해당 내용은 Udemy의 Certified Kubernetes Administrator (CKA) with Practice Tests 강의를 공부한 내용입니다. 내용을 그대로 번역하기보다는, 제가 이해하기 쉬운 대로 수정한 부분들이 있습니다.
⚠️ 영어 독해가 많이 부족합니다. 틀린 내용이 있으면 알려주시면 감사하겠습니다.
이 강의에서 우리는 쿠버네티스의 파드 네트워킹에 대해 논의하겠습니다. 지금까지 우리는 여러 개의 Kubernetes 마스터 및 워커 노드를 설정하고, 이들 노드 간의 네트워킹을 구성하여 이들은 모두 서로 연결할 수 있는 네트워크에 있습니다. 또한 Kubernetes controlplane 컴포넌트가 서로 도달할 수 있도록 방화벽 및 네트워크 보안 그룹이 올바르게 구성되었는지 확인했습니다. 우리가 또한 kube-apiserver, etcd 서버, kubelet, 등과 같은 모든 Kubernetes 제어 평면 컴포넌트를 설정했고 마침내 애플리케이션을 배포할 준비가 되었다고 가정합니다. 하지만 그러기 전에, 우리가 해결해야 할 것이 있습니다. 우리는 노드를 함께 연결하는 네트워크에 대해 이야기했지만, 클러스터가 작동하는 데 중요한 또 다른 네트워킹 계층인 파드 계층의 네트워킹에 대해서도 이야기해야 합니다.

우리의 Kubernetes 클러스터는 곧 많은 수의 파드와 서비스를 실행할 것입니다. 파드는 어떻게 처리됩니까? 그들은 어떻게 서로 의사소통을 할까요? 클러스터 내에서뿐만 아니라 클러스터 외부에서도 이러한 파드에서 실행되는 서비스에 액세스하려면 어떻게 해야 합니까? 이것들은 쿠버네티스가 여러분이 해결하기를 기대하는 과제들입니다. 오늘날, 쿠버네티스는 이것에 대한 기본 제공 솔루션을 제공하지 않습니다. 그것은 당신이 이러한 과제를 해결하는 네트워킹 솔루션을 구현하기를 기대합니다. 그러나 Kubernetes는 파드 네트워킹에 대한 요구 사항을 명확하게 제시했습니다. 그것들이 무엇인지 살펴봅시다.
Kubernetes는 모든 파드가 고유한 IP 주소를 가질 것으로 예상하며, 모든 파드는 해당 IP 주소를 사용하여 동일한 노드 내의 다른 모든 파드에 도달할 수 있습니다. 또한 모든 Pod는 동일한 IP 주소를 사용하여 다른 노드의 모든 Pod에 연결할 수 있습니다. IP 주소가 어떤 IP 주소이고 어떤 범위 또는 서브넷에 속하는지는 중요하지 않습니다. IP 주소를 자동으로 할당하고 노드의 파드와 다른 노드의 부품 간 연결을 설정하는 솔루션을 구현할 수 있다면 네트워크 rule을 구성할 필요가 없습니다. 그렇다면 이러한 요구사항을 해결하는 모델을 어떻게 구현할 수 있을까요?

이러한 기능을 제공하는 네트워킹 솔루션은 여러 가지가 있지만 네트워킹 개념, 라우팅, IP 주소 관리, 네임스페이스 및 CNI에 대해서는 이미 배웠습니다. 그래서 그 지식을 이용해서 먼저 우리 스스로 이 문제를 해결해 봅시다.

이를 통해 다른 솔루션의 작동 방식을 이해할 수 있습니다. 약간의 반복이 있다는 것을 알지만, 저는 리눅스의 일반 네트워크 네임스페이스에서 쿠버네티스에 이르기까지 동일한 개념과 접근 방식을 연관시키려고 노력하고 있습니다.
3개의 노드 클러스터가 있습니다. 어느 쪽이 주인이고 노동자인지는 중요하지 않다. 관리 또는 워크로드 목적으로 모두 파드를 실행합니다. 네트워킹에 관한 한, 우리는 그것들을 모두 동일하게 고려할 것이다. 그래서 먼저, 우리가 무엇을 할지 계획해 봅시다. 노드는 외부 네트워크의 일부이며 192.168.1. 시리즈의 IP 주소를 가집니다. 노드 1은 11, 노드 2는 12, 노드 3은 13이 할당됩니다. 다음 단계에서 컨테이너가 생성되면 Kubernetes는 컨테이너에 대한 네트워크 네임스페이스를 생성합니다. 이들 간의 통신을 가능하게 하기 위해, 우리는 이러한 네임스페이스를 네트워크에 연결한다. 하지만 어떤 네트워크일까요? 네임스페이스를 연결하기 위해 노드 내에 생성할 수 있는 브리지 네트워크에 대해 배웠습니다. 그래서 우리는 각 노드에 브리지 네트워크를 만들고 그들을 불러옵니다.


