원문: https://ar5iv.labs.arxiv.org/html/2407.03282
LLM Internal States Reveal Hallucination Risk Faced With a Query
The hallucination problem of Large Language Models (LLMs) significantly limits their reliability and trustworthiness. Humans have a self-awareness process that allows us to recognize what we don’t know when faced with …
ar5iv.labs.arxiv.org
Abstract
LLM의 환각 문제는 신뢰성을 크게 떨어뜨립니다.
해당 논문에서 연구진은 LLM이 답변을 생성하기 전에 스스로 환각 위험을 추정할 수 있는지 조사했습니다.
700개 이상의 데이터셋과 15개의 자연어 생성 작업을 분석했습니다.
분석 결과로는 두 가지 주요 발견이 있었습니다.
- LLM은 학습 데이터에서 질문을 본 적이 있는지 알 수 있습니다.
- LLM은 질문에 대해 환각할 가능성이 있는지 알 수 있습니다.
연구진은 LLM 내부의 특정 뉴런, 활성화 층, 토큰이 불확실성과 환각 위험 인식에 중요한 역할을 한다는 것을 발견했습니다.
이를 바탕으로 LLM의 자체 평가를 활용하는 추정기를 개발했고, 실행 시 평균 84.32%의 환각 추정 정확도를 달성했습니다.
이 연구는 LLM이 자신의 한계를 인식하고 더 신뢰할 수 있는 답변을 제공할 수 있도록 하는 중요한 진전을 보여줍니다.
1 Introduction
인간은 자신의 지식의 범위와 한계를 인식할 수 있습니다. 이로 인해 불확실한 상황에서 망설이게 됩니다.
그러나 LLM은 이러한 자기 인식 능력이 부족합니다. 따라서 과도하게 자신감을 보이고 환각이나 혼동을 일으킬 수 있습니다. 이는 실제 응용에서 신뢰성 문제를 야기합니다.
따라서 이 연구의 목적은 LLM의 내부 상태가 환각 위험을 나타내는지 조사하는 것입니다. 응답 생성 전에 이를 신뢰성 있게 추정할 수 있는지 확인합니다.
연구 방법으로는 15개의 다양한 자연어 생성 작업에 걸쳐 700개 이상의 데이터셋을 분석했습니다. 특정 뉴런, 활성화 층, 토큰이 LLM의 불확실성과 환각 위험 인식에 미치는 영향을 탐구했습니다.
연구 결과, LLM의 내부 상태를 분석하여 두 가지 측면에서 자기 인식을 검증했습니다.
a) 학습 데이터에서 질문을 본 적이 있는지 여부 (정확도 80.28%)
b) 질문에 대해 환각할 가능성 (평균 정확도 84.32%)

이러한 내부 표현을 이해하면 불확실성을 사전에 추정할 수 있습니다. 이는 정보 검색 보강의 필요성을 판단하거나 조기 경고 시스템으로 활용될 수 있습니다. 이 연구는 LLM의 자기 인식 능력을 향상시키고 환각 문제를 줄이는 데 중요한 통찰을 제공합니다. 이를 통해 LLM의 신뢰성과 실용성을 크게 개선할 수 있을 것으로 기대됩니다.
2 Hallucination and Training Data
LLM의 환각 문제는 데이터와 모델링 두 가지 주요 원인에서 비롯됩니다. 데이터 관련 요인으로는 보지 못한 지식, 작업별 고유한 차이, 노이즈가 있는 학습 데이터 등이 있습니다. 모델링 측면에서는 모델 구조, 정렬 세금, 교사 강제 최대 우도 추정 훈련 등이 원인이 될 수 있습니다.
연구진은 LLM이 학습 데이터에서 보지 못한 질문에 대해 답변을 거부하지 않고 정보를 제공하려 할 때 환각이 자주 발생한다는 점에 주목했습니다. 이에 LLM이 학습 데이터에서 질문을 본 적이 있는지 인식할 수 있는 능력을 내부 상태 분석을 통해 조사했습니다. 이를 위해 LLM 출시 전후의 뉴스를 수집하여 보지 못한 데이터와 본 데이터를 대표하는 두 가지 질문 세트를 만들었습니다.
