원문: https://arxiv.org/pdf/2410.02707
코드: https://github.com/technion-cs-nlp/LLMsKnow
ABSTRACT
대규모 언어 모델(LLM)은 종종 사실과 다른 정보를 생성하거나 편향된 결과를 내놓는 등의 오류를 범합니다. 이를 "환각" 또는 "할루시네이션"이라고 부릅니다. 이 연구에서는 LLM의 내부 상태가 자신이 생성한 답변의 정확성에 대한 정보를 담고 있다는 것을 밝혀냈습니다. 이 정보는 생각했던 것보다 더 많고 다양합니다. 주요 발견 사항은 다음과 같습니다.
1. 정확성에 대한 정보가 특정 토큰(단어나 구)에 집중되어 있습니다. 이를 활용하면 오류 탐지 성능을 크게 높일 수 있습니다.
2. 하지만 이런 오류 탐지 방법은 다른 데이터셋에 적용하면 잘 작동하지 않습니다. 이는 정확성 정보가 보편적이지 않고 상황에 따라 다르다는 것을 의미합니다.
3. 내부 표현을 통해 모델이 어떤 종류의 오류를 범할지 예측할 수 있습니다. 이는 오류를 줄이는 맞춤형 전략을 개발하는 데 도움이 됩니다.
4. 모델이 내부적으로는 정답을 알고 있지만, 외부로 표출할 때는 잘못된 답을 일관되게 내놓는 경우가 있습니다.
이러한 발견들은 LLM의 오류에 대한 이해를 깊게 해주며, 앞으로 오류 분석과 개선 연구에 도움이 될 것입니다.
INTRODUCTION
이 연구는 대규모 언어 모델(LLM)의 '환각' 현상, 즉 부정확한 정보를 생성하는 문제에 대해 깊이 있게 분석했습니다. 주요 내용은 다음과 같습니다.
1. 내부 표현 분석
연구진은 LLM의 내부 작동 방식을 살펴보았습니다. 모델이 정확한 정보를 알고 있는지에 대한 신호가 내부에 있다는 것을 발견했습니다.
2. 정확성 정보의 집중
정확성에 관한 정보가 답변 중 특정 단어나 구에 집중되어 있음을 밝혀냈습니다. 이를 활용하면 오류 탐지 성능을 크게 높일 수 있습니다.
3. 다양한 진실성 개념
모델이 하나의 보편적인 '진실' 개념이 아닌, 여러 가지 다른 '진실' 개념을 가지고 있음을 발견했습니다. 이는 오류 탐지기가 다른 종류의 작업에 잘 적용되지 않는 이유를 설명합니다.
4. 오류 유형 예측
모델의 내부 표현을 통해 어떤 종류의 오류를 범할지 예측할 수 있음을 보여주었습니다. 이는 오류를 줄이는 맞춤형 전략 개발에 도움이 됩니다.
5. 내부와 외부의 불일치
모델이 내부적으로는 정답을 알고 있지만, 외부로 표출할 때는 잘못된 답을 내놓는 경우가 있음을 발견했습니다. 이는 모델의 실제 능력이 외부 행동과 다를 수 있음을 시사합니다.
2. BACKGROUND
1. LLM 오류의 정의와 특성
- '환각'이라는 용어가 여러 분야에서 다양하게 해석되고 있습니다.
- 연구자들 사이에 '환각'에 대한 통일된 정의가 없습니다. 31개의 서로 다른 개념 틀이 있다고 합니다.
- 일부 연구자들은 LLM에 '의도'가 있다고 보고 '꾸며내기'나 '날조'같은 새로운 용어를 제안하기도 합니다.
- 이 연구에서는 '환각'을 LLM이 생성하는 모든 종류의 오류로 넓게 정의했습니다.
2. 모델 중심 접근법
- 기존의 인간 중심적 해석에서 벗어나, 모델의 내부 작동 방식을 살펴보는 접근법을 제안합니다.
- LLM이 자신의 오류에 대한 정보를 내부적으로 인코딩하고 있다는 증거가 있습니다.
3. LLM의 오류 탐지
- 오류 탐지는 NLP에서 오랫동안 중요한 과제였습니다.
- 최근에는 특정 오류가 아닌 모든 유형의 오류를 다룰 수 있는 포괄적인 접근법이 필요해졌습니다.