브리지 인터페이스 또는 네트워크에 IP 주소를 할당할 때입니다. 그런데 IP 주소가 뭐죠? 우리는 각 브리지 네트워크가 자체 서브넷에 있을 것이라고 결정한다. 개인 주소 범위(예: 10.244.1, 10.244.1 및 10.244.3)를 선택합니다. 다음으로 브리지 인터페이스의 IP 주소를 설정합니다.

나머지 단계는 새 컨테이너가 생성될 때마다 각 컨테이너에 대해 수행됩니다. 그래서 우리는 그것을 위한 스크립트를 작성합니다. 이제 복잡한 스크립팅을 알 필요가 없습니다. 이 파일은 앞으로 사용할 모든 커맨드가 포함된 파일이며, 앞으로 각 컨테이너에 대해 여러 번 실행할 수 있습니다.

컨테이너를 네트워크에 연결하려면 파이프 또는 가상 네트워크 케이블이 필요합니다. ip link add 커맨드를 사용하여 생성합니다. 옵션에 집중하지 마세요. 이전 강의에서 본 것과 비슷하니까요. 입력에 따라 다르다고 가정합니다. 그런 다음 ip link set 커맨드를 사용하여 한쪽 끝을 컨테이너에 부착하고 다른 쪽 끝을 브리지에 부착합니다. 그런 다음 ip addr 커맨드를 사용하여 IP 주소를 할당하고 default 게이트웨이에 route를 추가합니다. 하지만 어떤 IP를 추가해야 할까요? 우리는 그 정보를 스스로 관리하거나 일종의 데이터베이스에 저장합니다. 현재로서는 서브넷에서 사용 가능한 IP인 10.244.1.2라고 가정합니다. 우리는 다음 강의 중 하나에서 IP 주소 관리에 대해 자세히 논의합니다. 마지막으로, 우리는 인터페이스를 불러옵니다. 그런 다음 두 번째 컨테이너에 대해 동일한 스크립트를 실행하고 해당 컨테이너를 네트워크에 연결합니다. 이제 두 컨테이너가 서로 통신할 수 있습니다. 스크립트를 다른 노드에 복사하고 스크립트를 실행하여 IP 주소를 할당하고 해당 컨테이너를 자체 내부 네트워크에 연결합니다. 그래서 우리는 과제의 첫 부분을 해결했습니다. 파드들은 모두 고유한 IP 주소를 얻으며, 각자의 노드에서 서로 통신할 수 있다. 다음 부분은 다른 노드의 다른 파드에 도달할 수 있도록 하는 것입니다. 예를 들어 10.244.1.2에 있는 Pod(노드 1)가 Pod 10.244.2.2 또는 노드 2를 ping하려고 한다고 가정합니다.

