논문 원문: https://arxiv.org/pdf/2306.02592
ABSTRACT
대규모 텍스트 말뭉치에 대한 모델 사전 학습이 NLP 분야의 다양한 하위 응용 프로그램에 효과적임이 입증되었습니다. 그래프 마이닝 분야에서도 유사한 유추를 통해 대규모 그래프에서 그래프 모델을 사전 학습하여 하위 그래프 응용 프로그램에 도움이 되기를 기대할 수 있으며, 이는 최근 여러 연구에서도 탐구되었습니다. 그러나 풍부한 텍스트 정보를 가진 대규모 이종 그래프(일명 대규모 그래프 말뭉치)에서 텍스트와 그래프 모델을 함께 사전 학습한 후, 서로 다른 그래프 스키마를 가진 다양한 관련 하위 응용 프로그램에 대해 모델을 미세 조정하는 연구는 아직 없었습니다. 이 문제를 해결하기 위해, 우리는 대규모 그래프 말뭉치에 대한 그래프 인식 언어 모델 사전 학습(GaLM) 프레임워크를 제안합니다. 이 프레임워크는 대규모 언어 모델과 그래프 신경망을 통합하고, 하위 응용 프로그램에 대한 다양한 미세 조정 방법을 포함합니다. 이 논문에서는 아마존의 실제 내부 데이터셋과 대규모 공개 데이터셋에 대해 광범위한 실험을 수행했습니다. 포괄적인 실험 결과와 심층 분석을 통해 제안한 방법의 효과성과 함께 얻은 교훈들을 입증합니다.
1 INTRODUCTION
1. 배경
- 자연어 처리(NLP) 분야에서는 대규모 텍스트 데이터로 언어 모델을 사전 학습한 후, 특정 작업에 맞게 미세 조정하는 방식이 매우 성공적이었습니다.
- 이 방법으로 GPT, BERT 등 다양한 강력한 언어 모델이 개발되었습니다.
2. 기업의 필요성
- 많은 기업들은 자체적인 데이터를 가지고 있고, 다양한 응용 프로그램을 목표로 합니다.
- 따라서 일반적인 언어 모델보다는 기업 특화된 모델이 더 유용할 수 있습니다.
3. 그래프 데이터의 중요성
- 텍스트 외에도 그래프 구조의 데이터가 산업에서 많이 사용되고 있습니다.
- 예를 들어, 추천 시스템에서 사용자와 상품을 노드로, 구매나 좋아요 등을 엣지로 표현할 수 있습니다.
4. 현실 세계의 시나리오
- 기업들은 보통 도메인 특화된 대규모 그래프 데이터(그래프 말뭉치)를 보유하고 있습니다.
- 이 그래프에는 풍부한 텍스트 정보가 노드의 특성으로 포함되어 있습니다.
- 다른 부서들은 각자의 목적에 맞는 특정 그래프 데이터를 수집합니다.
5. 연구의 동기
- 대규모 그래프 말뭉치를 활용해 다양한 응용 프로그램의 성능을 향상시키는 방법이 필요합니다.
- 기존 연구들은 주로 동일한 그래프에서의 사전 학습과 미세 조정에 초점을 맞추었습니다.
6. 연구의 주요 내용
- 대규모 그래프 말뭉치에서 강력한 모델을 학습하는 방법
- 학습된 모델을 다양한 하위 응용 프로그램에 전이하는 방법
7. 주요 기여
- GaLM(Graph-aware Language Model) 프레임워크 제안
- 다양한 미세 조정 방법 제안
- 아마존 내부 데이터셋과 공개 데이터셋을 이용한 광범위한 실험
- 실험 결과에 대한 통찰과 교훈 제공
2 RELATED WORKS
2.1 Language Modeling with Graphs
최근 그래프를 이용한 학습이 큰 주목을 받고 있습니다. 이는 노드의 특성과 그래프 구조 정보를 함께 활용해 실제 세계의 응용 프로그램을 더 잘 모델링할 수 있기 때문입니다. 특히 언어 모델링 분야에서는 순수한 의미 정보만 사용하는 것의 한계를 극복하기 위해 그래프 구조를 도입하고 있습니다. 예를 들어, 실제 사용자 행동이나 지식 그래프, 문맥 등의 의미적 연결을 모델링하는 데 그래프를 활용합니다.
이를 위해 많은 연구에서 그래프 신경망(GNN)을 사용하여 그래프 구조를 따라 정보를 전파하고 집계합니다. 언어 모델과 GNN을 결합하는 방식은 다양한데, 언어 모델을 정적 텍스트 인코더로 사용하고 GNN을 그 위에 쌓는 방식, 언어 모델을 미세 조정한 후 고정된 노드 특성을 생성하여 GNN의 입력으로 사용하는 방식, 또는 언어 모델과 GNN의 파라미터를 함께 학습하는 방식 등이 있습니다.
