해당 내용은 Udemy의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의를 공부한 내용입니다. 내용을 그대로 번역하기보다는, 제가 이해하기 쉬운 대로 수정한 부분들이 있습니다.
⚠️ 영어 독해가 많이 부족합니다. 틀린 내용이 있으면 알려주시면 감사하겠습니다.
이번 강의에서는 고가용성 셋업에서의 ETCD에 관해 얘기할 것입니다. 이 강의는 다음 강의의 필수 강의 입니다. 다음 강의에서는 고가용성 모드의 쿠버네티스 구성에 관해 얘기할 것입니다. 그중 일부분은 HA 모드에서 구성과 관련이 있습니다. 이번 시간에는 HA 모드에 대해 알아보겠습니다. 이 과정의 시작에서 ETCD를 잠깐 보았습니다. 아주 빠르게 요약하고, 클러스터 구성에 더 초점을 맞추겠습니다.
ETCD
클러스터의 노드 개수와 래프트 프로토콜 등을 살펴보겠습니다. ETCD가 무엇인가요? 분산되고 신뢰할 수 있는 key value store로 간단하고 안전하며 빠릅니다.
Simple & Fast
전통적인 방법으로는 데이터를 이런 테이블에 정리하고 저장했습니다. 예를 들어 개인의 정보를 저장합니다.

키 밸류 스토어는 문서나 페이지의 형태로 정보를 저장합니다. 각 개인은 문서를 하나 갖고 그 개인에 관한 모든 정보가 해당 파일에 저장됩니다. 이 파일들은 어떤 형식이나 구조로든 존재할 수 있습니다. 한 파일의 변화는 다른 파일에 영향을 주지 않습니다. 이 경우, 근로 개인은 급여 필드가 있는 파일을 가질 수 있습니다. 단순한 키와 값을 저장하고 회수할 수 있는 반면, 데이터가 복잡해지면 일반적으로 JSON이나 YAML 같은 데이터 포맷을 사용하게 됩니다. 이것이 ETCD입니다.

distributed
ETCD가 분산되어있다는 것도 말씀드렸습니다. 이게 무슨 뜻일까요? 이번 강의에서는 이 부분에 집중할 것입니다. 단일 서버에 etcd가 있지만 데이터베이스라 중요한 데이터를 저장할 수 있습니다. 따라서 여러 서버에 걸쳐 데이터 저장소를 가질 수 있습니다.

이제 3개의 서버에 모두 etcd가 실행 중이고 데이터베이스의 동일한 복사본을 유지하고 있습니다. 하나를 잃어도 데이터는 두 개가 남습니다.
Consistent
모든 노드의 데이터가 일관적인지 어떻게 확인하죠? 어떤 인스턴스에서든 쓰고 데이터를 읽을 수 있습니다. ETCD는 데이터의 동일한 복사본이 모든 인스턴스에서 동시에 사용 가능하도록 보장합니다. 어떻게 가능할까요? 읽는 건 쉽습니다. 같은 데이터가 모든 노드에서 사용 가능하기 때문에, 어떤 노드에서든 쉽게 읽을 수 있습니다. 하지만 쓰기는 다릅니다. 2개의 쓰기 요청이 2개의 다른 인스턴스에서 온다면요? 어떤 것이 통과할까요?

예를 들어, 한 쪽 끝에는 John 다른 쪽 끝에는 Joe라는 이름을 쓰도록 했습니다. 물론 두 노드에 두 개의 다른 데이터를 둘 순 없습니다. ETCD는 어떤 인스턴스에도 쓸 수 있다고 했는데 100% 맞는 건 아니었습니다. ETCD는 노드마다 쓰기를 처리하지 않습니다. 대신 한 인스턴스만이 쓰기를 처리합니다.

내부에서 두 노드가 선출하는 리더는 하나 입니다. 전체 인스턴스에서 노드 하나는 리더가 되고 다른 노드는 팔로워가 됩니다. 쓰기가 리더 노드를 통해 들어오면 리더가 쓰기를 처리하고, 리더가 다른 노드들에게 데이터 복사본을 보내도록 합니다. 팔로워 노드를 통해 쓰기가 들어오면 팔로워 노드가 리더에게 쓰기를 전달하고 리더는 쓰기를 처리합니다. 쓰기가 처리되면 리더는 쓰기의 복사본이 클러스터의 다른 인스턴스로 분산되도록 보장합니다. 따라서 집단의 다른 멤버들로부터 리더가 동의를 얻어야만 완성된 것으로 간주됩니다.
Leader election - RAFT
그럼 리더 선출은 어떻게 할까요? 쓴 글이 모두에게 퍼지는 걸 어떻게 보장할까요? raft 프로토콜을 이용해 distributed consensus을 구현합니다. 세 노드 클러스터에서 어떻게 작동하는지 보겠습니다.

