Abstract
자연어 이해는 텍스트 속에 숨겨진 의미를 파악하고 질문에 대답하는 등 다양한 작업을 포함하는 분야입니다. 이러한 작업을 위해서는 대량의 텍스트 데이터가 필요한데, 레이블이 붙어 있는 데이터는 부족한 상황입니다.
이 연구에서는 레이블이 없는 텍스트를 활용하여 언어 모델을 사전 학습시키고, 이를 각 작업에 맞게 파인 튜닝하는 방법을 제안합니다. 이 방법은 기존 방식과 달리 모델 구조를 크게 변경하지 않고도 효과적으로 적용할 수 있습니다.
실험 결과, 이 방법으로 학습한 모델이 각 작업에 특화된 모델보다 더 우수한 성능을 보였습니다. 구체적으로 상식 추론, 질의응답, 텍스트 함의 등 다양한 자연어 이해 작업에서 SOTA 대비 큰 성능 향상을 달성했습니다.
즉, 대량의 텍스트 데이터를 활용한 사전 학습과 파인 튜닝을 통해 자연어 이해 능력을 크게 향상시킬 수 있음을 보여준 연구라고 할 수 있습니다.
1. Introduction
이 논문은 자연어 처리 분야에서 레이블이 없는 대량의 텍스트 데이터를 활용하여 모델을 사전 학습시키고, 이를 다양한 다운스트림 태스크에 적용하는 방법을 제안하고 있습니다.
주요 내용은 다음과 같습니다.
1. 레이블이 없는 텍스트 데이터를 활용하여 언어 모델을 사전 학습시킵니다. 이를 통해 단어 수준 이상의 언어 정보를 학습할 수 있습니다.
2. 사전 학습된 모델을 각 다운스트림 태스크에 맞게 파인 튜닝합니다. 이 과정에서는 모델 구조를 크게 변경하지 않고도 효과적인 전이 학습이 가능합니다.
3. 실험 결과, 제안된 방법으로 학습한 모델이 자연어 추론, 질의응답, 의미 유사도, 텍스트 분류 등 다양한 작업에서 기존의 SOTA을 크게 능가하는 성능을 보였습니다.
4. 사전 학습된 모델은 다운스트림 태스크에 유용한 언어 지식을 획득한 것으로 나타났습니다.
이 연구는 레이블이 부족한 상황에서도 대량의 텍스트 데이터를 활용하여 자연어 처리 모델의 성능을 크게 향상시킬 수 있는 방법을 제시했다는 점에서 의의가 있습니다. 제안된 방법은 다양한 자연어 처리 작업에 폭넓게 적용될 수 있을 것으로 기대됩니다.
2. Related Work
1.
Semi-supervised learning은 레이블이 없는 데이터를 활용하여 성능을 향상시키는 방법입니다. 초기에는 단어나 구의 통계를 사용했지만, 최근에는 word embedding 등을 활용하여 단어 수준 이상의 정보를 전달하는 방법이 연구되고 있습니다. 최근에는 phrase-level이나 sentence-level embedding을 활용하여 텍스트를 적절한 벡터 표현으로 인코딩하는 방법도 연구되고 있습니다.
2.
Unsupervised pre-training은 semi-supervised learning의 한 종류로, 레이블이 없는 데이터를 사용하여 모델을 미리 학습시키는 방법입니다.
이 방법의 목표는 지도 학습(레이블이 있는 데이터로 학습하는 방법)에 사용할 모델의 초기 상태를 잘 설정하는 것입니다. 다시 말해, 모델이 지도 학습을 시작하기 전에 이미 데이터의 특징을 어느 정도 잘 파악할 수 있도록 만드는 것이 목표입니다.
Unsupervised pre-training은 이미지 분류, 회귀 분석 등 다양한 분야에서 사용되어 왔습니다. 이 기법을 사용하면 모델이 새로운 문제에 더 잘 적응할 수 있게 됩니다. 즉, 모델의 일반화 능력이 향상됩니다.
이는 마치 시험 공부를 하기 전에 기본 개념을 미리 학습하는 것과 비슷합니다. 기본 개념을 잘 알고 있으면 새로운 문제를 더 쉽게 이해하고 해결할 수 있게 되는 것처럼, Unsupervised pre-training을 통해 모델이 데이터의 기본 특징을 미리 학습하면 새로운 문제에 더 잘 적응할 수 있게 됩니다.
3.
본 연구와 가장 유사한 방법은 언어 모델링 목적으로 신경망을 사전 학습시키고, 이를 지도 학습으로 target task에 맞게 파인 튜닝하는 것입니다. 그러나 기존 연구에서는 LSTM 모델을 사용하여 예측 능력이 단기 범위로 제한되었던 반면, 본 연구에서는 transformer 네트워크를 사용하여 장기 범위의 언어 구조를 포착할 수 있었습니다. 또한 자연어 추론, 패러프레이즈 감지, 스토리 완성 등 더 광범위한 작업에서 모델의 효과를 입증했습니다.
4.
Auxiliary training objective를 추가하는 것은 semi-supervised learning의 또 다른 형태입니다. 초기 연구에서는 POS tagging, chunking, named entity recognition, language modeling 등 다양한 NLP 작업을 보조 작업으로 사용하여 semantic role labeling의 성능을 개선했습니다. 최근 연구에서는 target task objective에 보조 언어 모델링 objective를 추가하여 sequence labeling 작업에서 성능 향상을 입증했습니다.
Auxiliary training objective는 semi-supervised learning의 한 형태로, 메인 task(주요 작업)와 함께 보조 task(부수적인 작업)를 학습시키는 방법입니다.
예를 들어, 우리의 메인 task가 semantic role labeling(문장에서 단어들의 의미적 역할을 파악하는 작업)이라고 합시다. 이때, POS tagging(품사 태깅), chunking(문장을 의미 있는 덩어리로 분할하는 작업), named entity recognition(고유 명사 인식), language modeling(언어 모델링) 등의 보조 task를 함께 학습시킬 수 있습니다.
이렇게 하면 모델이 메인 task를 학습하는 동시에 보조 task에서도 유용한 정보를 학습할 수 있습니다. 예를 들어, POS tagging을 통해 단어의 문법적 역할을 이해하고, named entity recognition을 통해 고유 명사를 인식하는 법을 배울 수 있습니다. 이렇게 학습한 정보는 메인 task인 semantic role labeling에도 도움이 됩니다.
최근 연구에서는 sequence labeling(순차 레이블링) 작업에서도 이와 유사한 접근법이 사용되었습니다. Sequence labeling은 문장의 각 단어에 레이블을 할당하는 작업인데, 여기에 언어 모델링이라는 보조 task를 추가하여 성능 향상을 이뤄냈습니다.
이처럼 auxiliary training objective는 메인 task와 관련 있는 보조 task를 함께 학습시킴으로써, 모델이 더 많은 정보를 학습하고 메인 task의 성능을 향상시키는 방법입니다. 이는 레이블이 부족한 상황에서 특히 유용하게 사용될 수 있습니다.
이 논문은 자연어 처리에서 semi-supervised learning, 특히 unsupervised pre-training의 다양한 접근 방식과 발전 과정을 소개하고, 저자들의 transformer 네트워크를 활용한 방법의 효과와 장점을 강조하고 있습니다.
3. Framework
프레임워크는 두 단계로 구성된 학습 절차를 따릅니다.
3.1 Unsupervised pre-training
1. Unsupervised pre-training 단계:
- 대량의 텍스트 코퍼스를 사용하여 언어 모델을 학습시킵니다.
- 이 단계에서는 다음 단어를 예측하는 것이 목표입니다.