- 외부 지식이나 다른 LLM을 판단자로 사용하는 방법도 있지만, 이 연구는 LLM 자체의 계산에만 의존하는 방법에 초점을 맞췄습니다.
4. 불확실성 추정
- 낮은 확실성은 잠재적 오류를 나타낼 수 있습니다.
- 모델의 로짓 출력값 검사, 여러 번 샘플링한 답변들 간의 일치도 확인, 확률을 직접 물어보는 방법 등이 있습니다.
5. 프로빙 분류기
- 진실성 특징을 발견하고 활용하기 위해 프로빙 분류기를 훈련시키는 방법이 있습니다.
- 대부분의 연구가 답변의 마지막 토큰이나 프롬프트의 마지막 토큰을 프로빙했습니다.
- 이 연구에서는 실제 사용 환경을 시뮬레이션하기 위해 제한 없는 답변 생성을 허용했습니다.
- 정확한 답변 토큰을 프로빙함으로써 오류 탐지 성능을 크게 향상시켰습니다.
3 BETTER ERROR DETECTION
3.1 TASK DEFINITION
이 연구에서 할 것은 LLM이 생성한 답변이 맞는지 틀린지 예측하는 것입니다.
아래와 같은 조건 하에서.
- LLM의 내부 상태에 접근할 수 있습니다 (화이트박스 설정).
- 외부 자원(예: 검색 엔진이나 다른 LLM)은 사용하지 않습니다.
- 질문-정답 쌍으로 이루어진 데이터셋을 사용합니다.
- 예: 질문 "코네티컷의 수도는 무엇인가요?", 정답 "하트퍼드"
세부 과정은 아래와 같습니다.
a) LLM에 각 질문을 입력하여 답변을 생성합니다.
b) 생성된 답변과 실제 정답을 비교합니다.
c) 비교 결과에 따라 정확성 레이블(1: 맞음, 0: 틀림)을 부여합니다.
d) 이렇게 해서 오류 탐지 데이터셋을 만듭니다: {(질문, LLM 답변, 정확성 레이블)}
여기서,
- 답변 거부 사례는 제외합니다. 이는 쉽게 '틀림'으로 분류할 수 있기 때문입니다.
- 답변의 정확성 평가는 자동화된 방법이나 지시를 따르는 LLM의 도움을 받아 수행할 수 있습니다.
3.2 EXPERIMENTAL SETUP
사용된 모델
- Mistral-7b
- Mistral-7b-instruct-v0.2
- Llama3-8b
- Llama3-8b-instruct
데이터셋
10개의 다양한 도메인과 작업을 다루는 데이터셋을 사용했습니다.
- TriviaQA (퀴즈)
- HotpotQA (복잡한 질문 답변)
- Natural Questions (자연어 질문)
- Winobias, Winogrande (언어 편향 테스트)
- MNLI (자연어 추론)
- Math (수학 문제)
- IMDB (영화 리뷰 감성 분석)
- 영화 역할 데이터셋 (직접 제작)
답변 생성 방식:
실제 사용 환경과 유사하게 제한 없이 답변을 생성하도록 했습니다.
성능 평가 지표
ROC 곡선 아래 면적(AUC)을 사용해 오류 탐지기의 성능을 평가했습니다.
오류 탐지 방법
a) Majority: 훈련 데이터에서 가장 많이 나타나는 레이블을 예측
b) 집계된 확률/로짓: 출력 토큰의 확률이나 로짓을 집계해 LLM의 확신도를 점수화
c) P(True): LLM에게 자신의 답변이 맞는지 직접 물어보는 방법
d) Probing: LLM의 중간 활성화 값을 사용해 작은 분류기를 훈련시키는 방법
- 마지막 생성 토큰, 그 전 토큰, 프롬프트의 마지막 토큰 등을 사용
- 선형 분류기를 사용
3.3 EXACT ANSWER TOKENS
1. 기존 방법의 한계
- 대부분의 오류 탐지 방법들이 마지막 생성 토큰이나 평균값만을 사용합니다.
- 이는 LLM이 긴 답변을 생성할 때 중요한 정보를 놓칠 수 있습니다.
- 프롬프트의 마지막 토큰을 사용하는 방법도 있지만, 이는 생성된 답변을 고려하지 못하는 한계가 있습니다.
