논문 원문: https://tridao.me/publications/flash3/flash3.pdf
Abstract
Transformer 아키텍처의 핵심 요소인 "어텐션"에 관한 내용으로, 이는 대규모 언어 모델과 긴 문맥 처리 애플리케이션에서 성능의 병목 현상을 일으킬 수 있습니다. FlashAttention은 GPU에서 어텐션을 가속화하기 위해 메모리 읽기/쓰기를 최소화하는 방법을 제시했지만, 최신 하드웨어의 새로운 기능을 완전히 활용하지 못하고 있습니다. 예를 들어, FlashAttention-2는 H100 GPU에서 35%의 활용도에 그칩니다.
우리는 Hopper GPU에서 어텐션을 가속화하기 위해 세 가지 주요 기술을 개발했습니다:
1. 텐서 코어와 TMA의 비동기성을 활용하여 전체 계산과 데이터 이동을 겹치게 하는 "워프 전문화".
2. 블록 단위의 행렬 곱셈과 소프트맥스 연산을 교차 수행.
3. FP8 저정밀도에 대한 하드웨어 지원을 활용한 블록 양자화와 비동기 처리.
이 방법을 통해 FlashAttention-3는 H100 GPU에서 1.5-2.0배의 속도 향상을 달성하였으며, FP16에서 최대 740 TFLOPs/s(75% 활용도), FP8에서는 거의 1.2 PFLOPs/s에 도달했습니다. 또한 FP8 FlashAttention-3는 기본 FP8 어텐션보다 2.6배 낮은 수치적 오류를 기록했습니다.
1 Introduction
Transformer 아키텍처에서 어텐션 메커니즘이 주요 계산 병목 현상임을 설명하고 있습니다. 이는 쿼리와 키의 자기-어텐션 점수를 계산하는 데 있어 시퀀스 길이에 따라 계산 복잡도가 제곱으로 증가하기 때문입니다. 긴 문맥으로 어텐션을 확장하면 여러 장문의 문서와 파일, 고해상도 이미지, 오디오, 비디오 등을 다룰 수 있는 새로운 능력이 열리게 됩니다. 이는 사용자와의 긴 역사적 상호작용이나 에이전트의 긴 시간대 작업 흐름 등 새로운 애플리케이션에도 적용될 수 있습니다. 이로 인해 어텐션을 빠르게 만들려는 관심이 높아졌고, 이에 대한 다양한 접근 방식이 제안되었습니다. 예를 들어, 근사화나 소프트웨어 최적화, 또는 대체 아키텍처 등이 있습니다.
이 연구에서는 Dao 등[17]의 연구를 바탕으로, GPU의 실행 모델과 하드웨어 특성을 고수준 설계에 통합한 정확한 어텐션 알고리즘을 개발했습니다. Dao 등은 FlashAttention을 도입하여, 병렬로 어텐션을 처리하기 위한 새로운 타일링 전략을 제시했습니다. 이는 모든 어텐션 연산을 단일 GPU 커널로 결합하여 느린 글로벌 메모리로의 중간 읽기/쓰기를 제거했습니다. FlashAttention-2는 시퀀스 길이 차원에서 병렬화를 진행하고, 키와 값 행렬 블록에 대한 내부 루프를 수행함으로써 GPU의 작업 분배를 개선했습니다. 그러나 FlashAttention-2는 최신 GPU에서 최적화된 행렬 곱셈(GEMM) 커널에 비해 낮은 활용도를 보였습니다. 예를 들어, Hopper H100 GPU에서 35% 대 80-90%의 활용도를 기록했습니다. 이는 부분적으로는 구현 수준의 차이 때문이며, Tensor 코어를 대상으로 하는 경우 Ampere 명령어 대신 Hopper-specific 명령어를 사용하지 않았기 때문일 수 있습니다. ThunkerKitten과 cuDNN 9와 같은 연구는 Hopper-specific 명령어와 타일 기반 추상화를 통해 어텐션 계산을 가속화하고 구현을 단순화할 수 있음을 보여주었습니다.
더 근본적으로는, FlashAttention-2 알고리즘이 단순한 동기 모델을 따르며, 설계에서 비동기성과 저정밀도를 명시적으로 사용하지 않습니다. 비동기성은 ML 작업에서 가장 중요한 연산을 가속화하기 위한 하드웨어 전문화의 결과로, 행렬 곱셈을 수행하는 특정 하드웨어 유닛(Tensor 코어)이나 메모리 로딩(Tensor Memory Accelerator – TMA)을 다른 CUDA 코어와 분리하여 논리적, 정수 및 부동 소수점 연산을 수행합니다. FP8과 같은 저정밀도는 FP16과 BF16의 트렌드를 이어가며, 같은 전력과 칩 면적으로 두 배 또는 네 배의 처리량을 얻는 검증된 기술입니다. Hopper의 이러한 기능을 § 2.2에서 검토합니다. 기술적 과제는 FlashAttention-2를 다시 설계하여 이러한 하드웨어 기능을 활용하는 것입니다. 비동기성은 소프트맥스와 행렬 곱셈 간의 계산을 겹치게 해야 하며, 저정밀도는 양자화 오류를 최소화해야 합니다.
이를 위해, 우리는 FlashAttention-3를 제안하며, 성능을 향상시키기 위해 세 가지 새로운 아이디어를 결합했습니다:
1. 생산자-소비자 비동기성: 데이터 이동과 Tensor 코어의 비동기 실행을 활용하기 위해 생산자와 소비자를 별도의 워프로 분리하여 메모리와 명령어 발행 지연 시간을 숨기는 워프 전문화 소프트웨어 파이프라이닝을 정의합니다.