그러나 실제 상황에서는 LLM의 방대한 학습 데이터에 접근할 수 없기 때문에 데이터를 완전히 본 것과 보지 못한 것으로 분류하는 것은 불가능합니다. 따라서 연구진은 더 나아가 LLM이 주어진 질문에 대해 환각을 일으킬 가능성이 있는지 스스로 인식할 수 있는지 조사했습니다. 이때 환각은 보지 못한 데이터와 본 데이터 모두에서 발생할 수 있음을 유의해야 합니다. 본 데이터에서도 모델링의 결함으로 인해 환각이 발생할 수 있기 때문입니다.
이 분석을 위해 연구진은 다양한 자연어 생성 작업에 대해 LLM이 직접 응답을 생성하도록 하고, 그 응답에서 환각 수준을 라벨링하는 방식으로 데이터를 구성했습니다. 이러한 접근 방식을 통해 LLM의 자기 인식 능력과 환각 위험을 더 깊이 이해하고자 했습니다.
3 Methodology
1. 문제 정의
연구진은 먼저 질문에 직면했을 때 불확실성을 추정하는 문제를 정의합니다. 이는 LLM이 자신의 답변에 대한 확신 정도를 어떻게 판단할 수 있는지에 대한 것입니다.
2. 데이터셋 구성
연구를 위해 두 가지 차원에 초점을 맞춘 데이터셋을 구성했습니다.
a) 학습 데이터에서 본 질문과 보지 못한 질문의 구분
b) 질문에 대해 환각이 발생할 가능성
3. 내부 상태 표현의 효과 검증
LLM의 내부 상태가 환각을 추정하는 데 얼마나 효과적인지 검증하기 위해 두 가지 방법을 사용했습니다.
a) 시각화: 특정 LLM 층에서 추출한 인식 뉴런을 시각화했습니다. 이를 통해 LLM이 질문을 어떻게 '이해'하는지 볼 수 있습니다.
b) 프로빙 분류기: 질문의 마지막 토큰과 관련된 내부 상태에 대해 프로빙 분류기 기법을 적용했습니다. 이 기법은 LLM의 내부 표현이 특정 작업(여기서는 환각 위험 추정)에 얼마나 유용한 정보를 담고 있는지 평가하는 데 사용됩니다.

이러한 방법을 통해 연구진은 LLM이 질문에 대한 자신의 지식 수준과 환각 위험을 얼마나 잘 인식할 수 있는지, 그리고 이러한 정보가 LLM의 내부 상태에 어떻게 인코딩되어 있는지를 분석하고자 했습니다.
3.1 Problem Formulation
LLM 모델의 정의부터 하면 다음과 같습니다.
- f는 대규모 언어 모델(LLM)입니다.
- θ는 이 모델의 매개변수입니다.
- 모델은 사용자의 질문 q를 받아 내부 상태 I와 응답 r을 생성합니다.
- 이를 수식으로 표현하면 다음과 같습니다. I,r=fθ(q)
이 연구의 목적은 LLM의 '자기 인식' 능력을 조사하는 것입니다. 특히, 내부 상태 I가 질문 q에 대한 환각 위험 수준 h와 어떤 관계가 있는지 알아보고자 합니다. 이 관계를 수식으로 표현하면 다음과 같습니다. u=𝔼(Iθ,q) 여기서 𝔼는 추정기 함수를 나타냅니다.
데이터셋 구성은 다음과 같습니다. 𝒟θ={⟨Iθ,q,itrain,hitrain⟩}i=1N
이 데이터셋은 N개의 질문-라벨 쌍으로 구성됩니다.
hitrain은 환각 위험 라벨로, 두 가지 기준으로 결정됩니다.
a) 질문이 학습 데이터에 있는지 여부
b) 질문 q에 대한 응답 r의 환각 정도
최종 목표는 환각 위험 h를 추정하는 것입니다. 이를 수학적으로 표현하면 다음과 같습니다. h=𝔼(Iθ,q;𝒟θ)(1)
3.2 Data Construction
연구의 두 가지 주요 측면은 다음과 같습니다.
a) LLM이 학습 데이터에서 질문을 본 적이 있는지 여부
b) LLM이 질문에 대해 환각을 일으킬 가능성
학습 데이터에서 본, 그리고 보지 못한 질문을 구분하는데, 보지 못한 질문은 정보 부족으로 환각을 유발할 수 있습니다.
