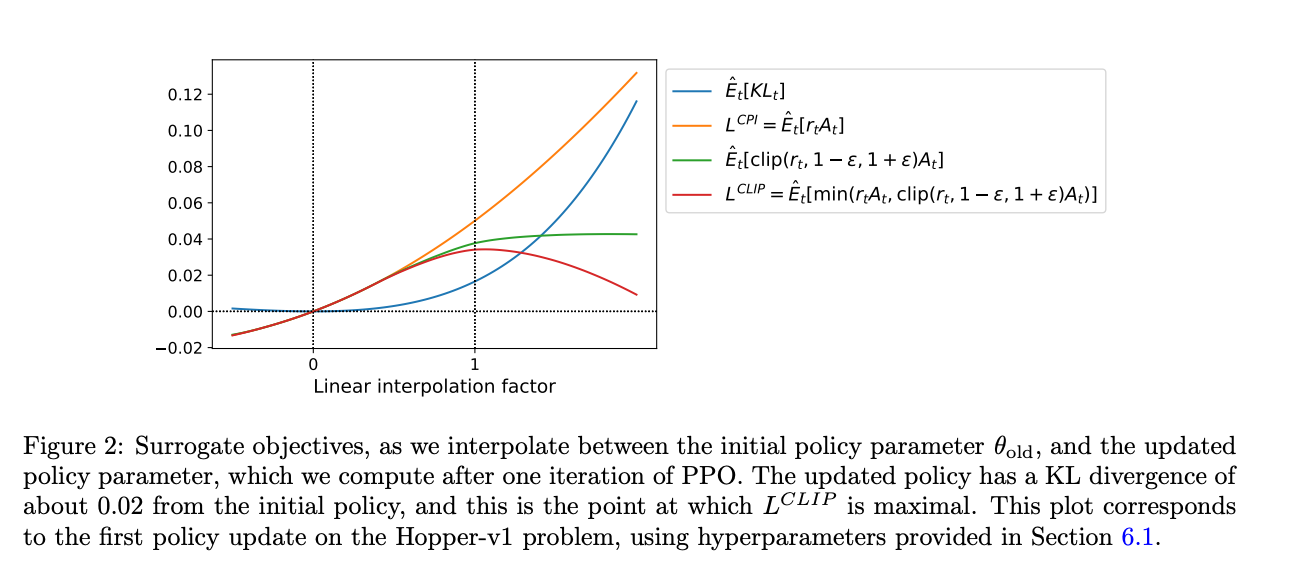
이미지 2는 초기 정책 파라미터 θ_old와 PPO 1회 반복 후 계산된 정책 파라미터 사이를 보간하면서 여러 대리 목적 함수가 어떻게 변화하는지 보여줍니다. 업데이트된 정책은 초기 정책과 약 0.02의 KL 발산을 가지며, 이 지점에서 L^CLIP가 최대가 됩니다. 이는 Hopper-v1 문제에 대한 첫 번째 정책 업데이트에 해당하며, 6.1절에서 제공된 하이퍼파라미터를 사용했습니다. 우리는 L^CLIP가 L^CPI의 하한이며, 너무 큰 정책 업데이트에 대해서는 패널티를 부과한다는 것을 알 수 있습니다.
4 Adaptive KL Penalty Coefficient
또 다른 접근 방식은 클리핑된 대리 목적 함수와 함께 사용하거나 대안으로 사용할 수 있는 KL 발산에 대한 패널티를 사용하는 것입니다. 이 방식에서는 KL 발산 패널티 계수를 적응적으로 조정하여 각 정책 업데이트에서 어떤 목표 KL 발산 d_targ을 달성하도록 합니다. 실험에서 KL 패널티가 클리핑된 대리 목적 함수보다 성능이 좋지 않았지만, 중요한 기준선이므로 여기에 포함시켰습니다.
이 알고리즘의 가장 단순한 실현에서는 각 정책 업데이트에서 다음 단계를 수행합니다.