- 수식 (1)은 언어 모델의 목적 함수인 로그 우도(log-likelihood)를 나타냅니다.
- 신경망 파라미터 θ는 확률적 경사 하강법(stochastic gradient descent)을 사용하여 학습됩니다.
2. Fine-tuning 단계:
- Unsupervised pre-training 단계에서 학습된 언어 모델을 사용합니다.
- 이 모델을 레이블이 있는 데이터셋으로 특정 작업에 맞게 fine-tuning합니다.

- 입력 문장은 수식 (2)와 같이 특수 토큰([CLS], [SEP] 등)과 함께 transformer 블록에 전달됩니다.
- Transformer 디코더를 사용하여 최종 출력을 생성합니다.
이 두 단계를 통해 대량의 텍스트 데이터로 언어 모델을 사전 학습시키고, 이를 특정 작업에 맞게 fine-tuning하여 성능을 높일 수 있습니다. 이는 레이블이 부족한 상황에서 특히 유용한 방법입니다.
3.2 Supervised fine-tuning
Supervised fine-tuning 단계는 unsupervised pre-training 단계에서 학습된 모델을 가져와 레이블이 있는 데이터셋 C에 대해 추가 학습을 진행합니다.
1. 입력 시퀀스 x^1, ..., x^m과 레이블 y가 주어집니다.
2. 사전 학습된 모델의 파라미터를 사용하여 입력 시퀀스를 transformer 블록에 통과시켜 최종 활성화 값 h_l^m을 얻습니다.