데이터셋 구성은 다음과 같습니다.
* 본 그룹: 2020년 BBC 뉴스 (LLM 학습 시 포함되었을 가능성 높음)
* 보지 못한 그룹: 2024년 BBC 뉴스 (LLM 출시 이후)
두 그룹의 길이 분포와 의미 정보를 유사하게 맞추어 비교하기 쉽게 하였습니다.
LLM을 사용해 다양한 자연어 생성 작업에 대한 응답을 직접 생성하였으며, 생성된 응답과 해당 질문에 대해 환각 수준을 레이블링 하였습니다. 이는 실제 응용에서의 성능과 비슷하게 하기 위한 작업이었습니다.
생성된 응답을 평가 하는 방법은 다음과 같습니다.
a) Rouge-L: 생성된 응답과 표준 참조를 비교
b) 자연어 추론(NLI): 생성된 텍스트의 논리적 일관성 평가
c) Questeval: QA 기반 메트릭으로 생성된 출력의 충실도 평가
종합적 평가 전략은 다음과 같습니다.
- NLI가 함의를 예측하고 Rouge-L과 Questeval이 각각의 중앙값을 초과하면 라벨 1 부여
- NLI가 모순 또는 중립을 예측하고 Rouge-L과 Questeval이 중앙값 미만이면 라벨 0 부여
- 이 전략은 이진 품질 평가와 다차원적 텍스트 평가를 동시에 제공
3.3 Preliminary Analysis: Neurons for Hallucination Perception from Internal States
언어 모델에서 내부 상태는 토큰 예측을 통해 학습한 풍부한 맥락과 의미 정보를 담고 있습니다. 이는 다양한 자연어 처리 작업에 관련된 복잡한 패턴과 관계를 인식하는 데 뛰어납니다. 따라서 환각 위험을 추정하는 강력한 도구가 될 수 있습니다.
이를 분석하기 위해 상호 정보(Mutual Information)에 기반한 피쳐 선택 방법을 사용했습니다. 이 기법은 데이터셋의 카테고리를 구분하는 데 있어 각 피쳐의 관련성을 측정합니다.
실험 설계는 다음과 같습니다.
- 대화, 질의응답, 번역 등 다양한 자연어 생성 작업을 대상으로 했습니다.
- 마지막 활성화 층에서 가장 중요한 8개의 뉴런을 선택하여 시각화했습니다.
실험 결과 주요 발견은 다음과 같습니다.
- 선택된 뉴런들이 불확실성에 민감하게 반응함을 확인했습니다.
- 이 뉴런들은 알려진 질문과 알려지지 않은 질문에 대해 다른 수준의 환각을 구분할 수 있었습니다.
- 즉, LLM 내부에 불확실성을 인식하고 미래의 환각을 예측할 수 있는 개별 뉴런이 존재한다는 것을 발견했습니다.
이러한 접근 방식은 환각과 관련된 신경학적 상관관계에 대한 이해를 높입니다. 또한 환각의 영향을 줄이기 위한 targeted interventions(표적 개입) 개발의 길을 열어줍니다.
3.4 Internal State-based Estimator
연구에서 사용한 추정 모델의 구조와 작동 방식을 설명하도록 하겠습니다.
1. 입력 데이터
- 질문의 마지막 토큰에 해당하는 내부 상태를 사용합니다.
- 이를 xq로 표기합니다.
- 이 내부 상태는 LLM의 특정 층에서 추출됩니다.
- 이러한 상태를 사용하는 이유는 접근성이 좋고 쉽게 얻을 수 있어 실용적이기 때문입니다.
2. 추정기 모델 구조
- 다층 퍼셉트론(MLP)의 변형을 사용합니다.
- 이 모델은 Llama라는 언어 모델에서 채택한 구조를 기반으로 합니다.
3. 추정기의 수학적 표현
H=down(up(xq)×SiLU(gate(xq)))
여기서,
- SiLU는 활성화 함수입니다.
- down은 다운-프로젝션을 위한 선형 층입니다.