2. 비동기 블록 단위 GEMM 아래 소프트맥스 숨기기: 소프트맥스에 관련된 비교적 낮은 처리량의 비-GEMM 연산(예: 부동 소수점 곱셈-덧셈 및 지수 연산)을 비동기 WGMMA 명령어와 겹치게 합니다. 이를 위해 FlashAttention-2 알고리즘을 재작업하여 소프트맥스와 GEMM 간의 특정 순차적 종속성을 우회합니다. 예를 들어, 알고리즘의 2단계 버전에서는 소프트맥스가 점수 행렬의 한 블록에서 실행되는 동안, WGMMA는 다음 블록을 비동기 프록시로 계산합니다.
3. 하드웨어 가속 저정밀도 GEMM: FP8 Tensor 코어를 대상으로 하는 전진 패스 알고리즘을 수정하여 측정된 TFLOPs/s를 거의 두 배로 늘립니다. 이는 FP32 누산기와 FP8 피연산자 행렬 블록이 메모리에 배열되는 방식의 차이를 연결해야 합니다. 블록 양자화와 비동기 처리를 사용하여 FP8 정밀도로 전환할 때 발생하는 정확도 손실을 완화합니다.
우리는 FlashAttention-3을 H100 SXM5 GPU에서 다양한 매개변수를 통해 벤치마킹하여 다음과 같은 결과를 얻었습니다: (1) FP16은 전진 패스에서 FlashAttention-2 대비 1.5-2.0배의 속도 향상(최대 740 TFLOPs/s)에 도달했으며, 후진 패스에서는 1.5-1.75배 향상되었습니다. (2) FP8은 거의 1.2 PFLOPs/s에 도달했습니다. (3) 긴 시퀀스 길이에서는 FP16이 NVIDIA의 cuDNN 라이브러리의 최첨단 어텐션 구현보다 성능이 우수하고 FP8은 경쟁력이 있습니다. 우리는 또한 FP16 FlashAttention-3가 FlashAttention-2와 동일한 수치적 오류를 제공하며, 소프트맥스 재스케일링과 같은 중간 결과가 FP32로 유지되므로 표준 어텐션 구현보다 더 낫다는 것을 확인했습니다. 더욱이, 블록 양자화와 비동기 처리를 사용하는 FP8 FlashAttention-3는 표준 어텐션보다 2.6배 더 정확합니다.
우리는 FlashAttention-3을 퍼미시브 라이선스로 오픈소스화하며, PyTorch 및 Hugging Face 라이브러리와 통합하여 더 많은 연구자와 개발자가 혜택을 받을 수 있도록 할 계획입니다.
2 Background: Multi-Head Attention and GPU Characteristics
2.1 Multi-Head Attention
다음 텍스트는 어텐션 메커니즘에서 쿼리(Q), 키(K), 값(V) 입력 시퀀스가 각각 \( \mathbb{R}^{N \times d} \) 공간에 속하며, 여기서 \( N \)은 시퀀스 길이, \( d \)는 헤드 차원임을 설명하고 있습니다. 단일 헤드에 대한 어텐션 출력 \( O \)는 다음과 같이 계산됩니다:
\[ S = \alpha QK^T \in \mathbb{R}^{N \times N}, \]
\[ P = \text{softmax}(S) \in \mathbb{R}^{N \times N}, \]
\[ O = PV \in \mathbb{R}^{N \times d} \]
여기서 소프트맥스 함수는 행 단위로 적용되며, 보통 스케일링 팩터 \( \alpha = 1/\sqrt{d} \)로 설정됩니다. 실제로는 지수 함수의 수치적 불안정을 방지하기 위해 \( S \)에서 행 최대값을 빼줍니다. 멀티 헤드 어텐션(MHA)의 경우, 각 헤드는 자체 쿼리, 키 및 값 프로젝션 세트를 가지며, 이 계산은 여러 헤드와 배치에 걸쳐 병렬로 수행되어 전체 출력 텐서를 생성합니다.
이제 \( \phi \)를 스칼라 손실 함수라 하고, \( d(-) = \partial \phi / \partial (-) \)를 그래디언트의 표기법으로 사용합니다. 출력 그래디언트 \( dO \in \mathbb{R}^{N \times d} \)가 주어지면, 우리는 체인 룰에 따라 \( dQ \), \( dK \), \( dV \)를 다음과 같이 계산합니다:
\[ dV = P^T dO \in \mathbb{R}^{N \times d} \]
\[ dP = dO V^T \in \mathbb{R}^{N \times N} \]
\[ dS = d\text{softmax}(dP) \in \mathbb{R}^{N \times N} \]
\[ dQ = \alpha dS K \in \mathbb{R}^{N \times d} \]
\[ dK = \alpha dS^T Q \in \mathbb{R}^{N \times d} \]
여기서 \( d\text{s} = (\text{diag}(p) - p p^T) d\text{p} \)는 \( p = \text{softmax}(s) \)의 함수로서 벡터 \( s \)에 대해 적용되며, \( d\text{softmax}(dP) \)는 이 공식을 행 단위로 적용한 것입니다. 마지막으로, 이 계산은 MHA의 역전파에서 헤드와 배치 수에 따라 다시 병렬로 수행됩니다.