2. 새로운 접근법: 정확한 답변 토큰 (Exact Answer Tokens)
- 연구팀은 생성된 답변 중 가장 의미 있는 부분인 '정확한 답변 토큰'에 주목했습니다.
- 정확한 답변 토큰: 수정하면 답변의 정확성이 바뀌는 핵심 토큰들을 의미합니다.
3. 정확한 답변 토큰의 추출
- 외부 알고리즘을 사용해 긴 답변에서 정확한 답변 부분을 추출합니다.
- 이 연구에서는 Mistral-7b-Instruct 모델을 사용했지만, 다른 LLM들도 자신의 출력에서 정확한 답변을 추출할 수 있음을 보였습니다.
4. 주목하는 토큰들
- 정확한 답변 직전의 토큰
- 정확한 답변의 첫 번째 토큰
- 정확한 답변의 마지막 토큰
- 정확한 답변 직후의 토큰
5. 실험 결과
- 각 오류 탐지 방법에 '정확한 답변' 버전을 구현했습니다.
- 이 방법이 성능을 크게 향상시키는 것으로 나타났습니다.
- 특히 프로빙(probing) 방법에서 효과가 두드러졌습니다.

3.4 RESULTS
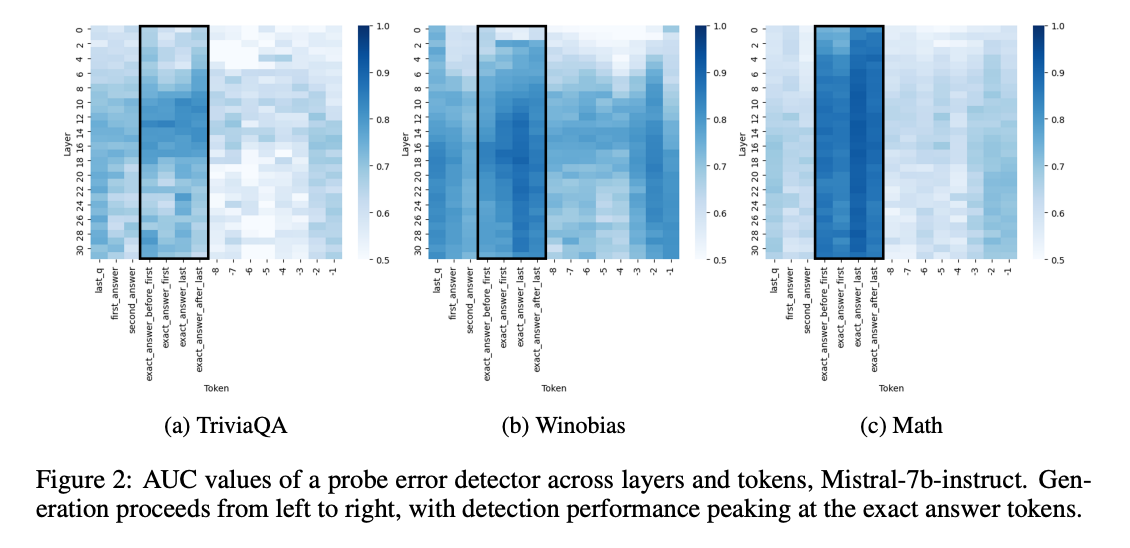
연구팀은 프로빙 분류기를 사용해 LLM의 내부 표현을 분석했습니다.
모델의 모든 층과 토큰을 체계적으로 조사했습니다.
주요 발견은 아래와 같습니다.
a) 층(Layer) 선택
- 중간에서 후반부 층이 가장 효과적인 프로빙 결과를 보였습니다.
- 이는 이전 연구 결과와 일치합니다.
b) 토큰 선택
- 프롬프트 직후에 강한 진실성 신호가 나타납니다.
(이는 모델이 질문에 정확히 답할 수 있는지에 대한 정보를 담고 있습니다)
- 텍스트 생성이 진행되면서 이 신호는 약해집니다.
- 정확한 답변 토큰에서 신호가 다시 강해집니다.
- 생성 과정 끝부분에서 신호 강도가 다시 올라갑니다.
(전체 생성 내용의 특징을 인코딩하지만, 정확한 답변 토큰보다는 약합니다)
이러한 패턴은 거의 모든 데이터셋과 모델에서 일관되게 나타났습니다. 이는 LLM이 텍스트 생성 중 진실성을 인코딩하고 처리하는 일반적인 메커니즘이 있음을 시사합니다.