클러스터가 설정될 때, 3개의 노드에는 지도자가 선출되지 않았습니다. raft 알고리즘은 무작위로 타이머를 맞춰 신호를 보냅니다. 예를 들어 3명의 매니저에게 무작위 타이머가 작동하죠 타이머가 먼저 완료된 매니저가 다른 노드에게 리더가 될 권한을 투표합니다. 다른 매니저들의 투표로 요청에 대한 답변을 받으면 그 노드가 리더 역할을 맡습니다. 이제 리더로 선출됐으니 다른 마스터들에게 주기적으로 정기적으로 공지를 보내 자신이 계속 리더의 역할을 하고 있다고 알립니다.
다른 노드들이 리더로부터 어떤 시점에 알림을 받지 못할 수 있습니다. 리더가 다운되었거나 네트워크 연결이 끊겼기 때문일 수 있습니다. 그러면 노드들 사이에서 재선 프로세스를 시작합니다. 새 리더가 선출되는 것입니다.
이전 예제로 돌아가겠습니다. 쓰기가 들어오면 리더에 의해 처리되고, 클러스터 내 다른 노드로 복제됩니다. 쓰기는 클러스터의 다른 인스턴스로 복제됐을 때만 완료된 것으로 간주됩니다. ETCD 클러스터는 고가용성이라고 했습니다. 즉, 노드를 잃어도 기능은 할 것입니다.

가령, 새 쓰기가 들어왔는데 노드 하나가 응답하지 않는다고 칩시다. 따라서 리더가 클러스터에서 두 노드에만 쓸 수 있습니다. 이 때 다 쓴 건가요? 아니면 세 번째 노드가 올라올 때까지 기다려야 하나요? 아니면 실패한 걸까요? 이 때는 클러스터 내 대부분의 노드에 쓰기가 되었다면 완료로 간주합니다. 가령, 노드가 3개면 대다수는 2개 입니다. 데이터가 두 개의 노드에 작성될 수 있다면 쓰기 완료로 간주됩니다. 세 번째 노드가 온라인이 되면, 데이터도 거기에 복사됩니다.

여기서 대다수는 무엇인가요? quorum이라고 하는 게 더 적절하겠네요. quorum은 클러스터가 제대로 기능하고 성공적으로 쓰기우해 반드시 필요한 최소의 노드 수입니다. N이 3이면 2인 것입니다. 어떤 노드든 쿼럼은 노드를 2로 나누고 1을 더한 수입니다.