1. 우리는 NVIDIA의 Hopper 아키텍처를 배경으로 결과를 설명합니다. 그러나 이 알고리즘은 비동기 실행과 저정밀도 기능이 충분히 강력한 모든 GPU 아키텍처에 대해 동작합니다.
2. 더 정확히 말하면, 헤드 차원이 64일 때 FlashAttention-3 FP8이 앞서 있으며, 헤드 차원이 128 및 256일 때는 인과적 마스킹이 없는 경우에 동등하며 인과적 마스킹이 있는 경우 뒤처집니다.
3. FlashAttention-3는 https://github.com/Dao-AILab/flash-attention 에서 이용할 수 있습니다.
2.2 GPU hardware characteristics and execution model
FlashAttention-3에 관련된 GPU의 실행 모델, 특히 NVIDIA Hopper 아키텍처를 중심으로 설명하고 있습니다.
### 메모리 계층 구조
GPU의 메모리는 용량이 대역폭에 반비례하는 데이터 로케일의 계층으로 구성됩니다 (표 1 참조). 글로벌 메모리(GMEM, HBM으로도 알려짐)는 모든 스트리밍 멀티프로세서(SM)가 접근할 수 있는 칩 외부의 DRAM입니다. GMEM의 데이터는 투명하게 온칩 L2 캐시에 캐시됩니다. 다음으로, 각 SM은 프로그래머가 관리하는 고도로 뱅크된 작은 온칩 캐시인 공유 메모리(SMEM)를 포함하고 있습니다. 마지막으로, 각 SM 내에는 레지스터 파일이 있습니다.
### 스레드 계층 구조
GPU의 프로그래밍 모델은 스레드라고 불리는 실행 유닛의 논리적 그룹을 중심으로 조직됩니다. 가장 세밀한 수준에서 가장 거친 수준으로, 스레드 계층 구조는 스레드, 워프(32개의 스레드), 워프그룹(4개의 인접한 워프), 스레드블록(즉, 협력적 스레드 배열 또는 CTA), Hopper의 경우 스레드블록 클러스터, 그리고 그리드로 구성됩니다.
이 두 계층 구조는 밀접하게 연관되어 있습니다. 같은 CTA 내의 스레드들은 같은 SM에 공동 스케줄되며, 같은 클러스터 내의 CTA들은 같은 GPC에 공동 스케줄됩니다. SMEM은 CTA 내의 모든 스레드가 직접 접근할 수 있으며, 각 스레드는 자신에게만 비공개된 최대 256개의 레지스터(RMEM)를 가집니다.
### NVIDIA Hopper H100 SXM5 GPU의 스레드-메모리 계층 구조 (표 1)
| 하드웨어 수준 | 병렬 에이전트 | 데이터 로케일 | 용량 및 대역폭 |
|---------------|--------------|--------------|----------------|
| 칩 | 그리드 | GMEM | 80 GiB @ 3.35 TB/s |
| GPC | 스레드블록 클러스터 | L2 | 50 MiB @ 12 TB/s |
| SM | 스레드블록 (CTA) | SMEM | SM당 228 KiB, GPU당 31 TB/s |
| 스레드 | 스레드 | RMEM | SM당 256 KiB |
### 비동기성과 워프 전문화
GPU는 동시성과 비동기성을 이용하여 메모리와 실행 지연을 숨기는 처리 장치입니다. GMEM과 SMEM 간의 비동기 메모리 복사를 위해, Hopper에는 전용 하드웨어 유닛인 Tensor Memory Accelerator(TMA)가 있습니다. 또한, Ampere와 같은 이전 아키텍처와 달리 Hopper의 Tensor Core는 워프그룹 전체에서 비동기적인 WGMMA 명령어로 노출되며, 공유 메모리에서 직접 입력을 가져올 수 있습니다.
하드웨어의 비동기 지원은 워프 전문화 커널을 가능하게 합니다. 여기서 CTA의 워프는 데이터 이동 또는 계산만 수행하는 생산자 또는 소비자 역할로 나뉩니다. 일반적으로 이는 컴파일러가 최적의 명령어 스케줄을 생성하는 능력을 향상시킵니다. 또한, Hopper는 setmaxnreg를 통해 워프그룹 간의 레지스터 동적 재할당을 지원하여, MMAs를 수행하는 워프는 TMA를 발행하는 워프보다 더 많은 RMEM을 얻을 수 있습니다.
### 저정밀도 수 포맷
현대 GPU는 저정밀도 계산을 가속화하기 위한 특수 하드웨어 유닛을 가지고 있습니다. 예를 들어, WGMMA 명령어는 FP8 Tensor Core를 대상으로 하여 FP16이나 BF16에 비해 SM당 2배의 처리량을 제공합니다.
그러나 FP8 WGMMA를 올바르게 호출하려면 피연산자의 배열 제약 조건을 이해해야 합니다. \( A \times B^T \) 행렬 곱셈 호출을 고려할 때, \( A \) 또는 \( B \) 피연산자가 외부 \( M \) 차원에서 연속적이면 mn-major, 내부 \( K \) 차원에서 연속적이면 k-major라고 합니다. FP16 WGMMA의 경우, SMEM의 피연산자는 mn-major와 k-major 형식 모두 허용되지만, FP8 WGMMA의 경우 k-major 형식만 지원됩니다. 또한, 어텐션과 같은 상황에서 하나의 커널에서 연속적인 GEMM을 결합하려면 FP32 누산기와 FP8 피연산자 배열이 충돌하는 문제가 발생합니다.