- up은 업-프로젝션을 위한 선형 층입니다.
- gate는 게이트 메커니즘을 위한 선형 층입니다.
4. 모델의 특징
- 내부 상태(xq)와 Llama MLP 구조를 결합하여 사용합니다.
- 이 조합은 자연어 생성 작업에서 환각 위험을 추정하는 복잡한 문제를 다루는 데 효과적입니다.
4 Experiments
4.1 Dataset
1. 학습 데이터에서 본/보지 못한 질문 구분을 위한 데이터셋
- LatestEval 벤치마크를 사용했습니다.
- 이 벤치마크는 평가 과정에서 데이터 오염을 방지하기 위해 동적이고 시간에 민감한 방식으로 구성되었습니다.
- 연구진은 2020년 1월과 2024년 1월의 BBC 뉴스를 사용했습니다.
* 2020년 데이터: LLM이 학습 시 보았을 가능성이 높은 데이터
* 2024년 데이터: LLM 출시 이후의 데이터로, 보지 못했을 가능성이 높음
- 총 2,800개의 샘플을 포함하여 본 데이터와 보지 못한 데이터를 모두 대표할 수 있게 했습니다.
2. 질문에 대한 환각 위험 평가를 위한 데이터셋
a) Super-Natural Instructions 벤치마크
- 1,616개의 다양한 자연어 처리 데이터셋과 전문가가 작성한 지시사항을 포함합니다.
- 이 중 15개의 자연어 생성 작업 카테고리를 선택했습니다.
* 질의응답, 요약, 번역 등을 포함
* 700개 이상의 데이터셋으로 구성
- 전체 작업 목록은 논문의 부록에서 확인할 수 있습니다.
b) ANAH 데이터셋
- 생성형 질의응답에서 LLM의 환각에 대한 분석적 주석을 제공하는 이중 언어 데이터셋입니다.
- 연구진은 영어 샘플만 사용했고, 환각 유형을 테스트 단계의 라벨로 사용했습니다.
- 이 데이터셋은 추정기의 환각 측면에서의 성능과 일반화 능력을 테스트하는 데 사용되었습니다.
4.2 LLM
Llama2-7B를 주로 사용했습니다. 이 모델은 Touvron 등이 2023년에 발표한 모델입니다. Llama2-7B의 내부 상태를 분석하여 환각 위험을 추정했습니다.
또한 Mistral-7B 모델도 함께 연구했습니다. Mistral-7B는 Jiang 등이 2023년에 발표한 모델입니다. 이 모델의 다양한 내부 상태가 미치는 영향을 논문의 5장에서 탐구했습니다.
연구진은 이 두 모델을 사용하여 LLM의 내부 상태가 환각 위험 추정에 어떻게 활용될 수 있는지 분석했습니다. Llama2-7B를 주로 사용하면서, Mistral-7B를 추가로 연구함으로써 결과의 일반화 가능성을 탐구했습니다. 이는 다양한 LLM에 대한 이해를 넓히고, 환각 문제에 대한 더 포괄적인 해결책을 찾는 데 도움이 될 수 있습니다.
4.3 Baselines

1. 제로샷 프롬프트 방식
- LLM에게 직접 질문에 정확하게 답변할 수 있는지 물어봅니다.
- 프롬프트: "질문: {질문내용}\n\n위 질문에 정확하게 답변할 수 있습니까? 'yes' 또는 'no'로만 답하고 질문 내용에 대해서는 언급하지 마세요."
2. 문맥 내 학습(ICL) 프롬프트 방식
- LLM에게 질문에 정확하게 답변할 수 있는지 물어보고 몇 가지 예시를 제공합니다.
- 프롬프트에는 여러 예시 질문과 그에 대한 답변('yes' 또는 'no')이 포함되며, 마지막에 실제 질문이 제시됩니다.
3. 복잡도(Perplexity, PPL) 기반 방식
- 프롬프트 기반 방법들이 모델의 내부 지식만 사용하는 점을 고려하여, 학습 데이터셋의 분포를 활용합니다.
- 가정: LLM이 모든 가능한 질문-응답 쌍을 완벽하게 포함하는 가상의 대규모 데이터셋으로 학습되었다고 가정합니다.