본 연구는 이러한 기존 방식들을 종합하고 발전시켜, 더 유연하고 강력한 모델을 만들고자 합니다. 특정 응용 프로그램이나 그래프 구조에 국한되지 않는 일반적인 접근 방식을 제안하며, 대규모 그래프 말뭉치에서 그래프 정보를 포함한 언어 모델 사전 학습에 초점을 맞춥니다. 더 나아가, 사전 학습된 모델을 다양한 응용 프로그램에 미세 조정하는 방법을 제안하는데, 이때 응용 프로그램의 그래프 구조가 사전 학습에 사용된 그래프와 다를 수 있다는 점이 중요합니다. 이러한 접근 방식은 기업이나 연구 기관에서 실제로 활용도가 높을 것으로 기대됩니다.
2.2 Pre-training on Graphs
그래프를 이용한 사전 학습에 관한 많은 연구들이 있었습니다. 초기에는 주로 분자 도메인에서 많은 작은 그래프들을 사용해 그래프 수준의 정보를 인코딩하는 데 초점을 맞추었습니다. 최근에는 대규모 그래프에서의 사전 학습에 관심이 모아지고 있습니다. 이는 레이블 부족 문제를 해결하거나, 사전 학습 작업과 실제 응용 작업 사이의 최적화 목표 차이를 줄이거나, 다른 응용 그래프에 전이 가능한 정보를 포착하기 위함입니다.
우리의 연구는 마지막 카테고리에 가깝습니다. 그래프 간 전이 학습에 관한 기존 연구들은 다양한 접근 방식을 제안했습니다. 예를 들어, GNN의 전이 가능성에 대한 이론적 분석, 사전 학습 중 미세 조정을 학습하는 전략, 대조 학습을 사용한 범용 GNN 모델 등이 있습니다. 그러나 이런 연구들은 대부분 동종 그래프에 초점을 맞추고 있습니다.
이종 그래프에 대한 연구도 있었지만, 대부분 사전 학습 그래프와 동일한 그래프 스키마를 가진 그래프로의 전이에 집중했습니다. 반면, 우리의 연구에서는 응용 그래프가 사전 학습 그래프와 다른 새로운 엣지 유형을 가질 수 있다고 가정합니다. 이는 적용 가능한 하위 작업의 범위를 넓히고, 새로운 엣지 유형을 통해 응용 프로그램에 특정 기능을 도입할 수 있게 합니다.
또한, 기존 연구들은 대부분 원시 텍스트와 그래프 토폴로지 사이의 관계를 고려하지 않고, 그래프와 무관한 방식으로 생성된 노드 특성을 사용했습니다. 우리의 연구는 그래프와 GNN을 활용하여 대규모 그래프 말뭉치에서 언어 모델의 정보 포착 능력을 향상시키는 데 중점을 둡니다. 이러한 접근 방식은 텍스트와 그래프 구조 간의 상호작용을 더 잘 모델링할 수 있게 해주며, 결과적으로 더 강력하고 유연한 모델을 만들 수 있게 합니다.
3 PRELIMINARIES
3.1 Problem Formulation
이 연구에서는 대규모 이종 그래프(큰 그래프 말뭉치)와 여러 개의 하위 응용 이종 그래프를 다룹니다. 목표는 큰 그래프 말뭉치를 활용하여 각 응용 그래프에서의 작업 성능을 향상시키는 것입니다.
큰 그래프 말뭉치와 응용 그래프는 노드, 엣지, 노드 유형, 엣지 유형 등으로 구성됩니다. 중요한 점은 큰 그래프 말뭉치의 노드 수가 응용 그래프보다 훨씬 많고, 응용 그래프의 노드 대부분이 큰 그래프 말뭉치에 포함된다는 것입니다. 또한, 응용 그래프의 노드 유형은 큰 그래프 말뭉치의 노드 유형의 부분집합이지만, 엣지 유형은 서로 다를 수 있습니다.
이 모델은 언어 모델(LM)과 다중 관계 그래프 신경망(GNN)으로 구성됩니다. 먼저, 큰 그래프 말뭉치에서 비지도 학습을 통해 모델을 사전 학습합니다. 이때 경험적 손실을 최소화하는 최적의 모델 매개변수를 찾습니다.
특정 상황에서는 다른 유형의 노드를 모델링하기 위해 여러 개의 언어 모델을 사용할 수 있습니다. 예를 들어, 전자상거래 데이터에서 쿼리와 제품 엔터티를 모델링하기 위해 별도의 언어 모델을 사용합니다.
사전 학습된 모델은 여러 응용 그래프의 다양한 작업에 미세 조정됩니다. 각 응용 그래프에 대해, 사전 학습된 모델의 매개변수로 초기화한 후 해당 그래프의 경험적 손실을 최소화하도록 미세 조정합니다.
이러한 접근 방식은 대규모 그래프의 풍부한 정보를 활용하여 더 작은 응용 그래프에서의 성능을 향상시키는 것을 목표로 합니다. 특히 텍스트 정보와 그래프 구조를 동시에 고려함으로써, 더 강력하고 유연한 모델을 만들 수 있습니다.