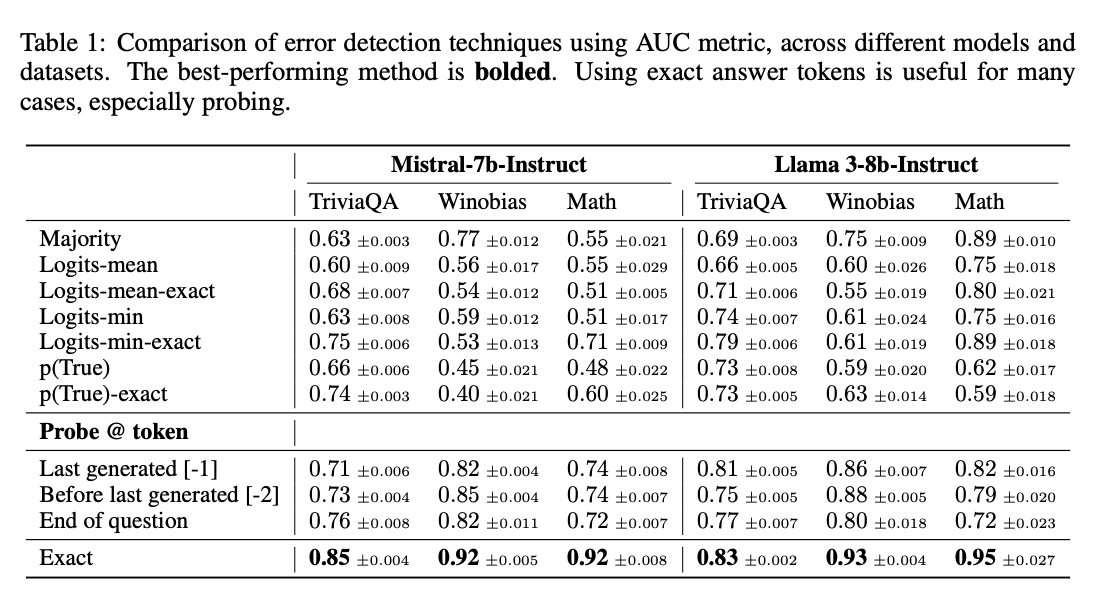
다양한 오류 탐지 방법을 정확한 답변 토큰 사용 여부에 따라 비교했습니다.
- 정확한 답변 토큰 중 마지막 토큰이 가장 좋은 성능을 보였습니다.
- 정확한 답변 토큰을 활용하면 거의 모든 데이터셋에서 오류 탐지 성능이 향상되었습니다.
- 연구팀의 프로빙 기법이 다른 모든 기준 방법들보다 일관되게 좋은 성능을 보였습니다.
결론
- 진실성에 대한 정보가 특정 생성 토큰에 매우 집중되어 있습니다.
- 정확한 답변 토큰에 집중하면 오류 탐지 성능이 크게 향상됩니다.
4 GENERALIZATION BETWEEN TASKS
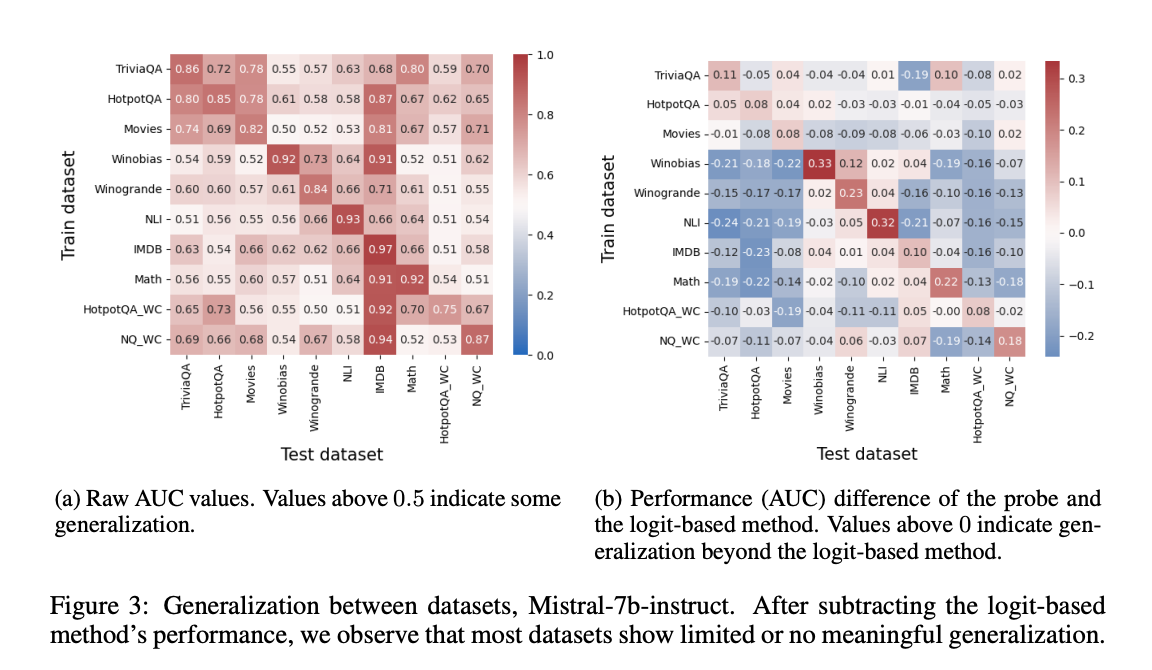
프로빙 분류기가 오류 탐지에 효과적이라는 것은 LLM이 자신의 출력의 진실성에 대한 정보를 인코딩한다는 것을 시사합니다. 하지만 이 방법이 다른 작업에도 일반화될 수 있는지는 불분명했습니다.
따라서 한 데이터셋에서 훈련된 프로브가 다른 데이터셋의 오류를 탐지할 수 있는지 조사했습니다. 다양한 비합성 설정을 포함하는 여러 데이터셋을 사용했습니다.
주요 결과로는 다음과 같습니다.
a) 일반화 성능
- 대부분의 경우 0.5 이상의 AUC 점수를 보여, 어느 정도 일반화가 가능함을 시사했습니다.
- 이는 진실성을 디코딩하는 보편적 메커니즘이 존재할 수 있다는 것을 지지합니다.
b) 로짓 기반 탐지와의 비교
- 하지만 대부분의 성능은 단순히 출력 로짓을 관찰하는 것만으로도 달성할 수 있었습니다.