- 방법:
a) 각 질문에 대한 복잡도(PPL)를 계산합니다.
b) 학습 데이터셋에서 최대 정확도를 얻는 최적의 PPL 임계값을 찾습니다.
c) 이 최적 임계값을 테스트 데이터셋에 적용하여 환각 위험 추정 방법의 정확도를 측정합니다.
이러한 기준 방법들은 LLM의 자기 인식 능력과 환각 위험 추정 능력을 평가하는 데 사용됩니다. 프롬프트 기반 방법은 모델의 내부 지식을 직접 활용하는 반면, 복잡도 기반 방법은 학습 데이터의 분포를 고려합니다. 이를 통해 다양한 각도에서 LLM의 성능을 평가하고 비교할 수 있습니다.
4.4 Estimator Evaluation Protocols
불연속형이 예측된 분류 작업의 경우 F1과 정확도를 활용하여 예측된 분류의 품질을 측정합니다.
5 Results and Analysis

5.1 Results for Internal State-based Estimator
1. 학습 데이터에서 본/보지 못한 질문 구분
- 내부 상태 기반 추정기의 성능을 평가했습니다.
- F1 점수: 80.28%, 정확도: 80.24%
- 이 높은 결과는 내부 상태 기반 방법이 보지 못한 질문을 식별하는 데 효과적임을 보여줍니다.
- 이는 모델이 답변 가능한 질문과 불가능한 질문(미래 정보 포함)을 구분할 수 있다는 이전 연구들과 일치합니다.
2. 질문에 대한 환각 위험 추정
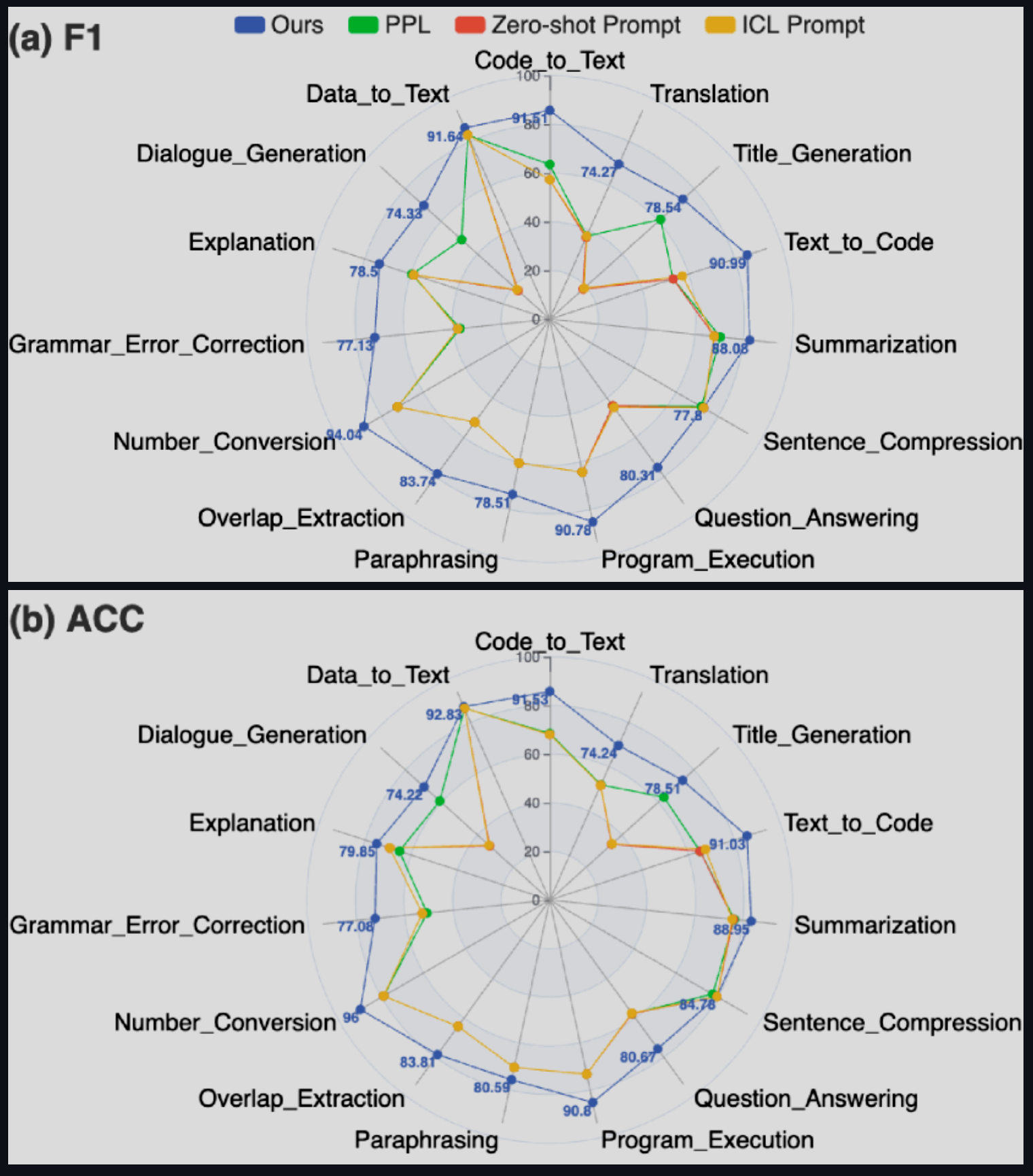
- 연구진의 방법이 F1 점수와 정확도 모두에서 우수한 성능을 보였습니다.
- 다양한 작업에서 안정적인 성능을 유지했습니다.
- 번역 작업에서는 상대적으로 낮은 성능(F1과 정확도 76.90%)을 보였습니다.
- 숫자 변환 작업에서 가장 높은 성능(F1 94.04%, 정확도 96.00%)을 보였습니다.
3. 기준 방법들의 성능
- 제로샷 프롬프트와 ICL(문맥 내 학습) 방식은 비슷한 결과를 보였습니다.