3.2 The Large Graph Corpus
이 연구에서 소개하는 '대규모 그래프 말뭉치'는 새롭고 중요한 개념입니다. 이는 노드가 텍스트 정보를 가지고 있고, 같은 노드 쌍 사이에 여러 유형의 엣지가 존재할 수 있는 이종 그래프입니다.
예를 들어, 쇼핑 엔진의 사용자 행동 그래프를 생각해볼 수 있습니다. 이 그래프에는 '쿼리'(사용자 입력)와 '제품' 노드가 있고, 이들 사이에 '추가', '클릭', '좋아요', '구매' 등의 관계(엣지)가 존재합니다. 이 외에도 다양한 노드 유형 간의 관계나 같은 노드 유형 내의 관계도 포함될 수 있습니다.
대규모 그래프 말뭉치에서의 사전 학습이 도움이 될 수 있는 하위 응용 프로그램은 그래프 말뭉치의 노드 및 관계 유형과 연관됩니다. 노드 스키마 측면에서, 응용 프로그램에 필요한 노드 유형이 그래프 말뭉치의 노드 유형의 부분집합이면 됩니다. 관계 유형 측면에서는 더 유연한데, 응용 프로그램의 관계 유형이 반드시 그래프 말뭉치의 부분집합일 필요는 없습니다. 그래프 말뭉치의 관계를 통해 수집된 정보가 응용 프로그램에 유용하다면, 사전 학습이 도움이 될 수 있습니다.
그래프 말뭉치의 노드는 복잡한 텍스트 정보를 포함하고 있어, 이를 인코딩하기 위해 대규모 언어 모델을 사용합니다. 이렇게 그래프 말뭉치에서 풍부한 관계 정보와 함께 사전 학습된 언어 모델은 다양한 하위 응용 프로그램과 작업에 일반화되어 적용될 수 있을 것으로 기대됩니다.
이 접근 방식은 텍스트 데이터와 그래프 구조를 동시에 활용하여, 더 강력하고 유연한 모델을 만들 수 있게 해줍니다. 이는 다양한 실제 응용 분야에서 큰 잠재력을 가지고 있습니다.
3.3 Multiple Applications
이 연구에서는 대규모 그래프 말뭉치에서의 사전 학습이 다양한 하위 응용 프로그램에 어떻게 도움이 되는지 조사하기 위해 여러 응용 프로그램을 사용합니다.
일반적으로 응용 프로그램은 적은 수의 관계 유형(예: 1-2개)을 가지며, 이 관계 유형들은 대규모 그래프 말뭉치의 관계 유형과 다를 수 있습니다.
연구를 위해 Amazon-PQ라는 데이터셋 그룹을 만들었습니다. 이는 사전 학습을 위한 대규모 그래프 말뭉치와 세 가지 실제 응용 프로그램(Search-CTR, ESCvsI, Query2PT)으로 구성됩니다.
1. Search-CTR: 사용자/쿼리가 광고된 제품을 클릭할지 예측하는 링크 예측 작업입니다. "제품"과 "쿼리" 노드 유형, 그리고 "광고 클릭" 엣지 유형을 포함합니다.
2. ESCvsI: 쿼리-제품 매칭 문제를 다루는 응용 프로그램입니다. "쿼리"와 "제품" 노드 유형, 그리고 "매치" 엣지 유형을 포함합니다. 이 작업은 쿼리-제품 쌍을 연결하는 엣지를 E/S/C와 I 두 클래스로 분류하는 엣지 분류 작업입니다.
3. Query2PT: 쿼리에 매핑되는 제품 유형을 예측하는 응용 프로그램입니다. "클릭" 엣지 유형과 "쿼리", "제품" 노드 유형을 포함합니다. 이 작업은 "쿼리" 노드를 여러 레이블(403개 클래스 중)로 분류하는 다중 레이블 노드 분류 작업입니다.
연구에 사용된 데이터는 원래의 Amazon 내부 데이터셋에서 전략적으로 샘플링되어 집계 및 익명화되었으며, 실제 제품 트래픽을 대표하지는 않습니다.
이 연구는 다양한 실제 응용 프로그램을 통해 대규모 그래프 말뭉치에서의 사전 학습이 어떻게 다른 작업들에 도움이 되는지 살펴보고 있습니다. 이를 통해 제안된 방법의 실용성과 유연성을 검증하고자 합니다.
4 LM+GNN: THE BACKBONE OF OUR PROPOSED FRAMEWORK

이 연구에서 제안하는 그래프 말뭉치 학습을 위한 기본 모델은 LM+GNN이라고 불립니다. 이 모델은 텍스트 정보를 인코딩하는 하나 이상의 언어 모델(LM)과 정보를 집계하는 그래프 신경망(GNN) 집계기로 구성됩니다.