- 이는 일반화가 진실성의 보편적 내부 인코딩에서 오는 것이 아니라, 로짓과 같은 외부 특징에서 이미 접근 가능한 정보를 반영한다는 것을 의미합니다.
c) 유사한 기술 요구 작업 간의 일반화
- 비슷한 기술을 요구하는 작업들 사이에서는 성공적인 일반화가 관찰되었습니다.
- 예: 사실 검색 작업들(TriviaQA, HotpotQA, Movies) 사이, 상식 추론 작업들(Winobias, Wingrande, NLI) 사이
정리하자면,
- LLM은 하나의 보편적인 진실성 메커니즘이 아닌, 여러 "기술 특화" 진실성 메커니즘을 가지고 있습니다.
- 모델은 진실성에 대해 다면적인 표현을 가지고 있으며, 이는 여러 다른 진실 개념에 대응합니다.
- 일부 패턴(예: TriviaQA에서 Math 작업으로의 비대칭적 일반화)은 여전히 설명되지 않았습니다.
향후 연구 방향으로 이러한 다양한 진실성 메커니즘을 분리하고 이해하기 위한 추가 연구가 필요합니다.
5 INVESTIGATING ERROR TYPES
이전에는 오류 탐지의 한계를 살펴보았습니다. 이제 오류 분석으로 초점을 옮깁니다. 특정 작업(TriviaQA)에서 LLM이 범하는 오류 유형에 집중합니다. TriviaQA는 사실 관련 오류를 대표하는 데이터셋입니다. 사실 관련 오류는 LLM에서 가장 흔히 연구되는 문제 중 하나입니다.여러 연구자들(Kadavath, Snyder, Li, Chen, Simhi 등)이 이 주제를 다루어 왔습니다.