* ICL이 제로샷 프롬프트보다 약간 더 나은 성능을 보였습니다.
* 두 방법 모두 과도하게 자신감 있는 예측을 하는 경향이 있었습니다(재현율 99%).
- 복잡도(PPL) 기반 방법
* 프롬프트 방법들보다 더 나은 성능을 보였습니다.
* 작업에 따라 성능 편차가 컸습니다.
* 번역 작업에서 낮은 성능(F1 33.73%, 정확도 50.36%)을 보였습니다.
* 데이터-텍스트 변환 작업에서 가장 높은 성능(F1 88.28%, 정확도 92.08%)을 보였습니다.
이 결과는 내부 상태 기반 방법이 다양한 작업에서 환각 위험을 추정하는 데 효과적임을 보여줍니다. 특히 기존의 프롬프트 기반 방법이나 복잡도 기반 방법보다 더 안정적이고 우수한 성능을 보였습니다. 이는 LLM의 신뢰성을 향상시키는 데 중요한 진전을 나타냅니다.

5.2 Analysis
1. 층의 깊이와 예측 성능의 상관관계
- 더 깊은 층일수록 환각 위험 추정 성능이 더 좋았습니다.
- 초기 층: 기본적인 문법 정보를 포착하여 성능이 낮음
- 중간 층: 더 복잡한 의미 관계를 인코딩하여 성능이 향상됨
- 깊은 층: 가장 좋은 성능을 보이며, 고수준의 표현으로 환각 패턴을 학습함
- 이는 중간 층이 가장 좋은 성능을 보였던 이전 연구와는 다른 결과입니다.
2. 다른 LLM 간의 내부 상태 일관성
- Mistral-7B의 내부 상태를 사용하여 Llama2의 환각 위험을 평가했습니다.
- 결과: Llama2 자체의 내부 상태를 사용했을 때보다 성능이 다소 떨어졌습니다.
- 모델 간 유사성으로 인해 어느 정도의 전이 학습이 가능하지만, 가장 효과적인 예측은 모델 자체의 내부 상태를 사용할 때 얻을 수 있었습니다.
- 이는 보편적인 평가보다 모델별 평가의 중요성을 강조합니다.
3. 내부 상태의 특성 공유
- 같은 자연어 생성 작업 내에서는 특성이 공유되지만, 다른 작업 간에는 공유되지 않습니다.