LM+GNN의 작동 과정은 다음과 같습니다. 먼저 그래프 말뭉치가 입력으로 주어지면, 하나 또는 여러 개의 언어 모델이 노드의 텍스트 정보를 인코딩합니다. 이렇게 생성된 임베딩은 그래프 구조에 부착되어 GNN 집계기의 입력으로 사용됩니다. 마지막으로, GNN 집계기의 출력은 특정 작업에 맞는 디코더를 통과하여 최종 결과를 얻습니다.
이 연구에서는 언어 모델로 BERT를 사용했습니다. BERT는 많은 관련 연구에서 잘 연구되었고 산업에서 널리 사용되고 있기 때문입니다. GNN 집계기는 다양한 GNN 변형을 사용할 수 있는데, 이 연구에서는 여러 관계 유형을 가진 그래프를 다루기 위해 RGCN과 RGAT라는 두 가지 관계형 GNN을 사용했습니다.
RGCN의 정보 전파 규칙은 복잡한 수학적 표현을 가지고 있지만, 간단히 말하면 노드의 표현을 업데이트할 때 이웃 노드들의 정보를 관계 유형에 따라 다르게 가중치를 부여하여 합산하는 방식입니다. RGAT는 여기에 주의 메커니즘을 추가하여 이웃 정보를 집계할 때 더 중요한 이웃에 더 높은 가중치를 부여합니다.
기본적인 LM+GNN 모델에서는 언어 모델과 GNN 집계기가 단순히 쌓여있어, 텍스트 정보 인코딩과 이웃 정보 집계 과정이 분리되어 있습니다. 이 모델은 텍스트 정보와 그래프 구조 정보를 모두 활용하여 다양한 그래프 기반 작업을 수행할 수 있게 해줍니다.
이러한 접근 방식은 텍스트 데이터와 그래프 구조를 동시에 고려함으로써, 더 풍부하고 정확한 정보를 추출할 수 있게 해줍니다. 이는 실제 세계의 복잡한 관계를 모델링하는 데 매우 유용할 수 있습니다.
5 GRAPH-AWARE LM PRE-TRAINING ON A LARGE GRAPH CORPUS

이 연구에서 제안하는 대규모 그래프 말뭉치에서의 사전 학습은 다양한 하위 응용 프로그램에 도움이 될 수 있는 정보를 최대한 많이 포착하는 것을 목표로 합니다.
언어 모델(LM)은 텍스트 정보를 잘 이해할 수 있는 많은 매개변수를 가지고 있고, 그래프 구조는 정보 전파에 의미 있는 엔티티 간의 상관관계를 보존합니다. 이 두 가지의 장점을 결합하기 위해 연구팀은 그래프 인식 언어 모델 사전 학습 프레임워크(GaLM)를 제안합니다.
GaLM을 대규모 그래프 말뭉치에서 사전 학습하면, 일반 텍스트로 사전 학습된 기존의 언어 모델(예: BERT)에 그래프 정보를 통합할 수 있습니다. 이 과정은 기술적으로는 기존 사전 학습된 언어 모델을 대규모 그래프 말뭉치에서 미세 조정하는 것이지만, 전체 프레임워크의 관점에서 이를 '그래프 인식 언어 모델 사전 학습'이라고 정의합니다.
이 접근 방식의 장점은 텍스트 데이터와 그래프 구조 정보를 동시에 활용할 수 있다는 것입니다. 이를 통해 모델은 텍스트의 의미뿐만 아니라 엔티티 간의 복잡한 관계도 이해할 수 있게 됩니다.
결과적으로 GaLM은 텍스트 이해와 관계 분석을 결합한 더 강력하고 유연한 모델을 만들어냅니다. 이는 추천 시스템, 지식 그래프 구축, 소셜 네트워크 분석 등 다양한 실제 응용 분야에서 큰 잠재력을 가지고 있습니다.
5.1 Graph-aware LM Pre-training
그래프 인식 언어 모델 사전 학습(GaLM)은 대규모 그래프 말뭉치에서 언어 모델을 사전 학습하면서 그래프 정보를 모델에 통합하는 것을 목표로 합니다.
GaLM의 작동 과정은 다음과 같습니다:
1. 대규모 그래프 말뭉치의 텍스트 정보를 일반적인 사전 학습된 언어 모델로 인코딩합니다.
2. 전자상거래 시나리오에서는 보통 쿼리와 제품 엔터티에 대해 별도의 언어 모델을 사용합니다.
3. 언어 모델의 출력 임베딩은 그래프 구조와 연결되어 특정 그래프 작업을 위한 디코더의 입력으로 사용됩니다.
4. 전체 과정은 그래프 작업에 의해 감독되며, 손실 함수를 계산합니다.
이 연구에서는 링크 예측이라는 비지도 학습 작업을 사전 학습에 사용합니다. 이 과정에서 계산된 손실은 언어 모델의 매개변수를 미세 조정하는 데 사용됩니다.