3. 수식 (3)과 같이 softmax 함수를 적용하여 레이블 y의 확률을 계산합니다.

4. 수식 (4)와 같이 로그 우도를 최대화하는 방향으로 모델을 학습시킵니다.
추가로, 저자들은 fine-tuning 단계에서 두 가지 보조 목적 함수를 사용하는 것이 도움이 된다는 것을 발견했습니다.

1. Language modeling 목적 함수: 수식 (5)에서 L_1(C)에 해당하며, 지도 학습 모델의 일반화 능력을 향상시킵니다.
2. 사전 학습된 언어 모델의 목적 함수: 수식 (5)에서 λ * L_1(C)에 해당하며, 학습의 수렴 속도를 높입니다.
Fine-tuning 단계에서 추가로 필요한 파라미터는 출력층의 가중치 W_y와 구분자 토큰을 위한 임베딩 벡터뿐입니다. 이를 통해 적은 수의 파라미터로 효과적인 transfer learning이 가능합니다.
3.3 Task-specific input transformations
일부 작업의 경우, 입력 데이터의 구조가 사전 학습된 모델과 다를 수 있습니다. 예를 들어, 텍스트 분류는 연속된 텍스트 시퀀스를 입력으로 사용하므로 직접 fine-tuning이 가능하지만, 질의응답이나 텍스트 추론 같은 작업은 문장 쌍, 또는 문서, 질문, 답변의 triplet과 같이 구조화된 입력을 가집니다.
이러한 구조화된 입력을 처리하기 위해 기존의 연구에서는 전이된 표현 위에 작업 특화 아키텍처를 학습하는 방법을 제안했습니다. 그러나 이는 많은 양의 작업별 커스터마이징을 다시 도입하고, 추가된 아키텍처 컴포넌트에 전이 학습을 사용하지 않는다는 단점이 있습니다.
대신 저자들은 traversal-style 접근 방식을 사용하여 구조화된 입력을 사전 학습된 모델이 처리할 수 있는 순서가 있는 시퀀스로 변환합니다. 이러한 입력 변환을 통해 작업 간 아키텍처의 광범위한 변경을 피할 수 있습니다. 입력 변환 방법은 다음과 같습니다:

1. 텍스트 추론: 전제(premise)와 가설(hypothesis) 토큰 시퀀스를 구분자 토큰($)으로 연결합니다.
2. 유사도: 두 문장의 순서를 바꾼 두 가지 시퀀스를 모두 생성하여 독립적으로 처리한 후, 두 시퀀스 표현을 요소별로 더합니다.
3. 질의응답 및 상식 추론: 문서, 질문, 가능한 답변을 구분자 토큰으로 연결한 시퀀스를 각각 독립적으로 처리한 후, softmax 층을 통해 정규화하여 가능한 답변에 대한 출력 분포를 생성합니다.
이러한 입력 변환을 통해 구조화된 입력을 사전 학습된 모델에 적용할 수 있으며, 작업 간 아키텍처의 변경을 최소화할 수 있습니다.
4 Experiments
4.1 Setup