어텐션의 맥락에서 이러한 배열 제약은 FP8 알고리즘 설계에 몇 가지 수정이 필요함을 의미합니다. 이에 대해서는 § 3.3에서 설명합니다.
2.3 Standard Attention and Flash Attention
Dao et al. [17]을 따라, 표준 어텐션이 GPU에서 중간 행렬 S와 P를 HBM에 생성하는 어텐션 구현을 의미한다고 설명합니다. FlashAttention의 주요 아이디어는 이러한 비싼 중간 읽기/쓰기를 피하고 어텐션을 단일 커널로 융합하기 위해 소프트맥스 축소의 로컬 버전을 활용하는 것입니다. 로컬 소프트맥스는 알고리즘 1의 소비자 메인 루프에서 18-19줄과 O 블록의 재스케일링과 일치합니다. 이 절차가 실제로 O를 계산한다는 간단한 유도는 [15, §2.3.1]에서 찾을 수 있습니다.
3 FlashAttention-3: Algorithm
이 섹션에서는 FlashAttention-3 알고리즘을 설명합니다. 간단히 하기 위해, 우리는 전방 패스에 초점을 맞추며, 역방향 패스 알고리즘은 부록 B.1에서 설명합니다. 먼저, 워프 전문화를 원형 SMEM 버퍼와 통합하는 방법을 FlashAttention-2의 기본 알고리즘에 통합하는 방법을 설명합니다. 그 후, WGMMA의 비동기성을 활용하여 겹쳐진 GEMM-소프트맥스 2단계 파이프라인을 정의하는 방법을 설명합니다. 마지막으로, 블록 양자화 및 비동기 처리를 통해 레이아웃 일치 및 정확도를 개선하기 위한 FP8에 필요한 수정 사항을 설명합니다.
3.1 Producer-Consumer asynchrony through warp-specialization and pingpong scheduling

FlashAttention-3의 워프 전문화는 배치 크기, 헤드 수, 쿼리 시퀀스 길이에서 병렬 처리가 매우 용이합니다. 따라서, 타일 \( Q_i \)에 대한 연산을 수행하여 대응하는 출력 타일 \( O_i \)를 계산하는 알고리즘의 CTA 레벨 뷰를 제공하는 것으로 충분합니다. 설명을 단순화하기 위해, GEMM-소프트맥스 중첩이 없는 순환 SMEM 버퍼를 사용하는 워프 전문화 스키마를 먼저 설명합니다. 여기서 \( d \)는 헤드 차원, \( N \)은 시퀀스 길이이며, 쿼리 블록 크기 \( B_r \)을 고정하여 \( Q \)를 \( T_r = \lceil \frac{N}{B_r} \rceil \) 블록으로 나눕니다.
### 알고리즘 1의 Hopper 구현:
- **setmaxnreg**: (비)할당을 위해 사용
- **TMA**: \( Q_i \)와 \( \{K_j, V_j\} \) 로드를 위해 사용
- **WGMMA**: 소비자 메인 루프에서 GEMM을 실행, SS 또는 RS 접두사는 첫 번째 피연산자가 공유 메모리 또는 레지스터 파일에서 제공되는지를 나타냅니다.
- **비동기성**: TMA 로드는 다른 로드가 완료될 때까지 중단되지 않습니다. 생산자 메인 루프에서 첫 번째 \( s \) 반복 동안 버퍼가 채워지므로 대기 시간이 발생하지 않습니다.
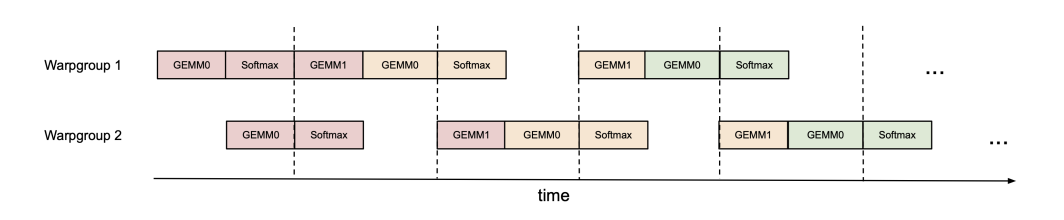
### 핑퐁 스케줄링:
- **비동기성 및 워프 전문화**: WGMMA와 TMA의 비동기적 특성과 워프 전문화로 인해 한 워프 그룹의 소프트맥스 계산과 다른 워프 그룹의 GEMM을 중첩할 수 있는 기회를 제공합니다.
- **하드웨어 특성**: 현대 하드웨어 가속기에서 비-행렬곱 연산의 처리량이 행렬곱 연산보다 훨씬 낮습니다. 예를 들어, H100 SXM5 GPU는 989 TFLOPS의 FP16 행렬곱 처리량을 가지지만, 지수 연산(소프트맥스에 필요)의 처리량은 3.9 TFLOPS에 불과합니다.
- **FP16 어텐션**: FP16에서 헤드 차원이 128인 경우, 지수 연산이 행렬곱보다 512배 많은 FLOPS를 필요로 하지만, 지수 연산의 처리량은 256배 낮아 행렬곱에 비해 주기당 50%의 시간을 차지할 수 있습니다. FP8에서는 행렬곱 처리량이 두 배가 되지만 지수 연산의 처리량은 그대로입니다.