연구팀은 GaLM의 효과를 검증하기 위해 두 가지 기준 모델(LM(Bert-base)와 LM(Bert-mlm))과 비교했습니다. 실험 결과, GaLM이 다양한 응용 프로그램에서 상당한 성능 향상을 보였습니다. 이는 대규모 그래프 말뭉치에서의 그래프 인식 언어 모델 사전 학습이 하위 응용 프로그램에 유용한 정보를 포착할 수 있음을 보여줍니다.
이 연구의 핵심은 그래프 인식 언어 모델 사전 학습이 어떻게 여러 응용 프로그램에 도움이 되는지에 초점을 맞추고 있다는 점입니다. 이는 기존 연구들과 구별되는 중요한 특징입니다.
이러한 접근 방식은 텍스트 데이터와 그래프 구조를 동시에 고려함으로써, 더 풍부하고 정확한 정보를 추출할 수 있게 해줍니다. 이는 추천 시스템, 지식 그래프 구축, 소셜 네트워크 분석 등 다양한 실제 응용 분야에서 큰 잠재력을 가지고 있습니다.
5.2 GNN-based Graph-aware LM Pre-trainin

이 연구에서는 언어 모델(LM)에 그래프 정보를 통합하는 또 다른 방법으로 LM과 그래프 신경망(GNN) 집계기를 함께 훈련하는 방식을 제안합니다. 이를 GaLMco라고 부릅니다.
GaLMco의 훈련 과정은 다음과 같습니다.
1. 먼저 그래프 인식 감독을 통해 일반적인 LM을 대규모 그래프 말뭉치에서 미세 조정합니다.
2. GNN 집계기를 예열(warm up)하여 공동 훈련이 바람직하지 않은 지역 최솟값에 빠지는 것을 방지합니다.
3. 마지막으로, 예열된 GNN 집계기와 함께 사전 훈련된 LM을 공동 훈련합니다.
이 방법은 LM과 GNN을 end-to-end로 훈련시키는데, 이는 매우 시간이 많이 걸릴 수 있습니다. 따라서 연구팀은 공동 훈련 과정에서 일부 샘플에 대해서만 역전파를 수행하여 훈련 속도를 높였습니다.
연구팀은 GaLMco의 효과를 검증하기 위해 두 가지 유형의 GNN 집계기(RGCN과 RGAT)를 사용하여 실험을 진행했습니다. 그 결과를 기본 GaLM과 비교했을 때, GaLMco는 일부 응용 프로그램에서 약간의 성능 향상을 보였지만, 전반적으로는 기본 GaLM과 비슷한 성능을 보였습니다.
그러나 GaLMco는 기본 GaLM보다 훈련 시간이 더 오래 걸립니다. 따라서 연구팀은 계산 자원과 시간의 제약을 고려할 때, 대규모 그래프 말뭉치에서의 사전 학습에는 GNN 기반 방법보다는 기본 그래프 인식 LM 사전 학습 방법을 선택하는 것이 더 합리적이라고 결론지었습니다.
이 연구는 텍스트 데이터와 그래프 구조를 효과적으로 결합하는 방법을 탐구하면서도, 실용성과 효율성을 고려하여 최적의 접근 방식을 찾아내고 있습니다. 이는 복잡한 실제 세계의 문제를 해결하는 데 있어 중요한 균형을 보여줍니다.
6 GALM FINE-TUNING ON MULTIPLE GRAPH APPLICATIONS

이 연구에서는 GaLM(그래프 인식 언어 모델)의 효과를 입증한 후, 다양한 응용 프로그램에서 GaLM의 성능을 더욱 향상시키기 위한 미세 조정 방법들을 탐구합니다.
GaLM의 구조는 다음과 같은 요소로 구성되어 있습니다:
1. 노드 유형별 언어 모델(LM)
2. 선택적인 관계 유형별 그래프 신경망(GNN) 집계기
3. 작업별 디코더
따라서 GaLM의 미세 조정은 이 요소들을 다양하게 조정하는 것을 포함합니다. 연구팀이 제안하는 미세 조정 방법들은 다음과 같습니다:
1. 응용 프로그램에 대해 GaLM의 사전 훈련된 언어 모델을 그래프 인식 방식으로 미세 조정합니다.
2. GaLM(또는 미세 조정된 GaLM)에 GNN 집계기를 추가하여 응용 프로그램에 대해 훈련합니다.
3. 응용 프로그램의 그래프를 대규모 그래프와 연결(stitching)하고, 이 연결된 그래프에서 GNN 집계기를 훈련합니다.
4. GaLM의 GNN 집계기를 연결된 응용 프로그램 그래프에서 미세 조정합니다.
이러한 다양한 미세 조정 전략들은 GaLM이 다양한 그래프 기반 응용 프로그램에 더 잘 적응할 수 있게 해줍니다. 각 전략은 응용 프로그램의 특성과 요구 사항에 따라 선택될 수 있으며, 이를 통해 모델의 성능을 최적화할 수 있습니다.