Unsupervised Pre-training
- BooksCorpus 데이터셋을 사용하여 언어 모델을 학습시켰습니다. 이 데이터셋은 Adventure, Fantasy, Romance 등 다양한 장르의 미공개 책 7,000권 이상을 포함하며, 연속된 긴 텍스트를 포함하고 있어 생성 모델이 장거리 정보를 조건화하는 법을 학습할 수 있습니다.
- 언어 모델은 이 코퍼스에서 18.4의 매우 낮은 토큰 수준 perplexity를 달성했습니다.
Model Specifications
- 12-layer decoder-only transformer를 사용했으며, masked self-attention heads, position-wise feed-forward networks, Adam optimization scheme 등을 적용했습니다.
- Byte pair encoding (BPE) 어휘집과 residual, embedding, attention dropouts을 사용했으며, L2 regularization과 Gaussian Error Linear Unit (GELU) 활성화 함수를 사용했습니다.
- ftfy 라이브러리를 사용하여 텍스트를 정제하고 spaCy 토크나이저를 사용했습니다.
Fine-tuning Details
- Unsupervised pre-training에서 사용한 하이퍼파라미터 설정을 대부분 재사용했습니다.
- 분류기에 0.1의 dropout을 추가했으며, 대부분의 작업에서 6.25e-5의 학습률과 32의 배치 크기를 사용했습니다.
- 대부분의 경우 3 epoch의 학습으로 충분했으며, 선형 학습률 감쇠 스케줄과 warmup을 사용했습니다.
- λ는 0.5로 설정되었습니다.
4.2 Supervised fine-tuning
이 논문에서는 자연어 추론, 질의응답, 의미적 유사성, 텍스트 분류 등 다양한 자연어 처리 작업에 대해 사전 학습된 언어 모델을 fine-tuning하는 방법을 실험했습니다.
1. 자연어 추론 (Natural Language Inference):

- SNLI, MNLI, QNLI, SciTail, RTE 데이터셋을 사용하여 평가했습니다.
- 5개 중 4개 데이터셋에서 기존 최고 성능을 크게 향상시켰습니다.
2. 질의응답과 상식 추론 (Question Answering and Commonsense Reasoning)
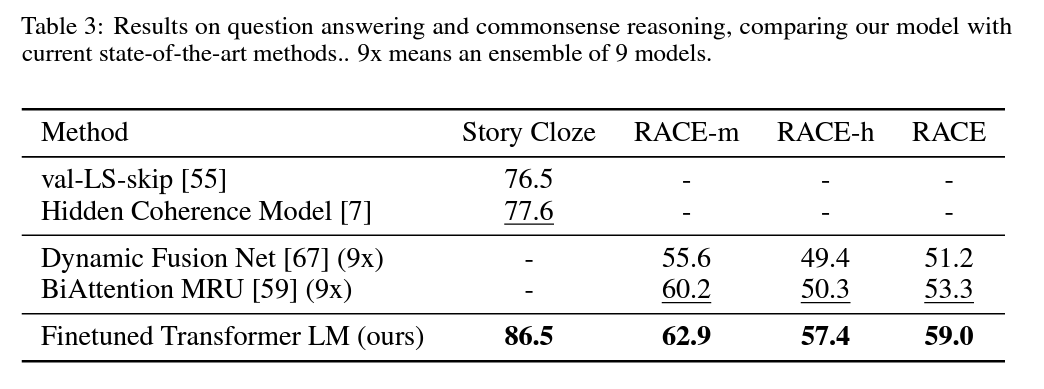
- RACE 데이터셋과 Story Cloze Test를 사용하여 평가했습니다.
- 기존 최고 결과 대비 각각 5.7%, 8.9%의 큰 성능 향상을 달성했습니다.
3. 의미적 유사성 (Semantic Similarity)
- MRPC, QQP, STS-B 데이터셋을 사용하여 평가했습니다.
- 3개 중 2개 작업에서 최고 성능을 달성했습니다.
4. 분류 (Classification)
- CoLA와 SST-2 데이터셋을 사용하여 평가했습니다.
- CoLA에서 기존 최고 결과 대비 큰 성능 향상을 보였고, SST-2에서도 최고 수준의 성능을 달성했습니다.

전반적으로 12개 데이터셋 중 9개에서 새로운 최고 성능을 달성했으며, 앙상블 모델보다도 우수한 성능을 보였습니다. 또한, 작은 데이터셋부터 큰 데이터셋까지 모두 잘 작동하는 것으로 나타났습니다.
이러한 결과는 사전 학습된 언어 모델을 fine-tuning하는 방법이 다양한 자연어 처리 작업에서 매우 효과적임을 보여줍니다.
5 Analysis
사전 학습된 언어 모델에서 supervised target task로 전이 학습할 때 전이되는 layer의 수, zero-shot 성능, 그리고 ablation study에 대해 분석합니다.