- 여러 에포크에 걸쳐 미니배치 SGD를 사용하여 KL-패널티를 가한 목적 함수 L^KLPEN(θ)를 최적화합니다.
- d = Êt[KL[πθ_old(·|st), πθ(·|st)]]를 계산합니다.
- 만약 d < d_targ/1.5이면, β ← β/2
- 만약 d > d_targ × 1.5이면, β ← β × 2
업데이트된 β는 다음 정책 업데이트에 사용됩니다. 이 방식에서는 KL 발산이 d_targ와 상당히 다른 정책 업데이트가 가끔 발생할 수 있지만, 이런 경우는 드물고 β가 빠르게 조정됩니다. 위의 1.5와 2라는 파라미터는 경험적으로 선택되었지만, 알고리즘은 이에 크게 민감하지 않습니다. β의 초기값은 또 다른 하이퍼파라미터이지만, 실제로는 중요하지 않습니다. 알고리즘이 β를 빠르게 조정하기 때문입니다.
5 Algorithm
이 알고리즘은 강화학습에서 사용되는 일종의 알고리즘으로, PPO(Proximal Policy Optimization)라고 부릅니다. PPO는 Actor-Critic 방식을 기반으로 하며, 안정적이고 효율적인 학습을 위해 설계되었습니다. 간단히 설명드리면 다음과 같습니다:
1. 목표: PPO는 정책(policy)을 개선하여 에이전트가 환경에서 더 높은 보상을 받도록 합니다.
2. Actor-Critic 구조: 이 구조에서는 'Actor'가 어떤 상황에서 어떤 행동을 할지 결정하고, 'Critic'은 그 행동의 가치를 평가합니다.
3. 손실 함수: 알고리즘은 정책의 손실 함수를 최소화하는 방향으로 파라미터를 업데이트합니다. 손실 함수는 주로 정책의 예상 가치와 실제 가치 사이의 차이를 기반으로 계산됩니다.
4. 엔트로피 보너스: 탐험을 장려하기 위해 엔트로피 보너스를 사용하여, 에이전트가 새로운 행동을 시도하도록 독려합니다.
5. 알고리즘 순서:
- 각 반복마다 N개의 에이전트가 환경에서 T 타임스텝 동안 정책을 실행합니다.
- 각 에이전트는 실행 동안의 데이터를 수집하고, 이를 바탕으로 '이득(advantage)'을 계산합니다.
- 수집된 데이터와 계산된 이득을 사용하여 정책을 최적화합니다. 이 과정은 K 에포크 동안 반복됩니다.
이러한 과정을 통해 PPO 알고리즘은 강화학습에서 정책을 점진적으로 개선하며, 복잡한 환경에서도 효과적으로 학습할 수 있도록 돕습니다.
6 Experiments
6.1 Comparison of Surrogate Objectives
서로 다른 하이퍼파라미터 설정에서 여러 surrogate 목적 함수를 비교합니다.
비교되는 세 가지 surrogate 목적 함수는 다음과 같습니다.
1. No clipping or penalty: L_t(θ) = r_t(θ) A_t
2. Clipping: L_t(θ) = min(r_t(θ)A_t, clip(r_t(θ)), 1 - ε, 1 + ε) A_t
3. KL penalty (fixed or adaptive): L_t(θ) = r_t(θ) A_t - β KL[π_θ_old, π_θ]
KL penalty의 경우 고정된 β 값이나 adaptive 계수를 사용할 수 있습니다.
알고리즘 성능을 비교하기 위해 7개의 시뮬레이션 된 로보틱 작업을 사용했으며, MuJoCo 물리 엔진에서 구현되었습니다.
각 알고리즘은 7개의 환경에서 모두 실행되었고, 각 실행마다 3개의 random seed를 사용했습니다.
알고리즘의 성능은 마지막 100 에피소드의 평균 총 보상을 계산하여 점수화했습니다. 무작위 정책에서 0점, 최고 결과에서 1점으로 정규화되었습니다.