현재 첫 번째 주소는 주소 10.244.2.2가 자신의 네트워크와 다른 네트워크에 있기 때문에 주소가 어디에 있는지 알지 못합니다. 따라서 default 게이트웨이로 설정되어 있으므로 노드의 IP로 라우팅됩니다. 10.244.2.2는 노드 2의 전용 네트워크이므로 노드 1도 알 수 없습니다. 노드 1의 라우팅 테이블에 경로를 추가하여 트래픽을 10.244.2.2로 라우팅합니다. 여기서 두 번째 노드의 IP는 192.168.1.12입니다. 경로가 추가되면 blue 파드가 핑을 통과할 수 있습니다.
마찬가지로, 우리는 내부의 각 네트워크에 대한 정보를 사용하여 모든 호스트에서 다른 모든 호스트로의 route를 구성합니다. 이 간단한 설정에서는 잘 작동하지만 default 네트워크 아키텍처가 복잡해질 때는 훨씬 더 많은 configuration이 필요합니다. 각 서버에서 route를 구성할 필요가 없는 대신 네트워크에 라우터가 있는 경우 라우터에서 route를 구성하고 모든 호스트가 이를 default 게이트웨이로 사용하도록 지정하는 것이 더 나은 솔루션입니다. 이렇게 하면 라우터의 라우팅 테이블에 있는 모든 네트워크에 대한 경로를 쉽게 관리할 수 있습니다. 이를 통해 각 노드에서 주소가 10.244.1.0/24인 개별 가상 네트워크가 이제 주소가 10.244.0.0/16인 단일 대규모 네트워크를 형성합니다.
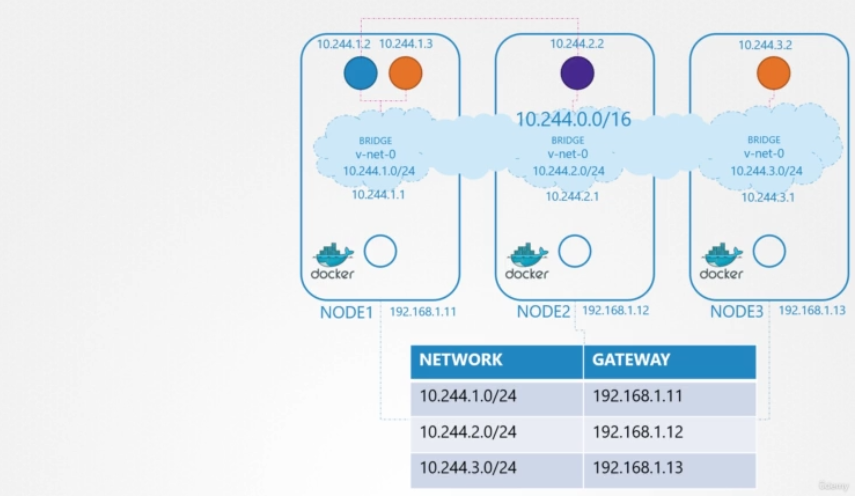
정리해봅시다. 브리지 네트워크와 라우팅 테이블을 사용하여 환경을 준비하기 위해 여러 가지 수동 단계를 수행했습니다. 그런 다음 각 컨테이너를 네트워크에 연결하는 데 필요한 단계를 수행하는 각 컨테이너에 대해 실행할 수 있는 스크립트를 작성하고 스크립트를 수동으로 실행했습니다. 물론, 매분 수천 개의 파드가 생성되는 대규모 환경에서와 같이, 우리는 그렇게 하고 싶지 않습니다. 그렇다면 쿠버네티스에서 파드이 생성될 때 어떻게 자동으로 스크립트를 실행할 수 있을까요? 거기서 중간자 역할을 하는 CNI가 나옵니다.

CNI는 컨테이너를 생성하는 즉시 스크립트를 호출하는 방법을 Kubernetes에 알려줍니다. 그리고 CNI는 우리에게 당신의 스크립트가 이렇게 보여야 한다고 말합니다. 그래서 우리는 CNI 기준에 맞게 스크립트를 조금 수정해야 합니다. 네트워크에 컨테이너를 추가하는 추가 섹션과 네트워크에서 컨테이너 인터페이스를 삭제하고 IP 주소를 해제하는 삭제 섹션이 있어야 합니다.
이렇게 스크립트가 준비되었습니다. 각 노드의 kubelet은 컨테이너 생성을 담당합니다. 컨테이너가 생성될 때마다 kubelet은 CNI configuration을 보고 실행 시 커맨드라인 arguments로 전달되며 스크립트의 이름을 식별합니다. 그런 다음 CNI의 bin 디렉토리를 검색하여 스크립트를 찾은 다음 add 커맨드과 컨테이너의 이름 및 네임스페이스 ID로 스크립트를 실행합니다. 그리고 나머지는 우리 스크립트가 알아서 합니다.
'MLOps > Doker & Kubernetes' 카테고리의 다른 글
| Udemy CKA 강의 정리 211: CNI weave (1) | 2023.01.25 |
|---|---|
| Udemy CKA 강의 정리 210: CNI in Kubernetes (0) | 2023.01.25 |
| Udemy CKA 강의 정리 206: Important Note about CNI and CKA Exam (0) | 2023.01.24 |
| Udemy CKA 강의 정리 205: Cluster Networking (0) | 2023.01.24 |
| Udemy CKA 강의 정리 204: Prerequisite - CNI (0) | 2023.01.24 |



댓글