- 질의응답과 번역 작업에서 제로샷 성능을 평가했습니다.
- 개별 작업 내에서의 제로샷 성능은 괜찮았지만, 작업 간 일반화는 상대적으로 약했습니다.
- 질의응답 데이터로 학습한 추정기를 ANAH라는 외부 데이터셋에 적용했을 때, F1 점수 78.56%, 정확도 78.83%의 비교적 높은 성능을 보였습니다.
- 이는 내부 상태 추정기가 환각 문제를 다루는 데 효과적이며, 같은 작업 내에서 일반화 능력이 있음을 보여줍니다.

1. 내부 상태를 이용한 효율적인 환각 추정기
- 연구진의 추정기는 세 개의 선형 층으로 구성되어 최소한의 컴퓨팅 파워만 필요합니다.
- 성능 비교:
* 연구진의 내부 상태 기반 방법: 샘플당 0.05초 소요
* 가능성 기반 방법: 샘플당 1.36초 소요
* 텍스트 생성 시간(최대 50 토큰, 배치 크기 1): 3.37초
* Questeval(다른 평가 방법): 총 10.25초 소요 (가장 오래 걸림)
- 이러한 빠른 추론 속도는 실제 응용에 매우 중요합니다.
2. 환각 발생률
- 3.2절에서 언급한 라벨링 과정을 통해 각 작업에서의 환각 발생률을 얻었습니다.
- 자연어 생성 작업에 따라 환각 발생률이 크게 달랐습니다.
- 가장 높은 환각 발생률을 보인 작업: 제목 생성
* 이유: 다양한 답변이 가능하고 표준화된 답이 없기 때문
- 가장 낮은 환각 발생률을 보인 작업: 숫자 변환
* 이유: 비교적 쉬운 작업이며 답이 정해져 있어 환각의 여지가 적음


1. 연구 방법
- Grad-CAM(Gradient-weighted Class Activation Mapping) 기술에서 영감을 받아 분석했습니다.
- LLM과 추정기의 공동 작업에서 각 토큰과 관련된 입력 임베딩의 평균 기울기를 계산했습니다.
- 이를 통해 각 토큰이 LLM의 내부 상태와 환각 추정에 미치는 영향을 분석했습니다.
2. 주요 발견
- 알려지지 않은 질문 내의 토큰들이 환각 발생에 균등하지 않게 기여합니다.
- 특히 다음과 같은 토큰들이 환각 추정에 더 큰 영향을 미칩니다:
* 익숙하지 않은 고유 명사
* 중요한 정보를 담고 있는 토큰
3. 구체적인 예시
- 질의응답(QA) 작업에서 "amniotes"라는 단어
- 번역 작업에서 "麻雀"(마작)이라는 단어
- 이러한 토큰들이 더 높은 기울기 값을 가지며, 환각 추정에 큰 영향을 미쳤습니다.
4. 해석
- 시스템이 이해하지 못하거나 지식이 부족한 엔티티에 대해 유창한 응답을 생성하려는 시도 때문에 이런 현상이 발생할 수 있습니다.
- 즉, LLM이 잘 모르는 단어나 개념에 대해 그럴듯한 답변을 만들어내려고 할 때 환각이 발생할 가능성이 높아집니다.

1. 오류 분석의 필요성
- 연구진의 방법이 기준 방법들보다 더 나은 성능을 보였지만, 여전히 일부 실패 사례가 있었습니다.
- 이러한 실패 사례를 분석하여 모델에 대한 더 깊은 이해를 얻고자 했습니다.
2. 실패 사례 예시
a) 잘못된 낙관 예측:
- 질문: "콜라겐 단백질을 포함하는 강하고 유연한 결합 조직을 무엇이라고 하나요?"
- 추정기 예측: LLM이 정확하게 답변할 수 있다고 예측
- 실제 결과: LLM이 "인대(ligaments)"라고 잘못 답변 (정답은 "연골(cartilage)")
- 이 경우 추정기가 LLM의 환각을 예측하지 못했습니다.
b) 잘못된 비관 예측:
- 질문: "적절한 별명이 있는 태평양 지역은 어디인가요?"