여기 1부터 7까지 클러스터의 쿼럼을 보여주는 표가 있습니다. 인스턴스1의 쿼럼은 1입니다. 그 말은 단일 노드 클러스터라면 이런 건 프로토콜이 적용이 안 된다는 것입니다. 그 노드를 잃으면 모든 게 사라집니다. 두 개를 보고 같은 공식을 적용하면 쿼럼은 2입니다. 클러스터에 인스턴스가 2개라도 대다수는 여전히 2입니다. 하나가 실패하면 쿼럼이 없어 쓰기도 할 수 없습니다. 인스턴스가 2개인 건 1개인 것과 같습니다. 쿼럼이 충족될 수 없는 어떤 실질적 가치도 제공하지 않습니다. 그래서 추가적인 클러스터에 최소 3개의 인스턴스를 갖도록 권장하는 것입니다. 그렇게 하면 적어도 한 노드의 결함 허용 내역을 제공합니다. 하나를 잃어도 쿼럼을 가질 수 있고 클러스터는 계속 기능할 것입니다.
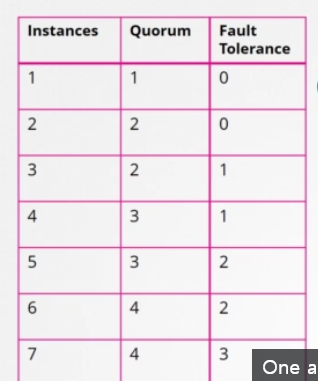
첫 번째 칼럼에서 두 번째 칼럼을 뺀 것을 fault tolerance 라고 합니다. 클러스터가 작동하는 동안 손실할 수 있는 노드의 수입니다. 노드가 1개에서 7개가 있습니다. 1개과 2개의 상황은 제외하고 3개부터 7개까지 뭘 고려해야 할까요? 보시다시피 3개와 4개의 fault tolerance는 1로 같습니다. 5개와 6개의 fault tolerance는 2로 같아요. 마스터 노드의 수를 정할 때는 테이블에서 강조했듯이 홀수를 선택해야 합니다. 3개, 5개, 7개처럼요. 노드 클러스터가 6개라고 치겠습니다. 예를 들어 네트워크의 교란으로 인해 망이 실패해 네트워크가 분할되었습니다. 1번 노드에는 4개, 다른 노드에는 2개가 있습니다. 이 경우 4개의 노드를 가진 그룹은 쿼럼이 있고 정상적으로 작동합니다. 하지만 네트워크가 다른 방법으로 파티션을 가지면 노드가 둘 사이에 동등하게 분배됩니다. 각 그룹은 3개의 노드만 가지게 되죠. 그런데 원래 노드가 6개였기 때문에 클러스터가 계속 살려면 쿼럼이 4개여야 합니다.
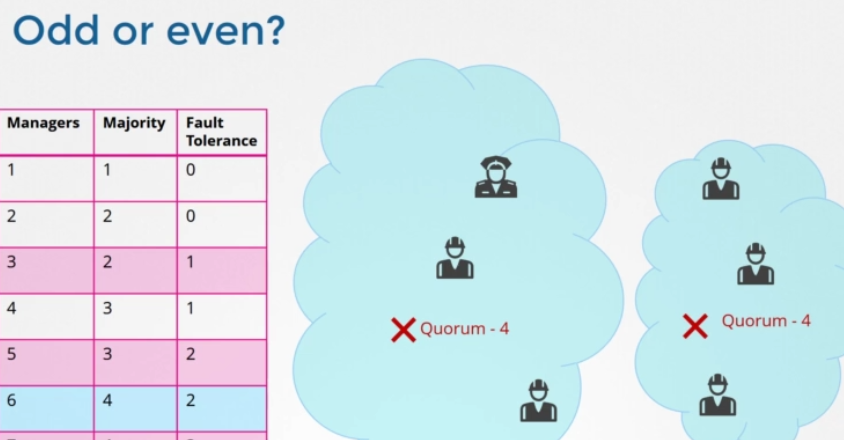
하지만 여기 그룹을 보시면 이 그룹들은 쿼럼에 부합하는 관리자가 네 명이 없습니다 따라서 실패한 클러스터로 끝나게 됩니다. 따라서 노드의 수가 짝수일 경우, 네트워크 세분화 중 클러스터 결함이 발생할 가능성이 있습니다. 원래 매니저 수가 홀수였다면 (예를 들어 7명) 네트워크 세그먼트화 이후 한 세그먼트화 네트워크에서 4명 다른 세그먼트화 네트워크에서 3명이 됩니다. 그래서 우리 클러스터는 여전히 관리자가 4명인 그룹에 살아있습니다. 4명의 쿼럼을 충족하면서요. 네트워크 세그먼트가 어떻든, 홀수 노드의 네트워크 세그먼트화 경우 클러스터가 생존할 확률이 더 높습니다. 따라서 짝수보다 홀수 노드가 선호됩니다. 5개가 6개보다 낫고, 노드가 5개 이상이면 충분합니다. 5개는 fault tolerance이 충분하니까요.
Getting Started
서버에 설치하려면 최신 지원되는 바이너리를 다운로드하고 그걸 압축해 필수 디렉터리 구조를 생성하고 추가로 생성된 인증서 파일 위로 복사하세요. TLS 인증서 섹션에서 이 인증서 생성 방법을 상세히 논의했습니다.
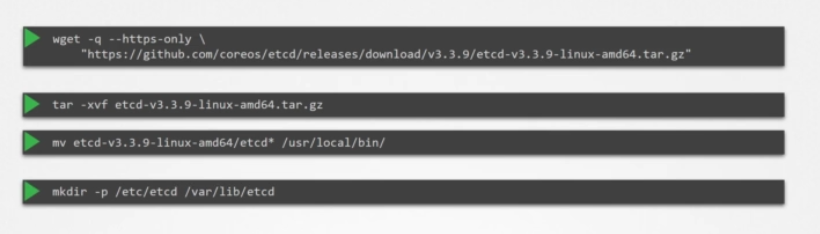
그런 다음 etcd 서비스를 구성합니다. 여기서 중요한 건 피어 정보를 전달하는 초기 클러스터 옵션입니다. 각 별도의 서비스가 그것을 통해 클러스터의 일부와 피어가 어디 있는지 알게 됩니다.