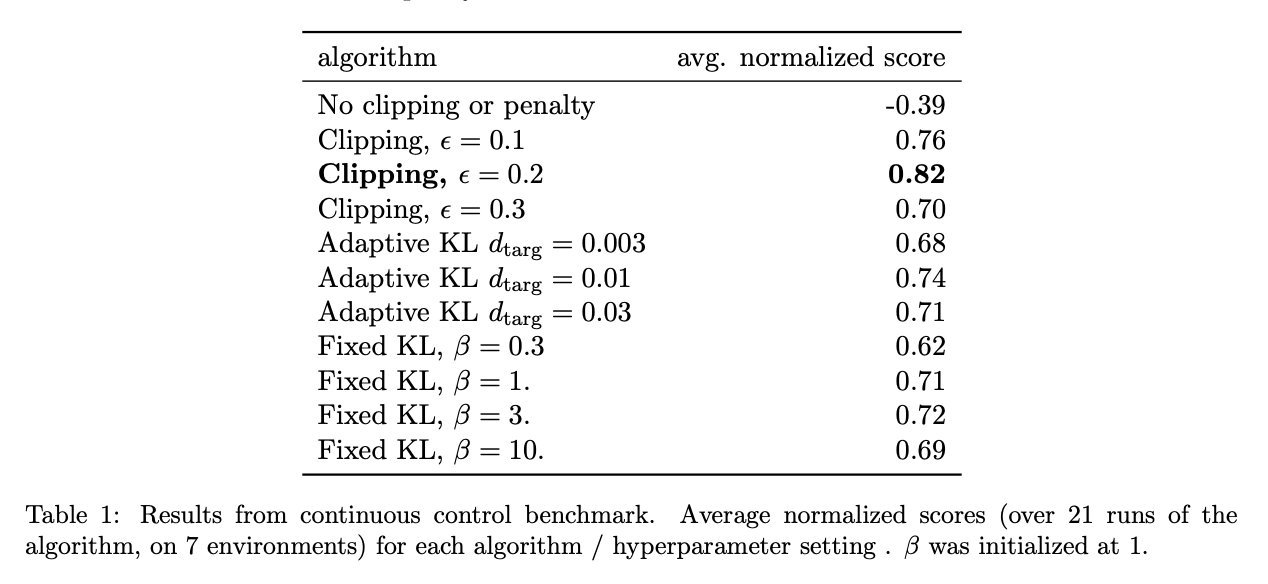
표 1은 다양한 하이퍼파라미터 설정에서 각 알고리즘의 정규화된 평균 점수를 보여줍니다. Clipping이나 penalty가 없는 설정이 가장 낮은 점수를 받았고, Fixed KL과 적응형 KL 설정은 더 높은 점수를 얻었습니다.
6.2 Comparison to Other Algorithms in the Continuous Domain
PPO와 다른 연속적인 문제에 효과적인 알고리즘들을 비교합니다. 비교 대상 알고리즘은 trust region policy optimization (Sch+15b), cross-entropy method (CEM) (SL06), vanilla policy gradient with adaptive stepsize³ 등입니다.
이들 알고리즘의 성능은 여러 MuJoCo 환경에서 100만 타임스텝 동안 학습시켜 비교했습니다. A2C (동기적 행위자-비평가)는 A3C의 동기화 버전으로, 이전 섹션에서 사용한 하이퍼파라미터와 동일한 설정을 사용했습니다.