이 접근 방식은 모델의 유연성을 높이고, 다양한 실제 상황에 더 잘 대응할 수 있게 해줍니다. 또한, 대규모 사전 학습 모델의 지식을 효과적으로 특정 작업에 전이하는 방법을 보여주고 있습니다.
6.1 Fine-tuning GaLM on Applications

1. GaLM의 미세 조정 방법:
a) GaLM의 언어 모델(LM)을 그래프 응용 프로그램에서 추가로 미세 조정
b) GaLM의 LM을 사용하여 응용 프로그램 그래프에서 새로운 GNN 집계기 훈련
2. 그래프 인식 LM 미세 조정:
- GaLM의 사전 훈련된 LM을 사용해 응용 프로그램의 텍스트를 인코딩
- 특정 그래프 작업(예: 노드 분류, 엣지 분류)에 따라 손실 함수 계산
- 결과: GaLM*라고 불리는 미세 조정된 모델이 일부 응용 프로그램에서 성능 향상
3. GNN과 함께 GaLM 미세 조정:
- GaLM*의 LM을 사용하여 노드 임베딩 생성
- 이 임베딩을 입력으로 사용하여 GNN 집계기와 작업별 디코더 훈련
- RGCN과 RGAT를 사용한 실험 결과, GaLM*보다 큰 성능 향상 확인
4. 주요 발견:
- 대규모 그래프 말뭉치에서의 사전 학습이 다양한 응용 프로그램에 도움이 됨
- 응용 프로그램별 미세 조정이 추가적인 성능 향상을 가져올 수 있음
- GNN 집계기를 추가하면 더 큰 성능 향상을 얻을 수 있음
5. 결론:
- 그래프 인식 LM 미세 조정은 특히 사전 학습 작업과 다른 응용 프로그램에서 효과적
- GNN과 함께 GaLM을 미세 조정하는 것이 대부분의 응용 프로그램에서 가장 좋은 성능을 보임
이 연구는 대규모 그래프 말뭉치에서 사전 학습된 모델을 다양한 그래프 기반 응용 프로그램에 효과적으로 적용하는 방법을 보여주고 있습니다. 특히, 텍스트 정보와 그래프 구조를 함께 활용하는 방식이 다양한 작업에서 성능 향상을 가져올 수 있음을 입증하고 있습니다.
6.2 Fine-tuning GaLM on Applications Stitched with the Large Graph Corpus
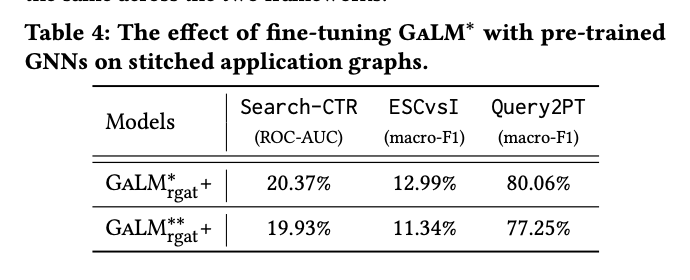
1. 응용 프로그램 그래프와 대규모 그래프 연결(stitching):
- 응용 프로그램 그래프에 대규모 그래프의 추가 정보를 포함시키는 방법
- 중복되는 노드를 기준으로 두 그래프를 연결하고 추가 엣지 정보를 포함
2. 연결된 그래프에서 GNN과 함께 GaLM 미세 조정:
- GaLM*의 LM을 사용해 노드 임베딩 생성
- 연결된 그래프에서 GNN 집계기와 디코더 훈련
- 결과: GaLM*_rgcn+와 GaLM*_rgat+가 기존 모델보다 우수한 성능 보임
3. 사전 학습된 GNN을 이용한 GaLM 미세 조정:
- 대규모 그래프에서 사전 학습된 GNN 집계기를 응용 프로그램에 적용
- 엣지 유형의 불일치 문제를 해결하기 위해 연결된 그래프 사용
- 새로운 엣지 유형을 위한 새 GNN 집계기 초기화 및 훈련
4. 주요 발견:
- 연결된 그래프를 사용하면 더 많은 이웃 정보를 활용할 수 있어 성능 향상
- 모델 수준의 사전 학습만으로는 대규모 그래프의 모든 정보를 포착하기 어려움
- 사전 학습된 GNN의 미세 조정은 복잡한 결정이 필요하지만, 빠른 수렴을 가능하게 함
5. 향후 연구 방향:
- 대규모 그래프의 정보를 더 효과적으로 포착할 수 있는 LM과 사전 학습 방법 개발
- 사전 학습된 GNN 미세 조정을 위한 최적의 학습률, 초기화 방법, 출력 집계 방법 탐구
이 연구는 텍스트 정보와 그래프 구조를 결합하여 다양한 그래프 기반 응용 프로그램의 성능을 향상시키는 방법을 탐구하고 있습니다. 특히, 대규모 그래프의 풍부한 정보를 효과적으로 활용하는 방법에 대한 중요한 통찰을 제공하고 있습니다.