5.1 TAXONOMY OF ERRORS
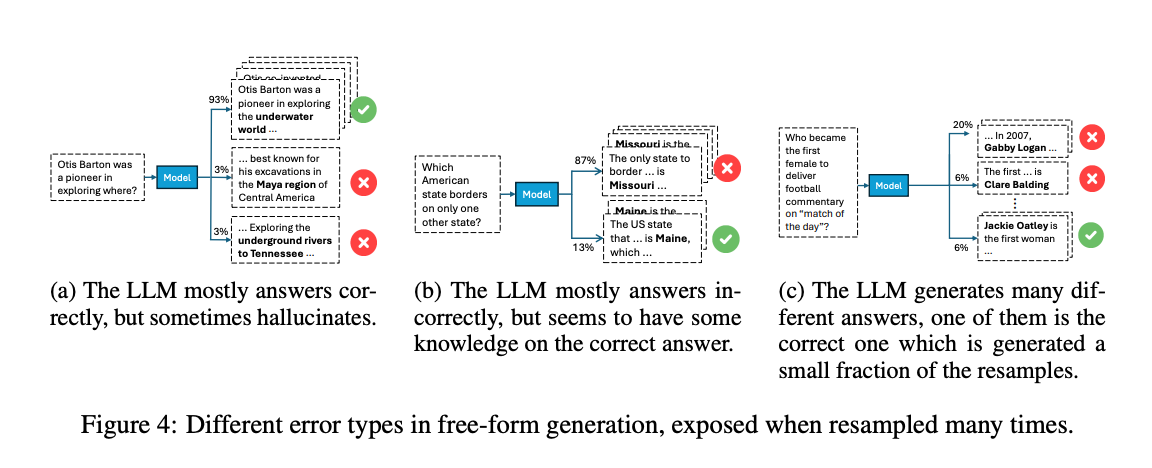
모든 오류가 동일하지 않습니다. 예를 들어, LLM이 일관되게 틀린 답을 생성하는 경우와 최선의 추측을 하는 경우가 있습니다.
오류의 종류를 분석하기 위해 각 예시에 대해 30개의 응답을 샘플링했습니다 (온도 설정 T = 1). 그리고 생성된 답변의 분포를 분석했습니다.
대표적인 오류 유형으로는, (Figure 4)
a) 대체로 맞지만 가끔 틀리는 경우
b) 대체로 틀리지만 가끔 맞는 경우
c) 다양한 틀린 답변을 생성하는 경우
가 있습니다.
오류 분류를 위한 피쳐로는 생성된 서로 다른 답변의 수, 정답의 빈도, 가장 흔한 오답의 빈도를 사용했습니다.
오류 패턴 분류결과는 다음과 같습니다.
A. 답변 거부: 50% 이상 답변할 수 없다고 응답
B. 일관되게 정확: 50% 이상 정답 (B1: 항상 정답, B2: 대체로 정답)
C. 일관되게 부정확: 50% 이상 같은 오답 (C1: 정답 없음, C2: 정답 최소 1회)
D. 두 개의 경쟁 답변: 정답과 오답이 비슷한 빈도로 나타남
E. 다양한 답변: 10개 이상의 서로 다른 답변 (E1: 정답 없음, E2: 정답 최소 1회)
이 분류법은 Mistral-7b-instruct의 TriviaQA 오류의 96%를 포함합니다. 유형 간 일부 중복이 있지만, 일반적인 패턴을 식별하는 것이 목적입니다. 이 접근법은 LLM이 범하는 오류의 성질도 함께 검토합니다. 행동 패턴과 모델의 내부 인코딩 간의 연관성을 분석합니다.
5.2 PREDICTING ERROR TYPES
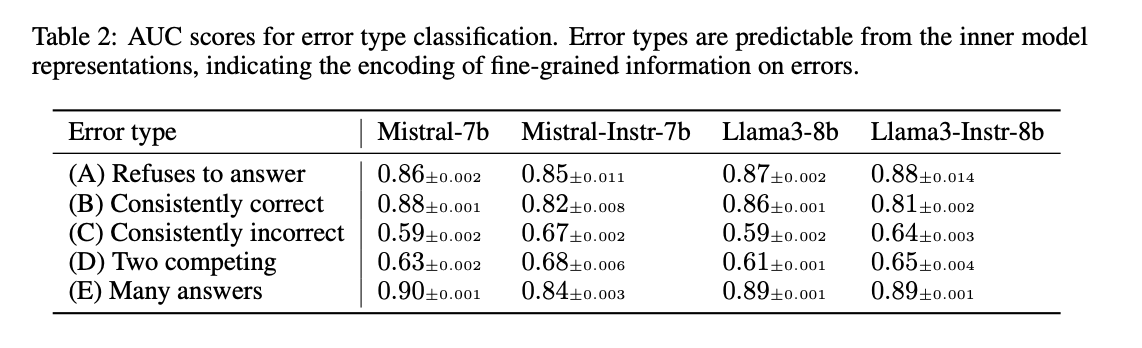
외부적, 행동 기반 분석(taxonomy)과 내부적 평가를 결합해서, LLM이 잠재적 오류 유형에 대한 정보를 내부 활성화에 인코딩하는지 탐구합니다. 이를 통해 LLM의 기저 메커니즘에 대한 더 깊은 통찰을 얻고자 합니다.