ETCDCTL
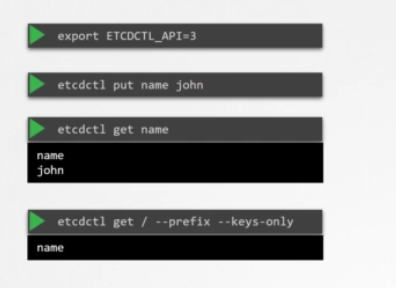
설치 및 환경 설정이 끝나면 etcdctl 유틸리티를 이용해 데이터를 저장 및 검색하세요. 이 etcdctl 유틸리티는 두 가지 API 버전이 있습니다. V2와 V3입니다. 그래서 버전마다 명령이 다릅니다. 버전 2는 디폴트값입니다. 하지만 버전 3을 사용할 것입니다. 환경 변수 ETCDTL_API를 3으로 설정하세요. 안 그러면 하위 명령이 안 먹힙니다. etcdctl put 명령을 실행하고 키를 이름과 값으로 지정하세요. 데이터를 검색하려면 키 이름이 적힌 etcdctl get 커맨드를 실행하고 존이라는 값을 반환합니다. 모든 키를 찾으려면 --keys-only를 입력하세요.
Number of Nodes
설계로 돌아가서 클러스터에 노드가 몇 개 있어야 하죠? HA 환경에서 보다시피 인스턴스 한두 개를 갖는 건 말이 안 됩니다. 노드 하나를 잃으면 쿼럼 없이 남겨지게 되고 클러스터가 비기능 상태가 됩니다. 따라서 HA에서 필요한 최소 노드는 3개입니다. 짝수보다 홀수가 좋은 이유도 얘기했습니다. 같은 수의 인스턴스를 갖는 것은 특정 네트워크 파티션 시나리오에서 쿼럼 없이 클러스터를 떠날 수 있습니다. 짝수 노드는 범위를 벗어납니다.

그럼 이제 3, 5, 7이나 그 위의 홀수만 남았습니다. 3개도 좋지만 내결함성(fault tolerance)이 높은 걸 원한다면 5개가 더 좋아요. 그 이상은 불필요합니다. 여러분의 환경, fault tolerance, 요구 사항,그리고 감당할 수 있는 비용을 고려할 때 이 목록에서 숫자 하나를 골라야 합니다. 우리 경우엔 3입니다.
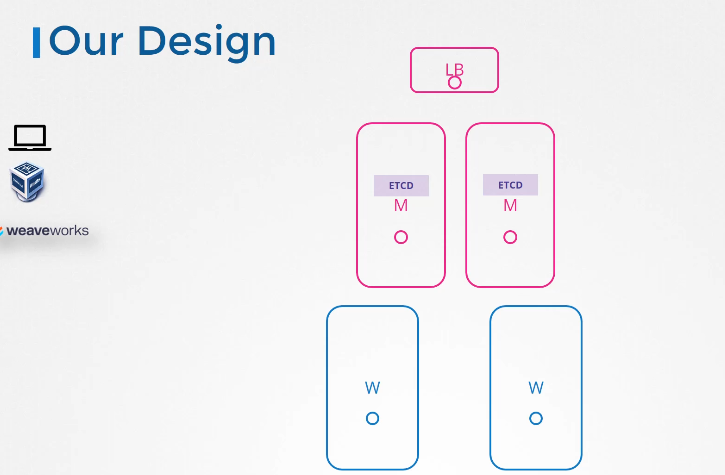
Our Design
지금 우리 설계는 어떤가요? HA는 내결함성을 위해 필요한 최소 노드 수가 3개입니다. 마스터 노드가 3개면 좋겠지만 노트북 용량에 한계가 있어서 2개로 하겠습니다. 하지만 다른 환경에서 셋업을 배포하고 충분한 용량을 확보한다면 3개를 사용하세요. 또한 스택된 topology를 선택했습니다. 마스터 노드 자체에 여러 서버들이 있는 형태입니다.
'MLOps > Doker & Kubernetes' 카테고리의 다른 글
| Udemy CKA 강의 정리 239: Introduction to Deployment with Kubeadm (0) | 2023.01.27 |
|---|---|
| Udemy CKA 강의 정리 238: Important Update: Kubernetes the Hard Way (1) | 2023.01.27 |
| Udemy CKA 강의 정리 236: Configure High Availability (0) | 2023.01.27 |
| Udemy CKA 강의 정리 235: Choosing Kubernetes Infrastructure (0) | 2023.01.27 |
| Udemy CKA 강의 정리 234: Design a Kubernetes Cluster (0) | 2023.01.27 |


댓글