- **이상적 스케줄링**: 행렬곱이 수행되는 동안 지수 계산이 스케줄되도록 하려면 동기화 장벽(bar.sync 명령어)을 사용하여 워프 그룹 1의 GEMM(현재 반복의 PV와 다음 반복의 QK>)이 워프 그룹 2의 GEMM 전에 스케줄되도록 합니다. 결과적으로 워프 그룹 1의 소프트맥스는 워프 그룹 2가 GEMM을 수행하는 동안 스케줄됩니다. 그런 다음 역할이 바뀌어 워프 그룹 2가 소프트맥스를 수행하는 동안 워프 그룹 1이 GEMM을 수행합니다("핑퐁" 스케줄링). 이는 그림 1에 설명되어 있습니다. 실제로는 그림처럼 깔끔하지 않지만, 일반적으로 성능이 향상됩니다(예: FP16 전방 패스에서 헤드 차원 128과 시퀀스 길이 8192에 대해 570 TFLOPS에서 620-640 TFLOPS로 향상).
### 어텐션 변형:
- **멀티 쿼리 어텐션 및 그룹화된 쿼리 어텐션**: FlashAttention-2의 접근 방식을 따르며, HBM에서 K와 V를 중복하지 않도록 텐서 인덱싱을 조정합니다.
이 설명은 FlashAttention-3의 워프 전문화 및 핑퐁 스케줄링 기법의 중요성과 구현 방법을 이해하는 데 도움이 됩니다.
3.2 Intra-warpgroup overlapping GEMMs and softmax

심지어 하나의 워프 그룹 내에서도 소프트맥스의 일부 명령어와 GEMM의 일부 명령어를 중첩할 수 있습니다. 이를 위해 사용할 수 있는 한 가지 기술을 설명합니다.
### 주의 알고리즘 내의 순차적 의존성
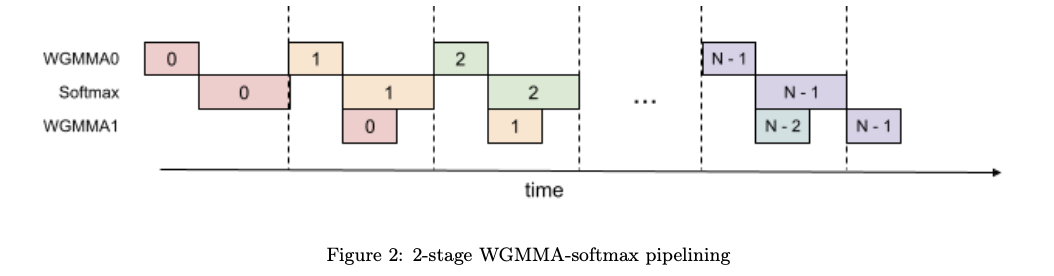
어텐션 알고리즘의 내부 루프(메인 루프) 내의 연산들은 단일 반복 내에서 병렬 처리를 방해하는 순차적 의존성을 가지고 있습니다. 예를 들어, (로컬) 소프트맥스(18~19줄)는 첫 번째 GEMM의 출력 \( S_{ij} \)에 의존하며, 두 번째 GEMM은 그 결과 \( P_{ij} \)를 피연산자로 사용합니다. 실제로 알고리즘 1의 17번과 21번 줄에 있는 대기 문은 소프트맥스와 GEMM의 실행을 직렬화합니다. 그러나 추가 버퍼를 레지스터에 사용하여 반복 간 파이프라인을 통해 이러한 의존성을 끊을 수 있습니다. 이 아이디어를 바탕으로 다음과 같은 2단계 GEMM-소프트맥스 파이프라인 알고리즘을 제안합니다:
### 알고리즘 2
이 알고리즘은 알고리즘 1의 소비자 경로를 대체하여 FP16 정밀도를 위한 전체 FlashAttention-3 알고리즘을 구성합니다. 높은 수준에서 WGMMA를 비동기 GEMM의 메토님으로 사용합니다. 메인 루프(8~16줄) 내에서, 반복 \( j \)의 두 번째 WGMMA 연산(11줄)은 다음 반복 \( j+1 \)의 소프트맥스 연산(13줄)과 중첩됩니다.
### 실질적인 고려 사항:
1. **컴파일러 재정렬**:
- 의사 코드는 이상적인 실행 순서를 나타내지만, 컴파일러(NVCC)는 최적화를 위해 종종 명령어를 재배치합니다.
- 이는 신중하게 설계된 WGMMA와 비-WGMMA 연산 파이프라인 시퀀스를 방해할 수 있으며, 예기치 않은 동작이나 성능 저하를 초래할 수 있습니다.
- SASS 코드를 분석한 결과, 컴파일러가 예상대로 중첩된 코드를 생성하는 것을 확인했습니다(부록 B.2 참조).
2. **레지스터 압박**:
- 최적의 성능을 유지하려면 레지스터 스필링(spilling)을 최소화해야 합니다.
- 그러나 2단계 파이프라인은 중간 결과를 저장하고 단계 간 컨텍스트를 유지하기 위해 추가 레지스터를 필요로 합니다.
- 구체적으로, 추가적인 \( S_{next} \)는 레지스터에 유지되어야 하며, 이는 스레드블록당 \( B_r \times B_c \times \text{sizeof(float)} \) 크기의 추가 레지스터 사용을 초래합니다.
- 이 증가된 레지스터 수요는 또한 레지스터를 많이 사용하는 더 큰 블록 크기(다른 일반적인 최적화)와 충돌할 수 있습니다.