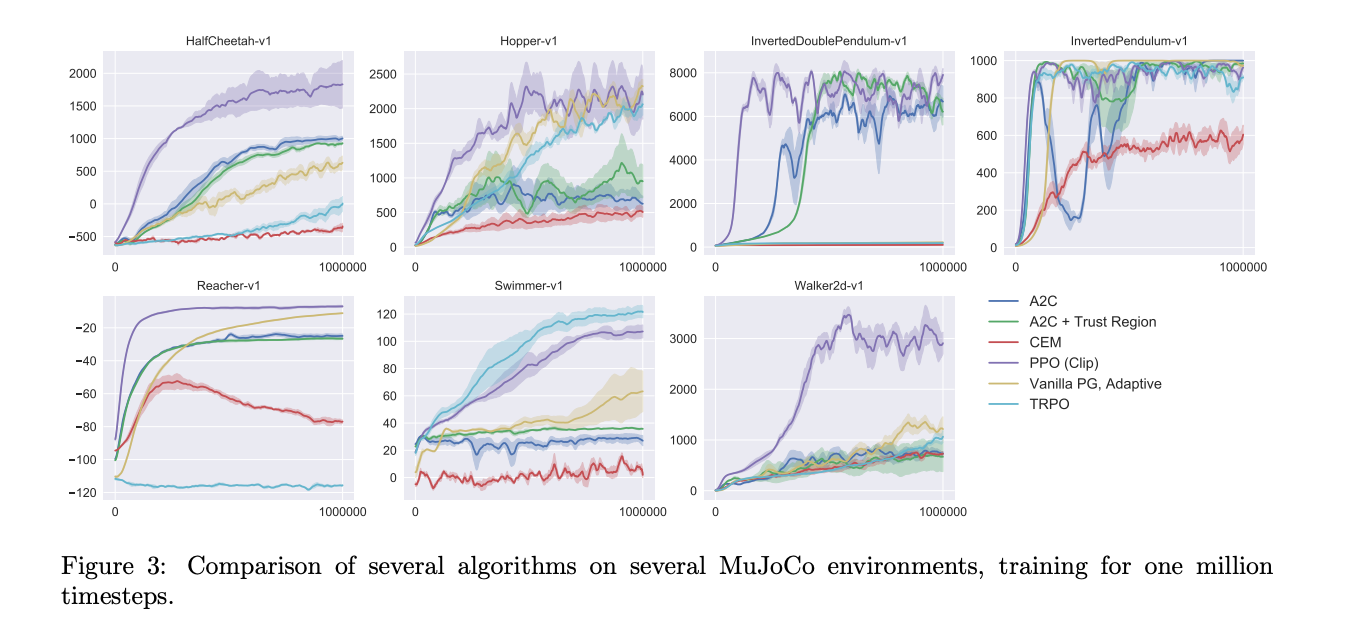
Figure 3은 각 알고리즘의 학습 곡선을 보여줍니다. PPO는 대부분의 환경에서 이전 방법들보다 거의 항상 우수한 성능을 보였습니다. 특히 연속적인 제어 문제에서 높은 성능을 달성했습니다.
요약하면 이 비교 실험은 PPO가 연속적인 제어 태스크에서 기존의 다른 알고리즘들에 비해 우수한 성능을 보임을 시사합니다.
6.3 Showcase in the Continuous Domain: Humanoid Running and Steering
PPO 알고리즘의 고차원 연속 제어 문제에 대한 성능을 보여주기 위해, 3D 휴머노이드 로봇이 달리기, 운전하기, 일어서기 등의 작업을 수행하는 것을 테스트한 결과를 제시합니다.
테스트한 세 가지 작업은 다음과 같습니다.