- 추정기 예측: LLM이 환각을 일으킬 것이라고 예측
- 실제 결과: LLM이 환각 없이 정확하게 답변
- 이 경우 추정기가 LLM의 정확한 답변 능력을 과소평가했습니다.
3. 추가 분석
- 부록 B에서 더 자세한 분석 내용을 제공합니다.
- 여기에는 다음과 같은 내용이 포함됩니다:
* 개별 메트릭을 연속적인 회귀 라벨로 취급하는 방법
* 다양한 추정기 백본(구조)의 성능 비교
6 Related Work
지식 경계에 대한 연구
- 목적: LLM이 무엇을 알고 있고 어디까지 능력이 있는지 파악하는 것
- 현재 연구 동향: 주로 특정 작업에 초점을 맞춰 조사함
- 예시 (질의응답 분야):
* Rajpurkar 등과 Yin 등: 알려진 질문과 알려지지 않은 질문을 구분하는 분류기 개발
* 이 접근은 모델과 무관한 보편적인 개념(예: 철학적 질문, 미해결 미스터리)에 초점
- Kadavath 등: 특정 모델이 어떤 질문에 정확히 답할 수 있는지 예측하는 모델별 접근
- 도메인 외 또는 분포 외 탐지 연구: 주로 분류 작업에 초점
환각 탐지 연구
- 다양한 탐지 방법이 개발됨
- 내부 상태를 활용한 방법들:
* Azaria와 Mitchell: 인공적으로 만든 참/거짓 문장 데이터셋으로 LLM 내부 상태의 진실성 평가 능력 확인
* Chen 등의 INSIDE: 내부 상태를 이용해 응답의 자기 일관성을 평가하는 EigenScore 제안
* Su 등의 MIND: 비지도 학습으로 위키피디아 원문과 환각된 텍스트를 구분
- Xiao와 Wang: 높은 불확실성이 높은 환각 확률과 연관됨을 보임
- 불확실성 추정 방법들: 자연어 출력의 신뢰성 예측에 활용
본 연구의 차별점
- 기존 연구: 주로 측정 대상 텍스트의 내부 상태를 활용 (텍스트가 같은 LLM에서 나오지 않아도 됨)
- 본 연구: 질문에 대한 LLM의 자기 인식에 초점을 맞춤
- 다양한 자연어 생성 작업에 적용 가능하며, LLM의 미세 조정이 필요 없음
7 Conclusion
해당 연구는 인간의 자기 인식 능력에서 영감을 받아 시작되었습니다. LLM이 답변을 생성하기 전에 자체적으로 환각 위험을 평가할 수 있는 잠재력을 보여주고자 했습니다.
연구 방법은 다음과 같습니다.
- LLM의 내부 상태를 종합적으로 분석했습니다.
- 15개의 자연어 생성 작업, 700개 이상의 데이터셋을 대상으로 했습니다.
- 프로빙 추정기를 사용하여 LLM의 자기 인식 능력을 평가했습니다.
3. 주요 결과는 다음과 같습니다.
a) 학습 데이터에서 질문을 본 적이 있는지 인식: 정확도 80.28%
b) 질문에 대해 환각을 일으킬 가능성 인식: 평균 정확도 84.32%
- 내부 상태 기반 자체 평가가 기존의 복잡도(PPL) 기반, 프롬프트 기반 방법보다 우수한 성능을 보였습니다.
추가 발견으로는,
- 특정 뉴런들이 불확실성과 환각 인식에 중요한 역할을 합니다.
- LLM의 활성화 층의 깊이가 깊을수록 예측 정확도가 높아지는 경향이 있습니다.
- 다른 모델 간에도 내부 상태의 일관성이 있어 제로샷 전이 학습의 가능성이 있지만, 모델별 추정이 가장 효과적입니다.
- 같은 자연어 생성 작업 내에서는 일반화가 잘 되지만, 다른 작업 간에는 일반화가 어려운 점이 관찰되었습니다.
5. 향후 연구 방향
- 다양한 자연어 생성 작업에서 환각 위험 평가의 견고성과 일반화 능력을 향상시키고자 합니다.
- 더 다양한 LLM을 연구에 포함시켜 연구 결과의 적용 범위를 넓히고자 합니다.




댓글