- 실제로는 프로파일링 결과를 바탕으로 트레이드오프를 결정해야 합니다.
3. **3단계 파이프라인**:
- 위에서 설명한 2단계 알고리즘을 확장하여, 두 번째 WGMMA와 소프트맥스를 추가로 중첩시키는 3단계 변형을 제안합니다.
- 이 접근 방식은 더 높은 텐서 코어 활용도를 제공할 가능성이 있지만, 파이프라인에 추가적인 단계가 필요하여 레지스터가 더 많이 필요합니다.
- 이는 타일 크기와 파이프라인 깊이 간의 균형을 맞추는 것을 더 어렵게 만듭니다.
- 3단계 알고리즘에 대한 자세한 설명과 평가 결과는 부록 B.3에 있습니다.
이 설명을 통해 FlashAttention-3의 워프 전문화와 파이프라이닝 기법의 중요성과 구현 방법을 이해하는 데 도움이 됩니다.
3.3 Low-precision with FP8
FlashAttention-3의 FP8 정밀도 전방 패스를 계산할 때는 FP16과 달리 레이아웃 일치 측면에서 추가적인 어려움이 발생합니다.
### 레이아웃 변환 효율성:
1. **입력 텐서 레이아웃 문제**:
- Q, K, V 입력 텐서는 보통 헤드 차원에서 연속적으로 제공됩니다.
- 그러나 FP8 WGMMA의 두 번째 GEMM에서 V(또는 SMEM에 로드된 V 타일)가 시퀀스 길이 차원에서 연속적이어야 합니다.
- TMA 로드 자체는 연속적인 차원을 변경할 수 없기 때문에 두 가지 선택이 있습니다:
1. GMEM에서 V를 전처리 단계로 전치(transpose)하기.
2. SMEM에 로드한 후 V 타일을 커널 내에서 전치하기.
- **선택 1**: 전치 작업을 이전 단계의 에필로그(예: 로터리 임베딩)에 통합하거나, 독립적인 전처리 전치 커널을 호출하여 시퀀스 길이와 헤드 차원의 스트라이드를 교환할 수 있습니다.
- 그러나 이는 표준 라이브러리에 통합하기 어렵거나, 메모리 제약 상황(예: 추론)에서 낭비가 심합니다.
- **선택 2**: FP8 FlashAttention-3에서는 커널 내 전치를 선택합니다.
- LDSM(ldmatrix)와 STSM(stmatrix) 명령어를 활용하여 SMEM에서 RMEM으로, RMEM에서 SMEM으로 128바이트 단위로 전치할 수 있습니다.
- 첫 번째 반복 후, 이전 V와 현재 K 타일을 포함하는 두 WGMMA 동안 다음 V 타일의 전치가 실행되도록 배열할 수 있습니다.
2. **FP32 누산기 메모리 레이아웃 문제**:
- FP16과 달리, FP8 WGMMA의 FP32 누산기의 메모리 레이아웃이 피연산자 A의 레이아웃과 다릅니다.
- 이를 해결하기 위해 바이트 변환 명령어를 사용하여 첫 번째 WGMMA의 누산기를 두 번째 WGMMA에 적합한 형식으로 변환합니다.
- 구체적으로, 다음 순서로 변경합니다:
\[ \{d0, d1, d4, d5, d2, d3, d6, d7\} \]
- 이는 P 타일의 열을 재배열하는 작업이며, 커널 내 전치를 통해 V 타일의 행 배열도 일치시킵니다.
### 정확성: 블록 양자화 및 비동기 처리:
1. **FP8 형식의 문제**:
- FP8(e4m3) 형식은 3비트로 가수(mantissa)를, 4비트로 지수(exponent)를 저장하여 FP16/BF16보다 수치 오류가 큽니다.
- 대규모 모델은 대부분의 값보다 훨씬 큰 이상치(outlier) 값을 가지므로 양자화가 어려워집니다.
- 보통 per-tensor 스케일링을 사용하여 텐서 당 하나의 스칼라를 유지합니다(Q, K, V 각각에 대해 하나씩).
2. **수치 오류 감소를 위한 두 가지 기술**:
1. **블록 양자화**:
- 블록당 하나의 스칼라를 유지하여 Q, K, V 각각을 \(B_r \times d\) 또는 \(B_c \times d\) 크기의 블록으로 나누고 개별적으로 양자화합니다.
- 이 양자화는 주의 직전의 연산(예: 로터리 임베딩)과 결합할 수 있으며, 추가적인 속도 저하 없이 수행됩니다.
- FlashAttention-3 알고리즘은 자연스럽게 블록 단위로 작동하므로, 계산 비용 없이 각 S 블록을 스케일링할 수 있습니다.
2. **비동기 처리**:
- 이상치를 고르게 분포시키기 위해, Q와 K를 양자화하기 전에 무작위 직교 행렬 M으로 곱합니다.
- M은 직교 행렬이므로 \(MM^T = I\)이며, \( (QM)(KM)^T = QK^T \)이므로 주의 출력은 변경되지 않습니다.
- 이를 통해 각 QM 또는 KM 항목이 Q 또는 K 항목의 무작위 합이 되어 양자화 오류를 줄입니다.
- 실제로, Chee et al.과 Tseng et al.의 방식을 따라 M을 ±1의 무작위 대각 행렬과 하다마드 행렬의 곱으로 선택합니다. 이는 \(O(d \log d)\)의 시간 복잡도로 곱할 수 있으며, 추가 계산 비용 없이 로터리 임베딩과 결합할 수 있습니다.