연구 방법:
- '일대다' 설정의 프로브를 훈련시켰습니다.
- 하나의 프로브가 특정 오류 유형을 다른 모든 유형과 구별합니다.
- 탐욕적 디코딩(greedy decoding)으로 생성된 답변에서 추출한 표현을 사용했습니다.
주요 발견:
- 오류 유형을 탐욕적 디코딩 생성의 중간 표현에서 예측할 수 있었습니다.
- 이는 LLM의 중간 표현이 단순히 출력의 정확성뿐만 아니라 잠재적 오류에 대한 세부 정보와 관련된 특징도 인코딩할 수 있음을 시사합니다.
연구의 의의:
- 이러한 예측 가능성은 특정 오류 유형에 대한 맞춤형 개입 가능성을 열어줍니다.
- 즉, 각 오류 유형에 맞는 특별한 처리나 개선 방법을 개발할 수 있는 기반을 제공합니다.
Table 2에서는 모든 모델에 대한 테스트 세트 결과를 보여줍니다. 이는 다양한 LLM에서 이러한 오류 유형 예측이 가능함을 나타냅니다.
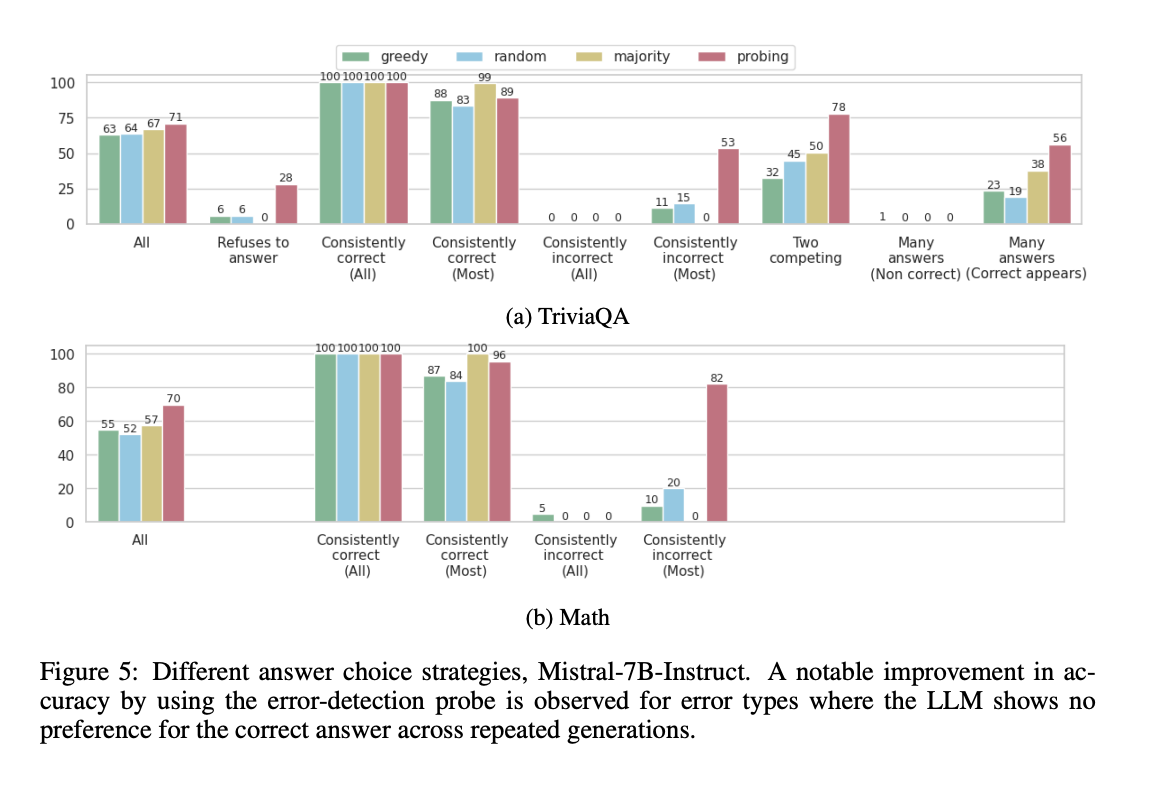
6 DETECTING THE CORRECT ANSWER
LLM의 내부적 진실성 표현과 외부적 행동 간의 일치성을 조사했습니다.