7 EXTERNAL AND OVERALL EVALUATIONS
7.1 Public Data Source
1. 데이터셋 소개:
- Amazon Product Reviews 공개 데이터셋 사용 (1996년 5월부터 2014년 7월까지)
- 'Product-Reviews'라고 명명한 이 데이터셋으로 대규모 그래프 말뭉치와 응용 프로그램 그래프 시뮬레이션
2. 데이터 처리:
- 아이템 텍스트: 'title', 'brand', 'feature', 'description' 필드 결합
- 리뷰 텍스트: 'reviewText' 필드 사용
- 'categories' 필드: 제품 유형 예측 작업에 사용
3. 데이터 분할:
- 노드 스키마: "asin"(제품 ID), "reviewText"
- 대규모 그래프 말뭉치의 엣지 스키마:
* "asin–coview–asin" (함께 본 제품)
* "reviewText–review–asin" (리뷰와 제품 연결)
* "reviewText–cowrite–reviewText" (같은 리뷰어가 작성한 리뷰)
4. 응용 프로그램 그래프:
- CoPurchase: 두 제품의 동시 구매 예측 (링크 예측 작업)
- Product2PT: 제품 유형 예측 (노드 분류 작업)
- 새로운 엣지 유형: "asin–cobuy–asin" (함께 구매한 제품)
5. 그래프 다운샘플링:
- 전체 그래프 구성 후 다운샘플링 수행
- 랜덤 노드 선택 후 이웃 노드 샘플링
- 여러 번 반복하여 k-hop 네트워크 생성
- 샘플링된 노드 간의 모든 엣지 포함하여 연결성 유지
이 연구는 실제 세계의 복잡한 데이터를 시뮬레이션하여 제안된 방법의 효과를 검증하고 있습니다. 특히, 대규모 그래프 말뭉치와 응용 프로그램 그래프를 생성하는 방법을 상세히 설명하고 있어, 이러한 접근 방식이 다양한 실제 상황에 적용될 수 있음을 보여주고 있습니다.
7.2 Implementation Details
1. 데이터 처리
- Amazon 내부 데이터셋과 Amazon Product Reviews 공개 데이터셋은 모두 매우 큰 규모입니다.
- 이러한 대규모 데이터의 전처리와 다운샘플링은 분산 Spark 프레임워크를 사용하여 수행되었습니다.
2. 실험 환경
- 실험에는 64개의 Nvidia Tesla V100 32GB GPU로 구성된 클러스터가 사용되었습니다.
3. 하이퍼파라미터 설정
- 모델과 실험에 사용된 하이퍼파라미터 설정은 부록 B.2의 Table 8에 자세히 나와 있습니다.
이 정보는 연구의 실험 설정에 대한 중요한 세부 사항을 제공합니다.
1. 대규모 데이터 처리 능력: Spark를 사용한 분산 처리는 대용량 데이터를 효율적으로 다룰 수 있게 해줍니다.
2. 강력한 컴퓨팅 자원: 64개의 고성능 GPU를 사용한 것은 이 연구가 상당한 계산 능력을 필요로 함을 보여줍니다.
3. 재현 가능성: 하이퍼파라미터 설정을 제공함으로써 다른 연구자들이 이 실험을 재현할 수 있게 합니다.
이러한 정보는 연구의 규모와 복잡성을 이해하는 데 도움이 되며, 실제 산업 환경에서 이러한 모델을 적용할 때 필요한 자원에 대한 통찰을 제공합니다.
7.3 Results on Internal and Public Datasets

1. 실험 개요
- GaLM을 GNN과 함께 미세 조정하는 것이 응용 프로그램의 성능을 크게 향상시킬 수 있음을 확인했습니다.
- GaLMrgat 모델을 기반으로 다양한 미세 조정 방법을 적용하여 Amazon-PQ와 Product-Reviews 데이터셋에서 종합적인 비교를 수행했습니다.
2. 모델 설명
- 기준 모델: 공개된 사전 학습 LM을 사용한 LM+GNN 모델
- GaLMrgat: 대규모 그래프 말뭉치에서 사전 학습된 LM 사용
- GaLM*rgat: GaLM의 LM을 응용 프로그램에서 그래프 인식 방식으로 미세 조정 후 GNN 훈련
- GaLM*rgat+: GaLM*rgat와 유사하지만 연결된(stitched) 응용 프로그램 그래프에서 GNN 훈련
3. 주요 결과
- 대부분의 GaLM 변형 모델이 LM(Bert-base) 변형 모델보다 모든 5개 응용 프로그램에서 훨씬 우수한 성능을 보였습니다.
- GaLM*rgat+가 GaLM*rgat보다 우수한 성능을 보여, 대규모 그래프 말뭉치의 추가 이웃 정보를 데이터 수준에서 도입하는 것이 효과적임을 입증했습니다.