이 두 가지 기술은 수치 오류를 최대 2.6배 줄이는 것을 검증했습니다.

4 Empirical Validation
우리는 FlashAttention-3를 구현하고 그 효율성과 정확성을 평가하기 위해 CUTLASS [57]의 원시 연산자들(WGMMA 및 TMA 추상화)을 사용했습니다.
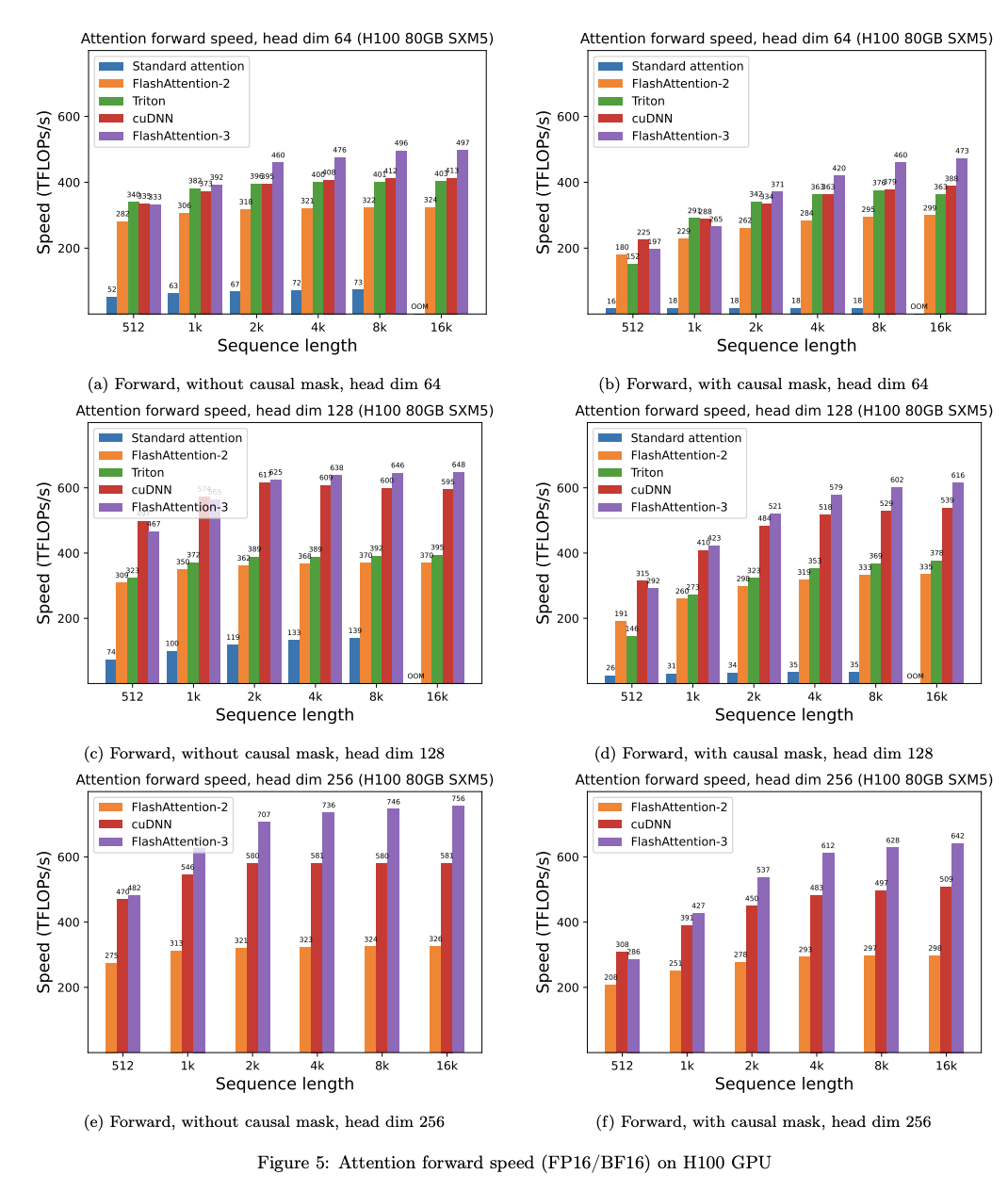
• 어텐션 벤치마킹: 우리는 FlashAttention-3의 실행 시간을 다양한 시퀀스 길이에 걸쳐 측정하고, 이를 PyTorch의 표준 구현, FlashAttention-2, Triton의 FlashAttention-2(H100 전용 명령어 사용), 그리고 H100 GPU에 최적화된 cuDNN의 FlashAttention-2 벤더 구현과 비교했습니다. FlashAttention-3가 FlashAttention-2보다 최대 2.0배, Triton의 FlashAttention-2보다 1.5배 더 빠르다는 것을 확인했습니다. FlashAttention-3는 H100 GPU에서 이론적인 최대 TFLOPs/s의 75%에 해당하는 최대 740 TFLOPs/s에 도달했습니다.
• 제거 연구: 우리는 워프 전문화와 GEMM-소프트맥스 파이프라이닝을 통한 알고리즘 개선이 FlashAttention-3의 속도 향상에 기여한다는 것을 확인했습니다.
• FP8 어텐션의 정확성: 블록 양자화와 비동기 처리가 FP8 FlashAttention-3의 수치 오류를 2.6배 감소시킨다는 것을 검증했습니다.