1. RoboschoolHumanoid: forward locomotion만 수행
2. RoboschoolHumanoidFlagrun: 로봇이 깃발을 향해 달리는 작업
3. RoboschoolHumanoidFlagrunHarder: 로봇이 큐브에 의해 밀리면서 일어나 달려야 하는 작업
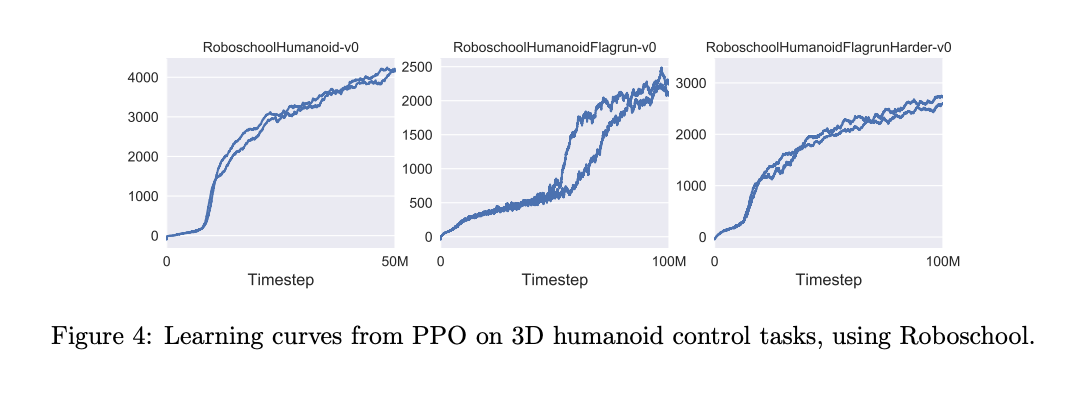
Figure 4는 Roboschool을 사용하여 이 세 가지 작업에 대한 PPO의 학습 곡선을 보여줍니다. 하이퍼파라미터는 Table 4에 제공되어 있습니다.

Figure 5는 RoboschoolHumanoidFlagrun에서 학습된 정책으로부터의 스틸 프레임을 보여줍니다. 처음 6 프레임에서는 로봇이 달리는 것을 보여주고, 이후 6 프레임에서는 로봇이 새로운 목표를 향해 방향을 바꾸고 달리는 모습을 볼 수 있습니다.
이 실험은 PPO가 복잡한 3D 휴머노이드 제어 작업들을 성공적으로 학습할 수 있음을 보여줍니다.
6.4 Comparison to Other Algorithms on the Atari Domain
PPO 알고리즘을 Arcade Learning Environment (ALE) 벤치마크에서 테스트하고, 잘 튜닝된 A2C와 ACER 구현체와 비교한 결과를 보여줍니다. 세 알고리즘 모두 동일한 정책 네트워크 아키텍처를 사용했으며, PPO의 하이퍼파라미터는 Table 5에 제공되어 있습니다.
49개 게임에 대한 결과와 학습 곡선은 Appendix B에 제공됩니다. 두 가지 점수 메트릭을 고려했습니다.
1. 전체 학습 기간 동안의 에피소드 평균 보상 (빠른 학습에 유리)
2. 학습 마지막 100 에피소드 동안의 에피소드 평균 보상 (최종 성능에 유리)

Table 2는 세 가지 시도의 평균 점수를 기준으로 각 알고리즘이 "이긴" 게임 수를 보여줍니다.
전체 학습 기간 동안의 평균 보상을 보면, PPO가 30개 게임에서 승리하여 A2C (1개)와 ACER (18개)를 크게 앞섰습니다. 마지막 100 에피소드만 보면 ACER가 28개로 PPO (19개)보다 더 많은 게임에서 이겼지만, 두 메트릭 모두에서 PPO는 A2C보다 우수한 성능을 보였습니다.
7 Conclusion
프록시멀 정책 최적화(Proximal Policy Optimization, PPO)는 정책 최적화 방법 중 하나로, 각 정책 업데이트를 수행하기 위해 여러 번의 확률적 경사 상승(stochastic gradient ascent) 과정을 사용합니다.
PPO는 트러스트 리전(trust-region) 방법들의 안정성과 신뢰성을 가지면서도, 구현이 훨씬 간단합니다. 바닐라 정책 경사(vanilla policy gradient) 구현에 단 몇 줄의 코드만 변경하면 적용할 수 있습니다.
또한 PPO는 더 일반적인 상황에서도 적용 가능합니다. 예를 들어, 정책과 가치 함수에 공동 아키텍처를 사용하는 경우에도 적용할 수 있습니다.
그리고 PPO는 전반적인 성능 면에서도 우수한 결과를 보여줍니다.
즉, PPO는 간단하고 범용적이면서도 안정적이고 성능이 우수한 정책 최적화 기법이라 할 수 있습니다.



댓글