1. 전이되는 layer 수의 영향
- MultiNLI와 RACE 데이터셋에서 전이되는 layer 수에 따른 성능을 분석했습니다.
- Embedding layer부터 시작하여 layer를 추가할수록 성능이 향상되었으며, 모든 layer를 전이했을 때 최대 9%까지 성능이 향상되었습니다.
- 이는 사전 학습된 모델의 각 layer가 target task를 해결하는 데 유용한 기능을 담고 있음을 시사합니다.
2. Zero-shot 성능
- 사전 학습 중 언어 모델이 평가 대상 task들을 수행하는 능력을 분석하기 위해 휴리스틱 방법을 사용했습니다.
- 사전 학습이 진행됨에 따라 이러한 휴리스틱 방법의 성능이 안정적으로 향상되었습니다.
- 이는 사전 학습이 다양한 task와 관련된 기능 학습을 지원한다는 것을 시사합니다.
- Transformer 구조가 LSTM에 비해 zero-shot 성능이 더 안정적이었습니다.
3. Ablation Study
- Fine-tuning 중 auxiliary LM objective의 효과를 분석한 결과, 큰 데이터셋에서는 도움이 되지만 작은 데이터셋에서는 그렇지 않았습니다.
- LSTM과 Transformer 구조를 비교한 결과, Transformer가 평균적으로 5.6점 더 높은 성능을 보였습니다.
- 사전 학습 없이 Transformer를 직접 학습시킨 결과, 사전 학습을 사용한 모델에 비해 전반적으로 14.8%의 성능 하락이 있었습니다.
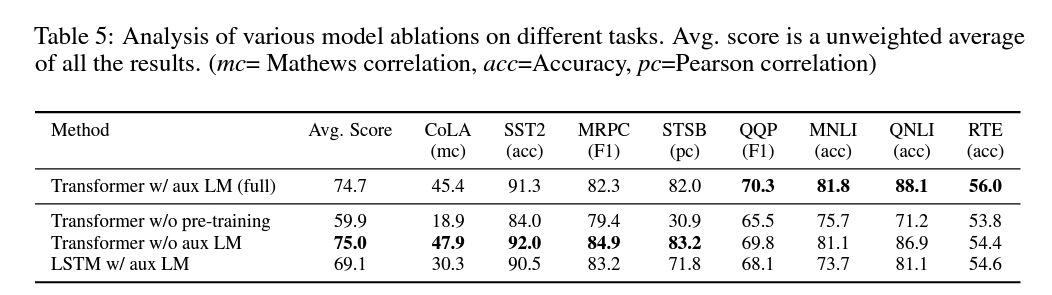
이러한 분석 결과는 사전 학습된 언어 모델의 전이 학습이 다양한 자연어 처리 작업에서 효과적임을 뒷받침합니다.
6 Conclusion
이 논문에서는 생성적 사전 학습(generative pre-training)과 판별적 파인 튜닝(discriminative fine-tuning)을 통해 단일 task-agnostic 모델로 강력한 자연어 이해를 달성하는 프레임워크를 소개합니다.
다양하고 연속적인 장문의 텍스트로 사전 학습함으로써, 모델은 상당한 세계 지식과 장거리 의존성을 처리하는 능력을 획득했습니다. 이렇게 학습된 능력은 질의응답, 의미적 유사성 평가, 텍스트 분류 등의 판별 작업을 해결하는 데 성공적으로 전이되어, 연구 대상인 12개 데이터셋 중 9개에서 최신 기술을 능가하는 성능 향상을 달성했습니다.
비지도 학습(또는 사전 학습)을 사용하여 판별 작업의 성능을 높이는 것은 오랫동안 기계 학습 연구의 중요한 목표였습니다. 이 연구는 상당한 성능 향상이 가능하다는 것을 보여주며, 이를 위해 Transformer 모델과 장거리 의존성이 있는 텍스트 데이터가 가장 효과적임을 시사합니다.
이 연구가 자연어 이해뿐만 아니라 다른 영역에서도 비지도 학습에 대한 새로운 연구를 촉진하고, 비지도 학습의 작동 방식과 시기에 대한 이해를 높이는 데 도움이 되기를 기대합니다.
'ML & DL > 논문리뷰' 카테고리의 다른 글
| RAPTOR: RECURSIVE ABSTRACTIVE PROCESSINGFOR TREE-ORGANIZED RETRIEVAL (2) | 2024.05.26 |
|---|---|
| Generative Representational Instruction Tuning (0) | 2024.05.19 |
| [PPO] Proximal Policy Optimization Algorithms (0) | 2024.05.05 |
| [GPT-2] Language Models are Unsupervised Multitask Learners (0) | 2024.04.18 |
| [BERT] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2024.04.11 |



댓글