4.1 Benchmarking Attention
우리는 H100 80GB SXM5 GPU에서 다양한 설정(인과적 마스크 없음/있음, 헤드 차원 64 또는 128)으로 FP16 입력에 대한 다양한 어텐션 방법의 실행 시간을 측정했습니다. 결과는 그림 5와 그림 6에 보고되어 있으며, FlashAttention-3가 전방 패스에서 FlashAttention-2보다 약 1.5-2.0배, 역방향 패스에서는 1.5-1.75배 더 빠르다는 것을 보여줍니다. 표준 어텐션 구현과 비교할 때, FlashAttention-3는 최대 3-16배 더 빠를 수 있습니다. 중간 및 긴 시퀀스(1k 이상)에서는 FlashAttention-3가 H100 GPU에 최적화된 벤더의 라이브러리(cuDNN – 비공개 소스) 속도를 능가하기도 합니다.
### 벤치마크 설정:
- **시퀀스 길이:** 512, 1k, ..., 16k로 변경
- **배치 크기:** 전체 토큰 수가 16k가 되도록 설정
- **히든 차원:** 2048로 설정
- **헤드 차원:** 64, 128 또는 256으로 설정(즉, 32 헤드, 16 헤드, 또는 8 헤드)
- **전방 패스 FLOPs 계산:**
\[
4 \cdot \text{seqlen}^2 \cdot \text{head dimension} \cdot \text{number of heads}
\]
인과적 마스킹이 있는 경우, 약 절반의 항목만 계산되므로 이 수를 2로 나눕니다.
- **역방향 패스 FLOPs 계산:** 전방 패스 FLOPs에 2.5를 곱합니다(전방 패스에는 2개의 행렬 곱셈, 역방향 패스에는 5개의 행렬 곱셈이 재계산되기 때문).
우리는 또한 유사한 설정에서 전방 패스에 대해 FP8의 실행 시간을 측정했습니다. 헤드 차원 256에 대한 결과는 그림 7에 보고되었으며, 전체 결과는 부록 C.2에 있습니다.
4.2 Ablation Study: 2-Stage Pipelining Experiments
우리는 비인과적(non-causal) FP16 FlashAttention-3에 대해 2단계 WGMMA-소프트맥스 파이프라이닝과 워프 전문화를 제거한 실험을 수행했습니다. 고정된 매개변수 {배치, 시퀀스 길이, 헤드 수, 헤드 차원} = {4, 8448, 16, 128}로 실험을 진행했습니다. 표 2의 결과는 우리의 알고리즘 개선 사항(워프 전문화를 통한 비동기성과 GEMM 및 소프트맥스 간의 겹침)이 성능을 크게 향상시킨다는 것을 확인해 주었습니다. 성능이 570 TFLOPs에서 661 TFLOPs로 향상되었습니다.
4.3 Numerical Error Validation
FlashAttention에 대한 수치 오류에 관심이 증가함에 따라, 우리는 FlashAttention-2, FlashAttention-3, 그리고 표준 어텐션 구현을 FP64 참조 구현과 비교했습니다. 대규모 언어 모델(LLM)에서 발생할 수 있는 이상치 특성과 활성화를 시뮬레이션하기 위해, 우리는 Q, K, V의 항목을 다음과 같은 분포로 생성했습니다:
\[ N(0, 1) + N(0, 100) \cdot \text{Bernoulli}(0.001) \]
즉, 각 항목은 평균이 0이고 표준 편차가 1인 정규 분포를 따르지만, 0.1%의 항목에는 표준 편차가 10인 독립 항목을 추가로 더합니다. 그런 다음 표 3에서 루트 평균 제곱 오차(RMSE)를 측정했습니다. FP16에서는 FlashAttention-2와 FlashAttention-3 모두 중간 결과(소프트맥스)가 FP32로 유지되기 때문에 표준 구현에 비해 1.7배 낮은 RMSE를 달성했습니다. FP8에서 기본 어텐션은 per-tensor 스케일링을 사용하며, 행렬 곱셈 누산기는 FP32로, 중간 소프트맥스 결과는 FP16으로 유지됩니다. 블록 양자화와 비동기 처리를 통해, FP8의 FlashAttention-3는 이 기본값보다 2.6배 더 정확합니다.

5 Dicussion, Limitations, Conclusion
FlashAttention-3를 통해 새로운 프로그래밍 기술과 비동기성 및 저정밀도와 같은 하드웨어 기능이 어텐션의 효율성과 정확성에 극적인 영향을 미칠 수 있음을 입증했습니다. 우리는 FlashAttention-2와 비교하여 어텐션의 속도를 1.5-2.0배까지 향상시키고, 표준 per-tensor 양자화와 비교하여 FP8 수치 오류를 2.6배 줄일 수 있었습니다.
하지만, 우리의 작업에는 다음과 같은 몇 가지 한계가 있으며, 이는 향후에 해결하고자 합니다.
- 대규모 언어 모델(LLM) 추론 최적화
- FP8 커널에 지속적인 커널 디자인 통합
- 대규모 훈련에서 저정밀도 어텐션의 효과 이해
비록 이번 연구에서는 Hopper GPU에 중점을 두었지만, 여기서 개발된 기술이 다른 하드웨어 가속기에도 적용될 것이라고 기대합니다. 우리는 더 빠르고 정확한 어텐션과 같은 원시 기능이 긴 문맥 작업에서 새로운 응용 프로그램을 여는 데 도움이 되기를 바랍니다.




댓글