- 오류 탐지 훈련을 받은 프로브를 사용해 30개의 생성된 응답 중 하나를 선택합니다.
- 선택된 답변의 정확도를 측정합니다.
- TriviaQA, Winobias, Math 데이터셋에서 실험을 진행했습니다.
비교 기준은 다음과 같습니다.
- 탐욕적 디코딩
- 30개 답변 후보 중 무작위 선택
- 다수결 투표 (가장 자주 생성된 답변 선택)
주요 결과 (Mistral-7b-instruct 모델 기준)는 다음과 같습니다.
- 프로브를 사용한 답변 선택이 모든 작업에서 LLM의 정확도를 향상시켰습니다.
- 오류 유형에 따라 개선 정도가 다릅니다:
- "대체로 정확한" 카테고리(B2)에서는 개선이 미미했습니다.
- "대체로 부정확한"(C2), "두 개의 경쟁 답변"(D), "다양한 답변"(E1) 카테고리에서는 30-40점의 큰 개선이 있었습니다.
- 프로브는 LLM이 정답에 대한 외부적 선호도가 없는 경우에 가장 효과적이었습니다.
즉,
- LLM의 내부 인코딩과 외부 행동 사이에 상당한 불일치가 있음을 보여줍니다.
- 모델이 내부적으로 정답에 대한 정보를 인코딩하고 있어도 실제로는 잘못된 답변을 생성할 수 있습니다.
이 방법은 오류 감소 전략으로 제안된 것이 아니라 진단 도구로 사용되었습니다. LLM 내부에 이미 존재하는 지식을 활용하여 오류를 크게 줄일 수 있는 가능성을 보여줍니다. LLM 내부의 기존 지식을 활용하여 오류를 줄이는 방법을 더 탐구할 것을 권장합니다.
7 DISCUSSION AND CONCLUSIONS
이 연구의 주요 발견을 정리하면 다음과 같습니다.
- 진실성 관련 정보가 정확한 답변 토큰에 집중되어 있습니다.
- 이는 오류 탐지 방법을 크게 개선합니다.
한계점으로는, 내부 표현에 대한 접근이 필요하기 때문에, 주로 오픈소스 모델에만 적용 가능하다는 점입니다.
진실성 특징의 일반화
- 다른 작업과 데이터셋 간에는 일반화가 잘 되지 않습니다.
- 비슷한 기술이 필요한 작업 사이에서는 더 잘 일반화됩니다.
- 이는 진실성이 "기술 특화" 특징에 의존할 수 있음을 시사합니다.
오류 유형 예측
- LLM의 중간 표현을 사용해 발생 가능한 오류 유형을 예측할 수 있습니다.
- 이는 오류 유형별 맞춤 완화 전략 개발에 유용합니다.
내부 상태와 외부 행동의 불일치
- 모델이 내부적으로 정답을 알고 있어도 잘못된 답변을 반복적으로 생성할 수 있습니다.
- 이는 가능성이 높은 토큰을 예측하도록 훈련된 LLM의 특성 때문일 수 있습니다.
향후 연구 방향
- 모델 내부에 이미 인코딩된 가치 있는 정보를 활용하여 오류를 줄이는 방법 연구
- 초기 트랜스포머 층에 인코딩된 지식을 활용하여 진실성을 개선하는 연구
최종 결론
- LLM의 내부 표현은 오류에 대한 유용한 통찰을 제공합니다.
- 모델의 내부 프로세스와 외부 출력 간의 복잡한 연관성을 강조합니다.
- 이는 오류 탐지와 완화를 위한 추가 개선의 기반이 될 수 있습니다.




댓글