- GaLMrgat와 GaLM*rgat의 성능이 비슷한 것으로 보아, GNN 집계기와 함께 GaLM을 미세 조정할 때 LM을 직접 미세 조정하는 것이 불필요할 수 있음을 시사합니다.
4. 결론
- 대규모 그래프 말뭉치에서의 그래프 인식 LM 사전 학습과 응용 프로그램에서의 미세 조정이 다양한 작업에 유익할 수 있습니다.
- 연결된 응용 프로그램 그래프를 사용하는 것이 모델 수준의 사전 학습만으로는 완전히 포착되지 않는 추가 정보를 제공할 수 있습니다.
- GNN 집계기의 능력이 응용 프로그램 그래프의 핵심 정보를 포착하는 데 충분할 수 있어, LM을 직접 미세 조정하는 것이 큰 추가 이득을 제공하지 않을 수 있습니다.
이 연구는 대규모 그래프 말뭉치를 활용한 사전 학습과 다양한 미세 조정 전략이 그래프 기반 응용 프로그램의 성능을 어떻게 향상시킬 수 있는지에 대한 중요한 통찰을 제공합니다.
7.4 Additional Analysis

1. 유의성 검정
- Product2PT 데이터셋에서 각 모델에 대해 5번 반복 실험을 수행했습니다.
- 모델 쌍 간 단측 T-검정을 실시하여 성능 차이의 유의성을 분석했습니다.
- 대부분의 비교에서 p-값이 0.05 미만으로, 유의미한 차이를 보였습니다.
- 특이점: LM*(Bert-base)+Gnn(rgat)와 GaLMrgat 사이의 p-값이 1.0으로, 유의미한 차이가 없었습니다. 이는 Product2PT 데이터셋의 단순성 때문일 수 있습니다.
2. 제거 연구(Ablation Studies)
- GaLM*rgat+ 모델에서 각 미세 조정 전략을 하나씩 제거하며 성능 변화를 관찰했습니다.
- 주요 발견:
a) LM만 사용할 때는 응용 프로그램에서의 LM 미세 조정이 효과가 있었습니다.
b) GNN 집계기를 도입하면 LM 미세 조정의 효과가 감소했습니다.
c) 미세 조정 단계에서 GNN 집계기를 통합하면 성능이 크게 향상되었습니다.
d) 연결된(stitched) 응용 프로그램 그래프에서 GaLM을 미세 조정하면 더 많은 이웃 정보를 활용할 수 있어 성능이 더욱 향상되었습니다.
3. 결론
- GNN 집계기의 도입이 LM 미세 조정보다 더 큰 성능 향상을 가져왔습니다.
- 연결된 응용 프로그램 그래프를 사용하는 것이 단일 응용 프로그램 그래프만 사용하는 것보다 더 효과적이었습니다.
8 CONCLUSION
1. 연구 목적
- 대규모 그래프 말뭉치를 활용하여 다양한 하위 그래프 응용 프로그램의 성능을 향상시키는 방법을 연구했습니다.
- 이때 응용 프로그램들은 서로 다른 엣지 스키마와 다양한 작업을 가질 수 있습니다.
2. 제안된 방법
- GaLM(그래프 인식 언어 모델 사전 학습) 프레임워크를 제안했습니다.
- 다양한 미세 조정 전략을 포함한 고급 변형 모델들도 제안했습니다.
3. 연구 결과
- 광범위한 실험을 통해 제안된 프레임워크와 미세 조정 방법의 효과성을 입증했습니다.
- 실험 결과에 대한 통찰과 추가 분석을 제공했습니다.
4. 연구의 한계
- BERT 언어 모델만을 실험에 사용했습니다. 이는 현재 산업에서 BERT 기반의 대규모 훈련 파이프라인이 더 발달되어 있기 때문입니다.
5. 향후 연구 방향
- 더 정교한 사전 학습 작업과 언어 모델 설계를 통해 대규모 그래프 말뭉치 정보를 완전히 포착할 수 있는지 연구할 필요가 있습니다.
- 사전 학습된 GNN을 사용하여 GaLM을 미세 조정할 때 발생하는 복잡한 의사 결정 문제를 해결하는 방법을 연구해야 합니다.
'ML & DL > 논문리뷰' 카테고리의 다른 글
| From Local to Global: A Graph RAG Approach to Query-Focused Summarization (2) | 2024.10.06 |
|---|---|
| QWEN2 TECHNICAL REPORT (5) | 2024.09.15 |
| CHAIN-OF-VERIFICATION REDUCES HALLUCINATIONIN LARGE LANGUAGE MODELS (0) | 2024.09.01 |
| FlashAttention-3:Fast and Accurate Attention with Asynchrony and Low-precision (0) | 2024.07.14 |
| Designing a Dashboard forTransparency and Control of Conversational AI (0) | 2024.07.07 |




댓글